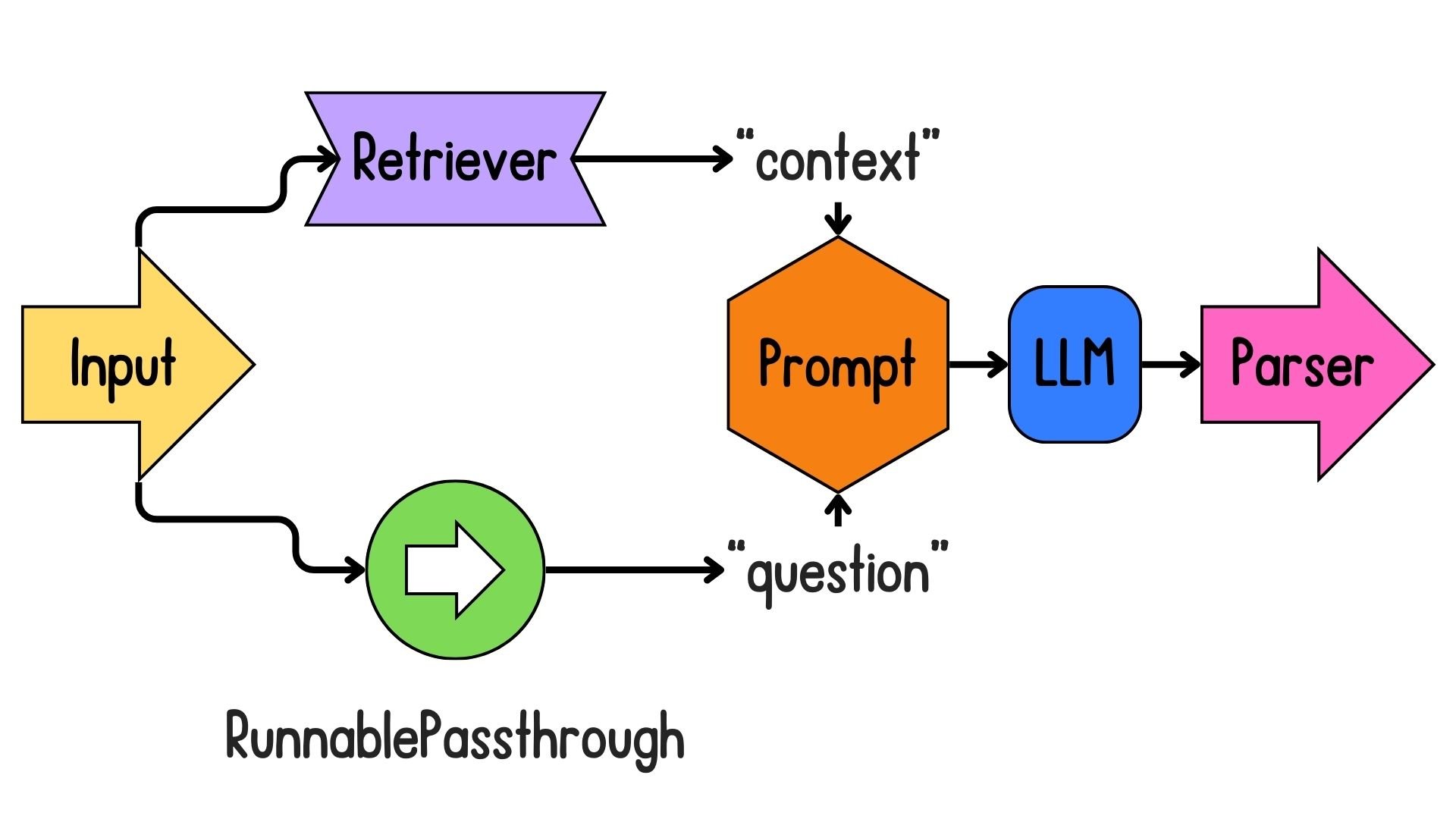
Building an LCEL retrieval chain
Retrieval Augmented