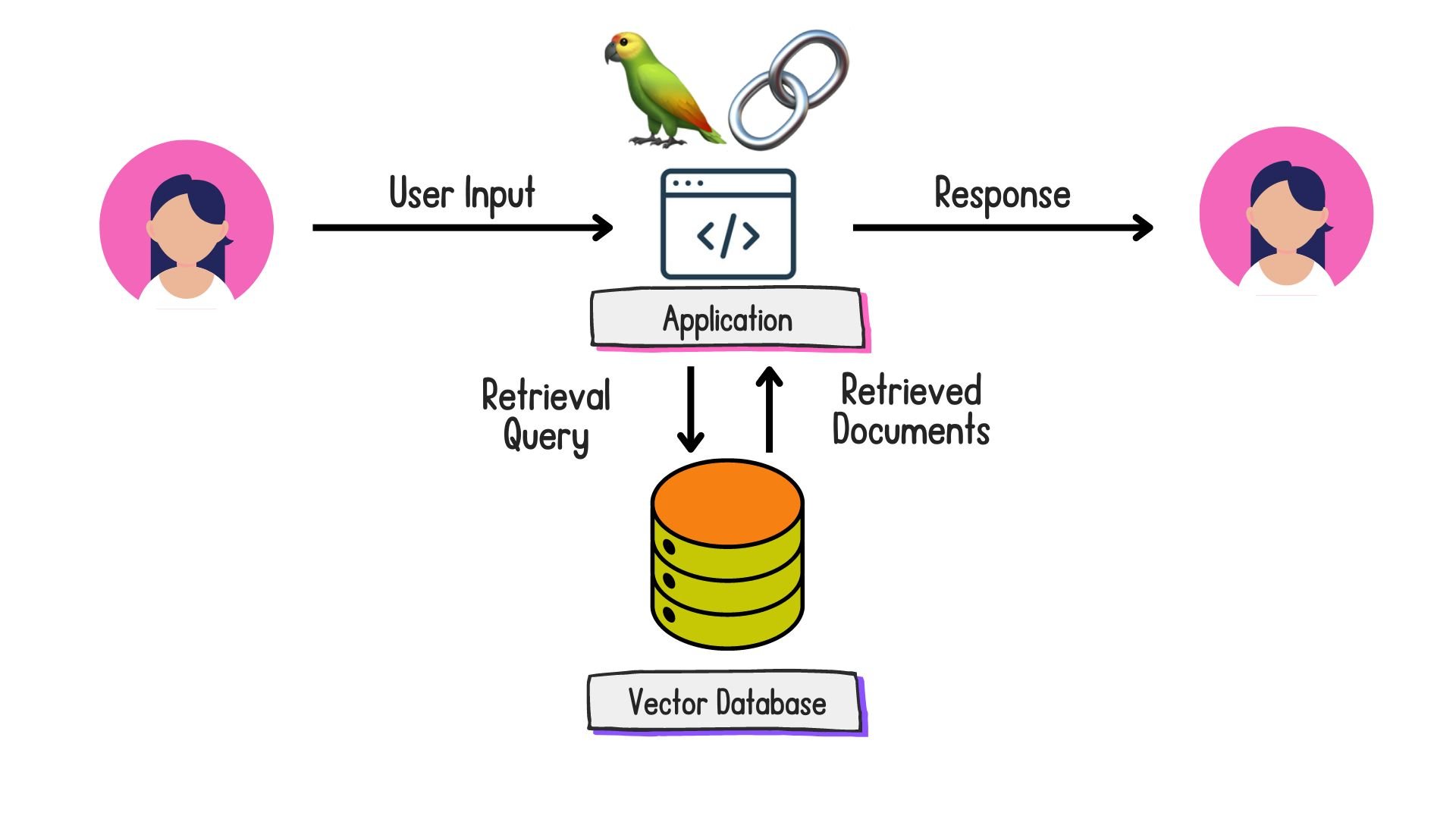
Optimizing document retrieval
Retrieval Augmented Generation (RAG) with LangChain

Meri Nova
Machine Learning Engineer
Putting the R in RAG...
