Introdução a RDDs do PySpark
Fundamentos de Big Data com PySpark

Upendra Devisetty
Science Analyst, CyVerse
O que é RDD?
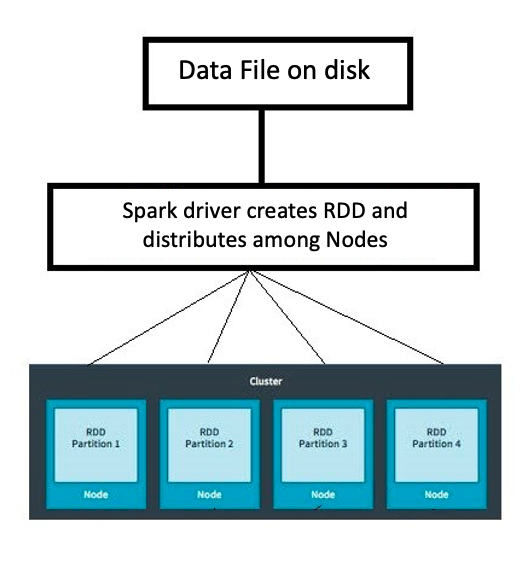
- RDD = Resilient Distributed Datasets (Conjuntos Distribuídos Resilientes)
Fundamentos de Big Data com PySpark
Upendra Devisetty
Science Analyst, CyVerse