Generation (RAG) with LangChain

Meri Nova
Machine Learning Engineer
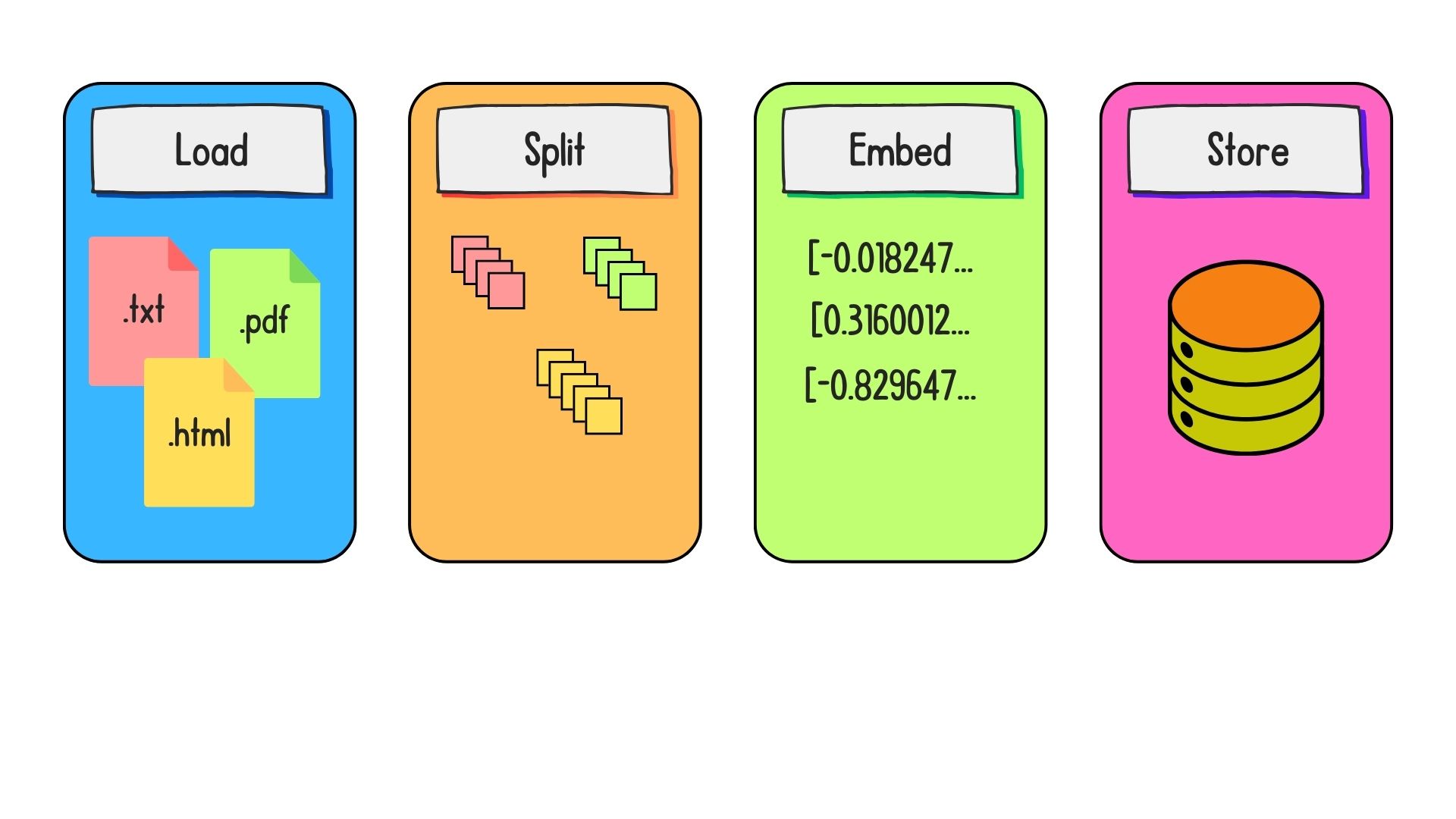
