Classificação
Fundamentos de Big Data com PySpark

Upendra Devisetty
Science Analyst, CyVerse
Classificação com PySpark MLlib
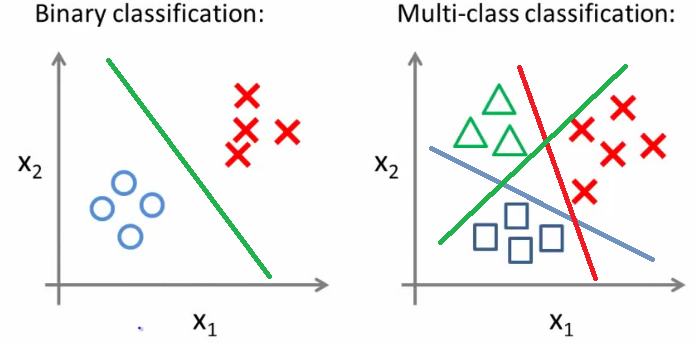
- Classificação é um algoritmo supervisionado que separa os dados em categorias
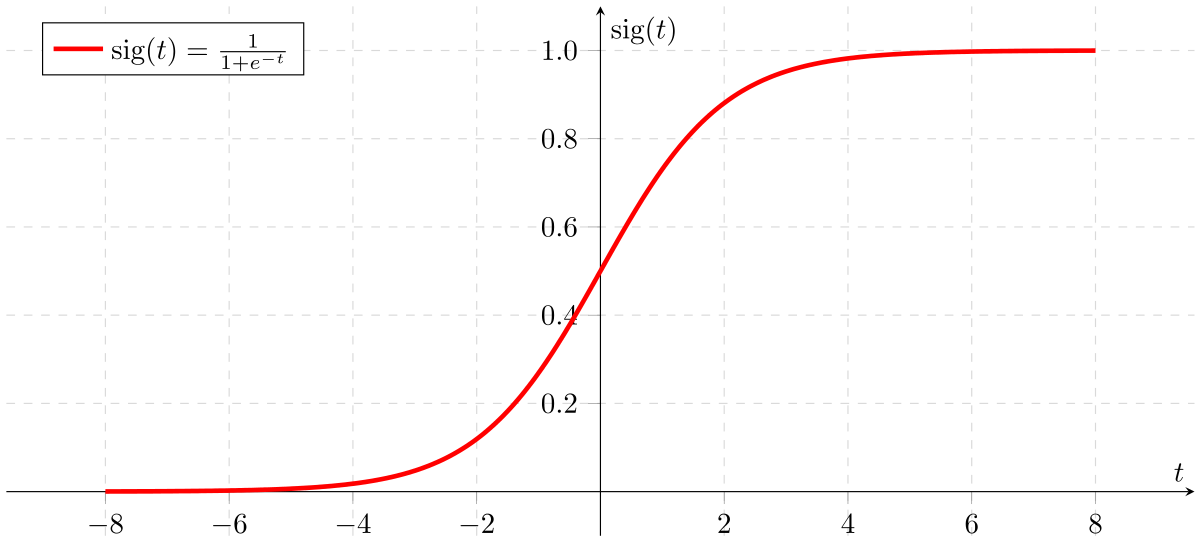
Introdução à Regressão Logística
- Regressão Logística prevê uma resposta binária a partir de variáveis