Dense
Encode chunks as a single vector with non-zero components
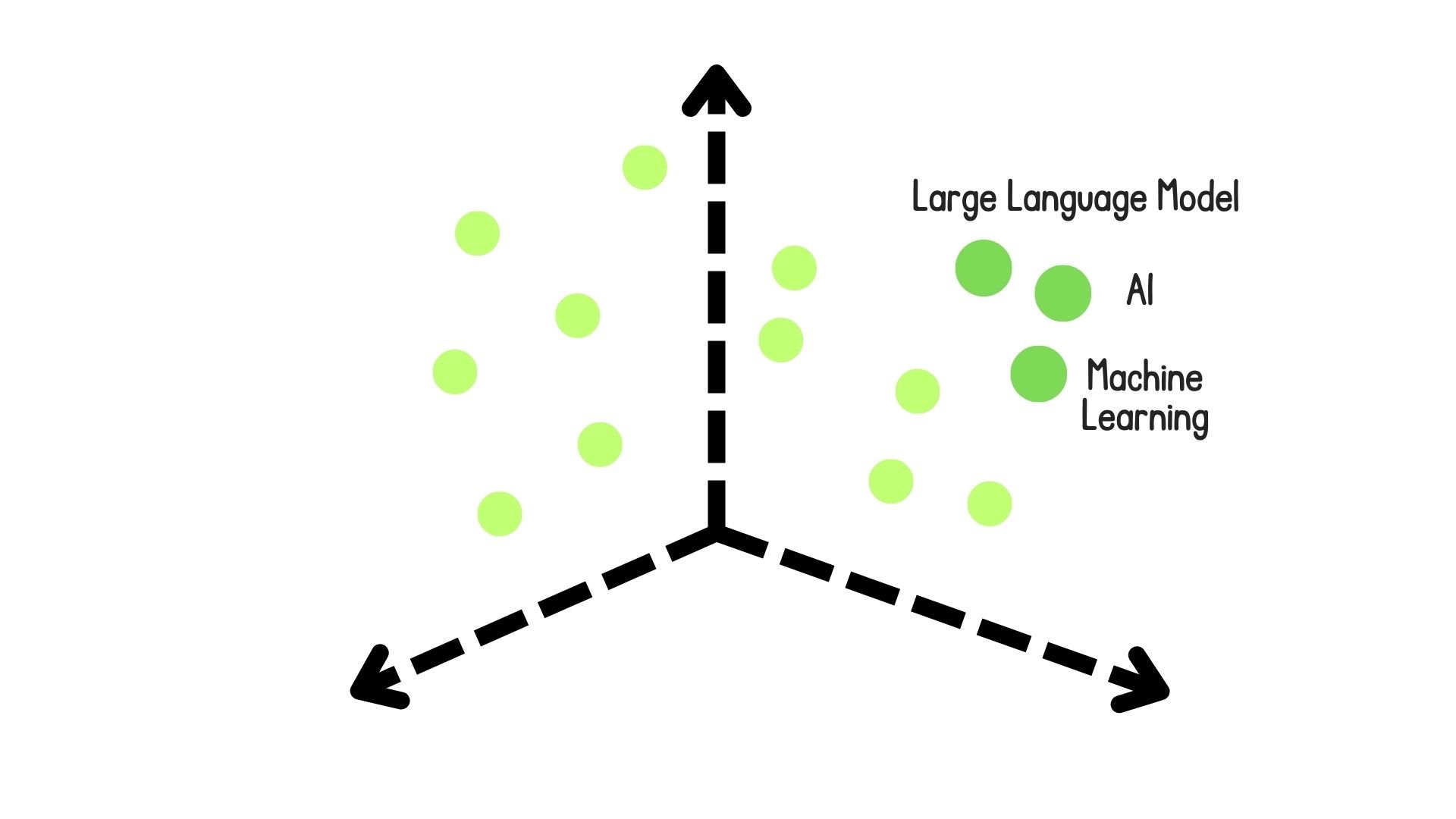
- Pros: Capturing semantic meaning
- Cons: Computationally expensive
Dense
Encode chunks as a single vector with non-zero components
- Pros: Capturing semantic meaning
- Cons: Computationally expensive
Sparse
Encode using word matching with mostly zero components
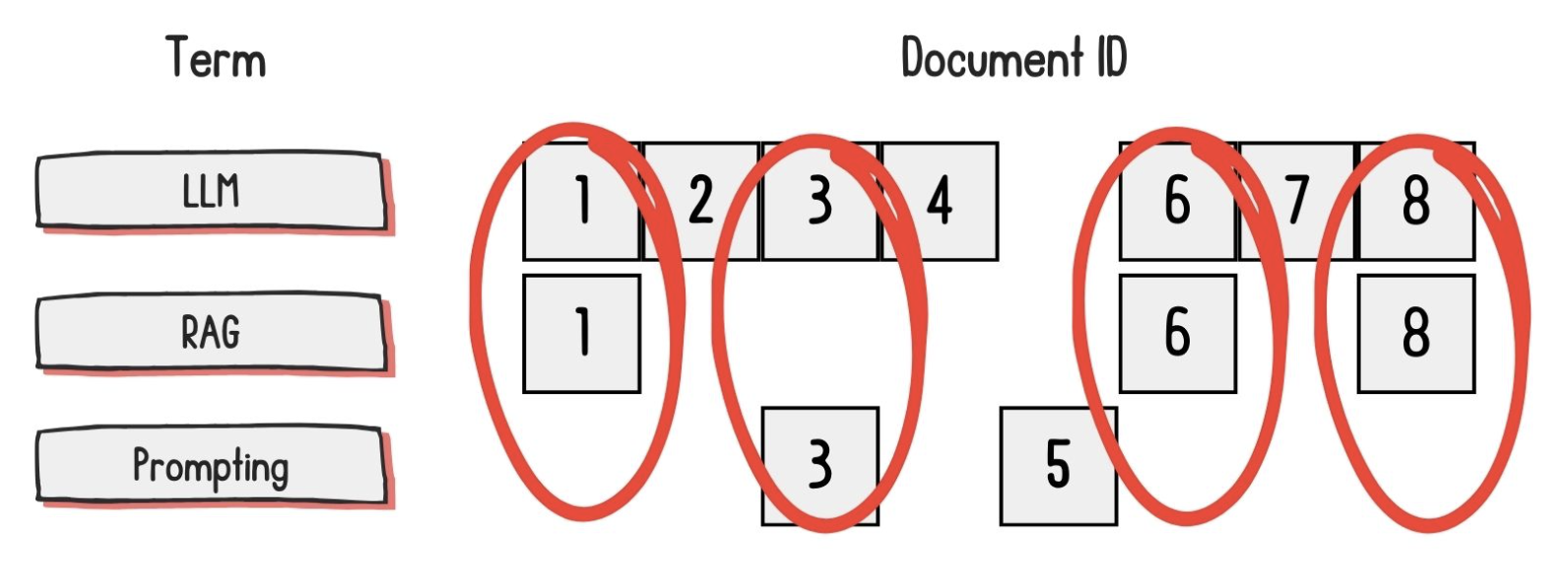
- Pros: Precise, explainable, rare-word handling
- Cons: Generalizability
Sparse retrieval methods
TF-IDF: Encodes documents using the words that make the document unique
BM25: Helps mitigate high-frequency words from saturating the encoding