Preparing data for retrieval
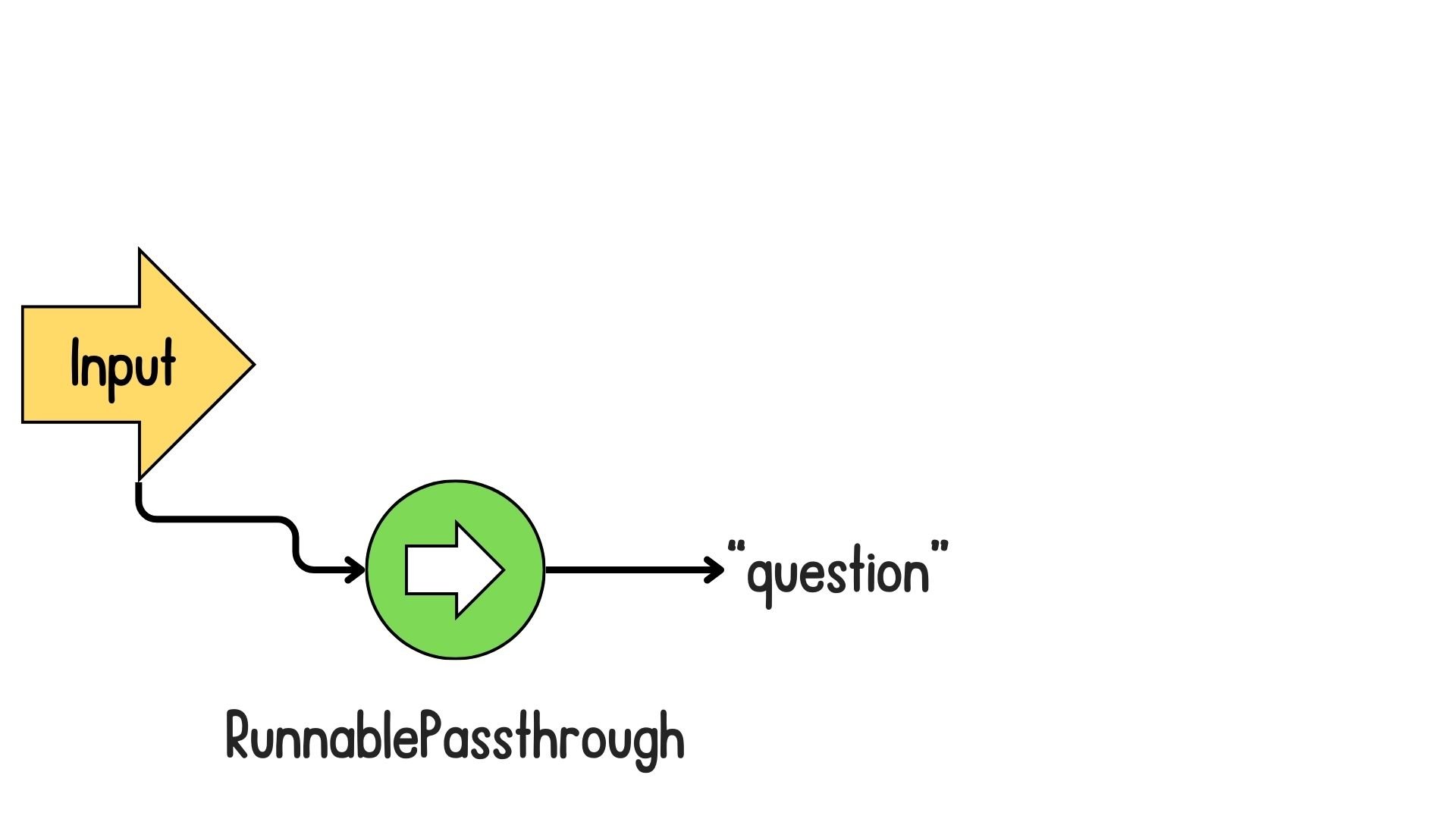
Introduction to LCEL for RAG

Introduction to LCEL for RAG
Introduction to LCEL for RAG
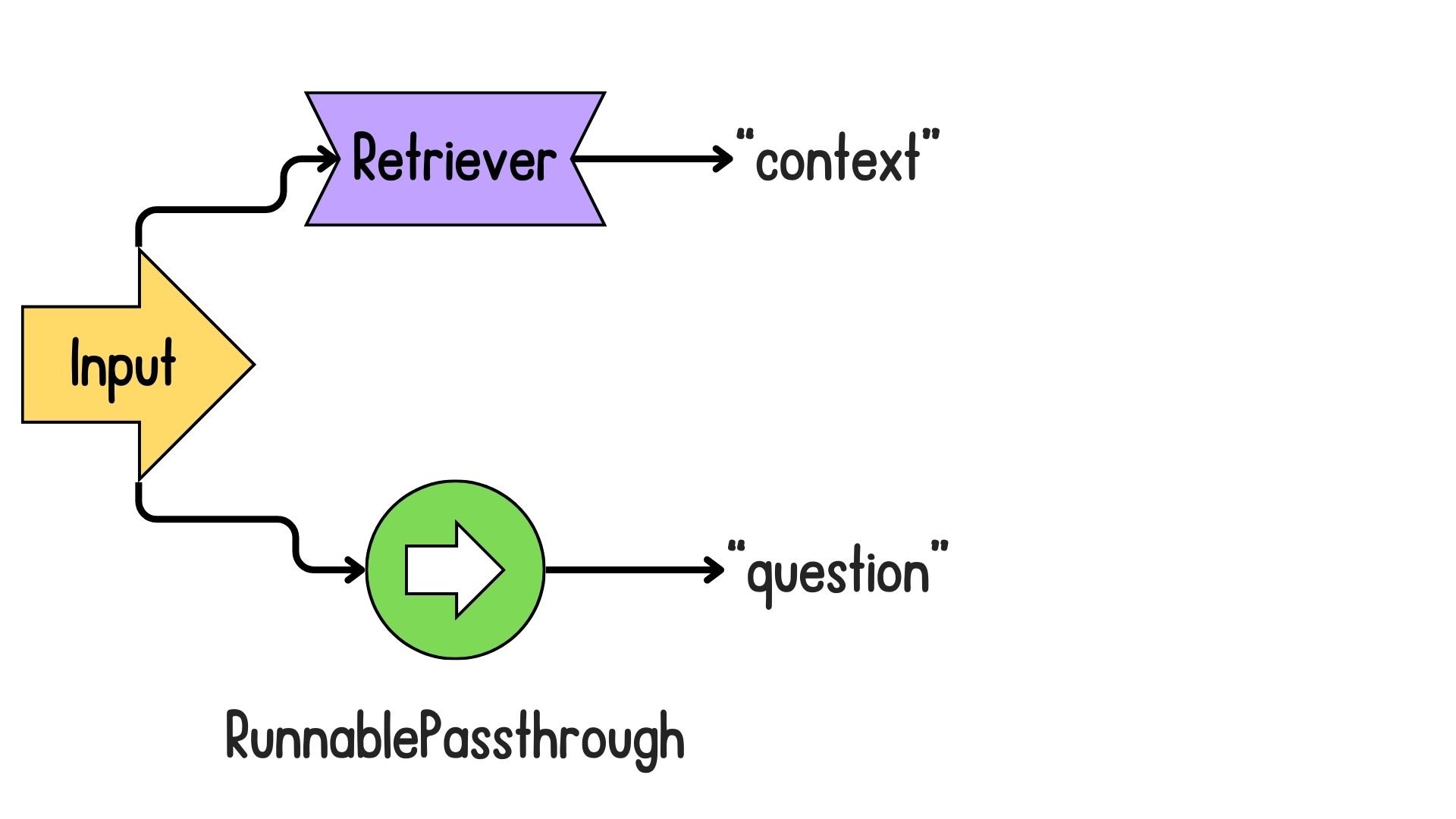
Introduction to LCEL for RAG
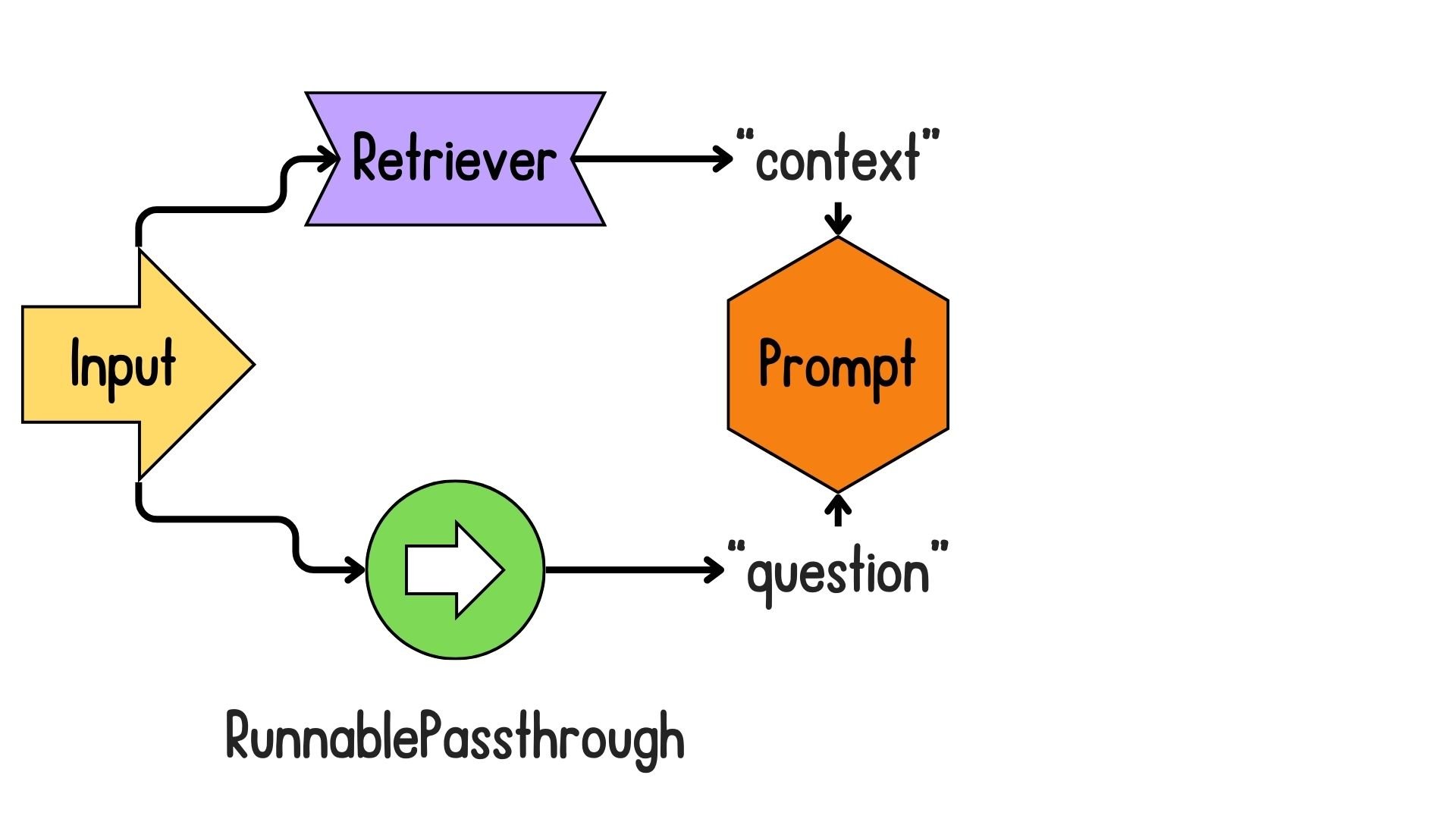
Introduction to LCEL for RAG
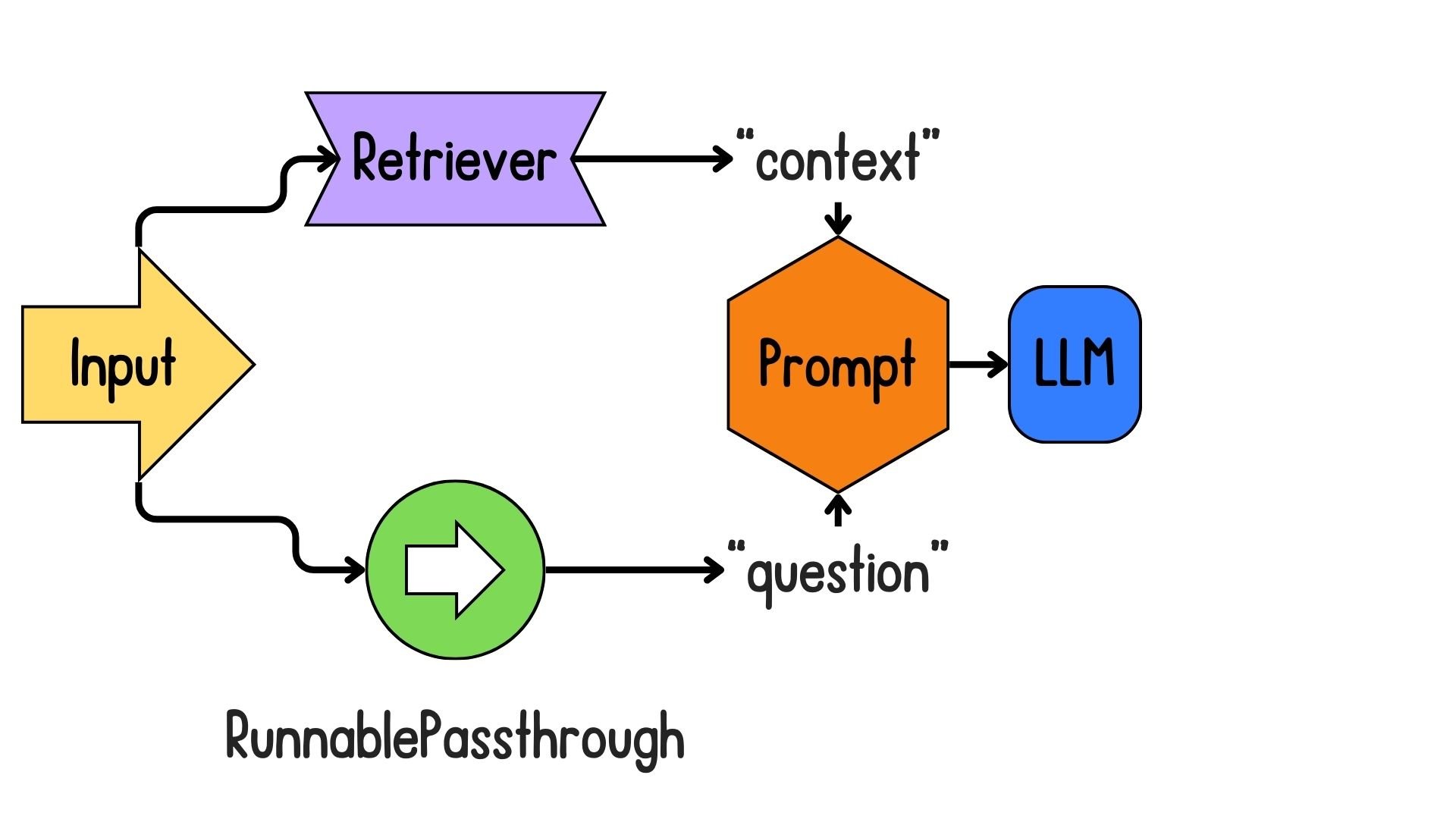
Introduction to LCEL for RAG