Amostragem superior e interpolação com .resample()
Manipulando dados de séries temporais em Python

Stefan Jansen
Founder & Lead Data Scientist at Applied Artificial Intelligence
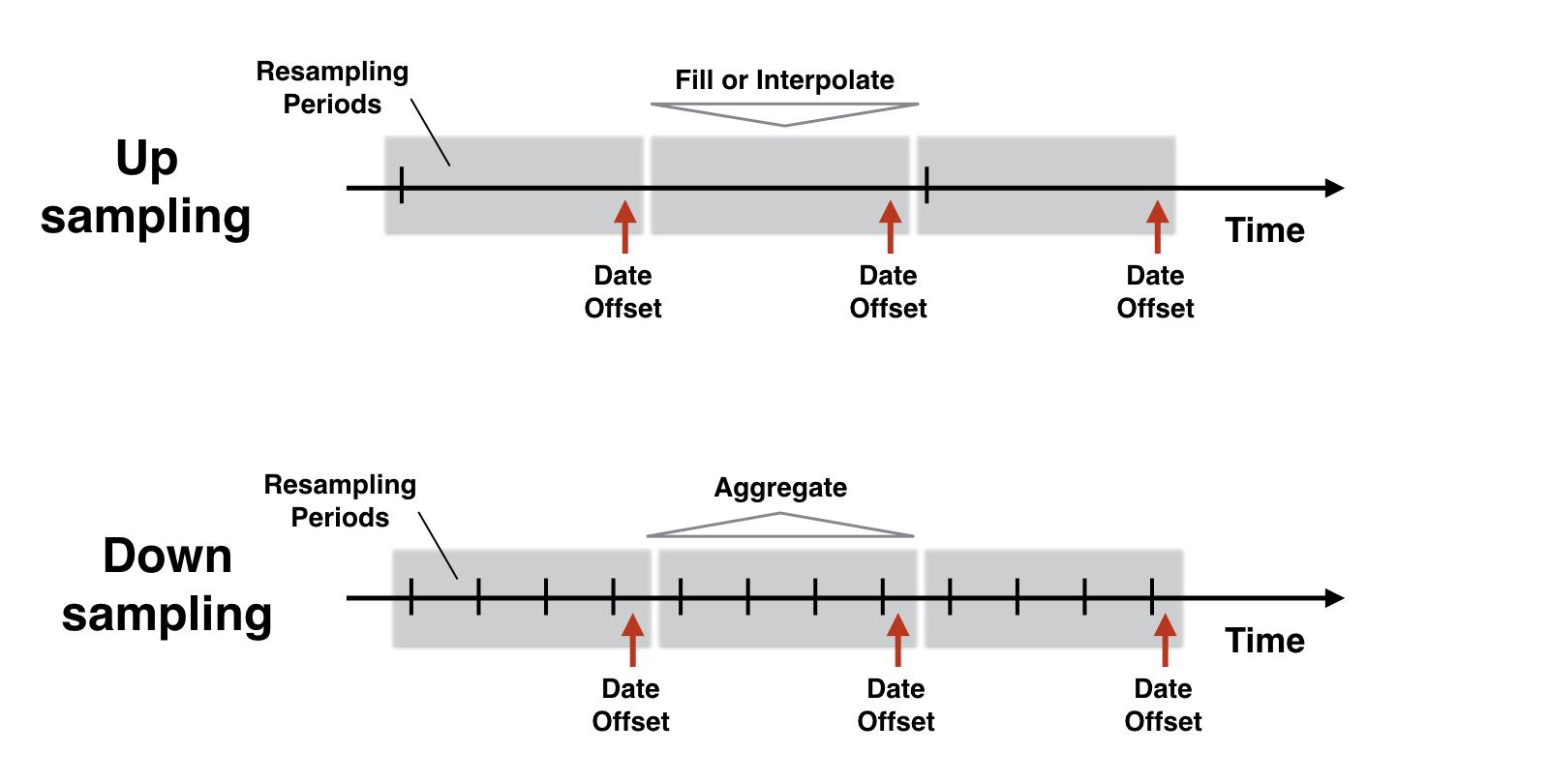
Lógica de reamostragem
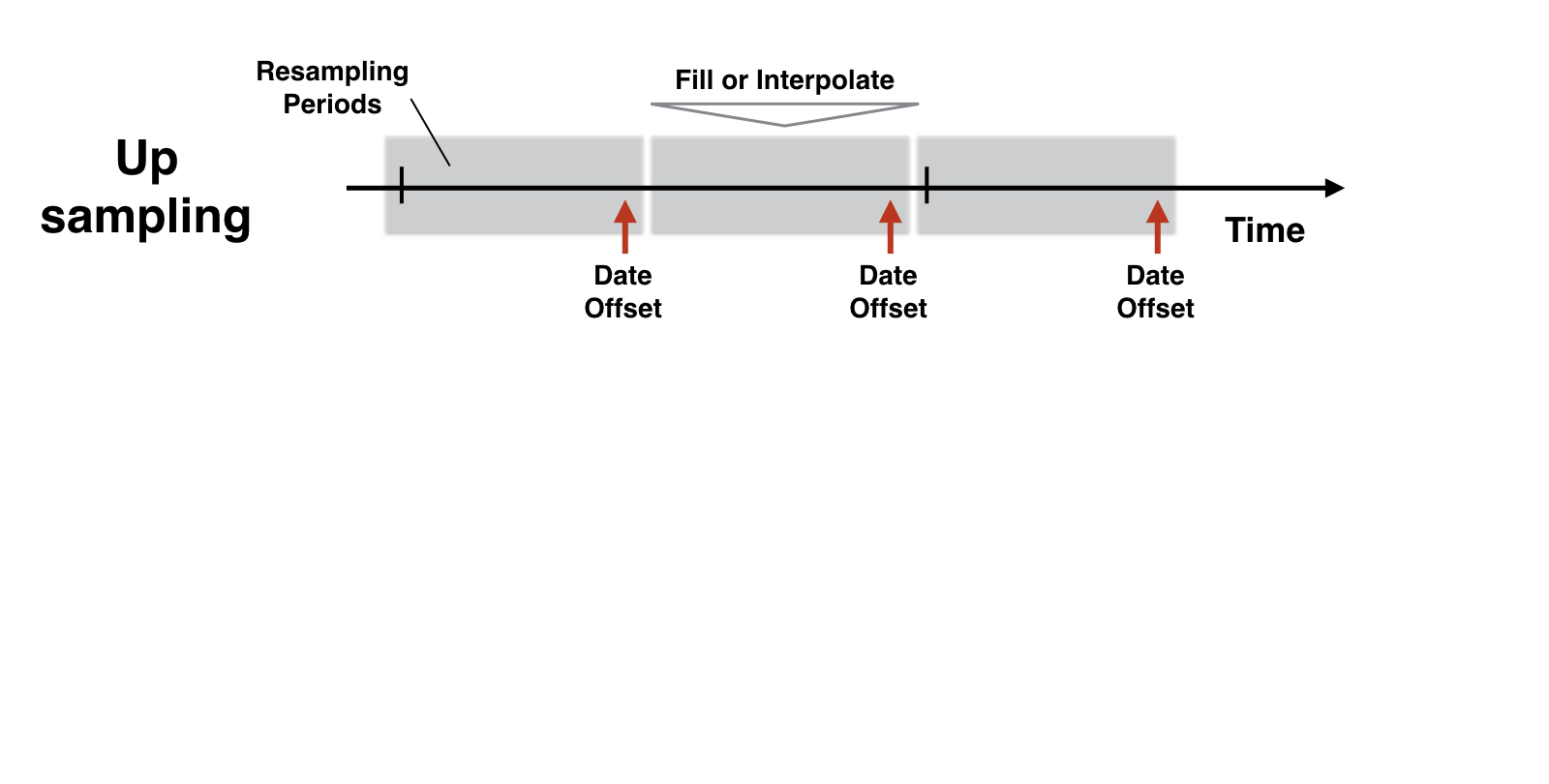
Lógica de reamostragem
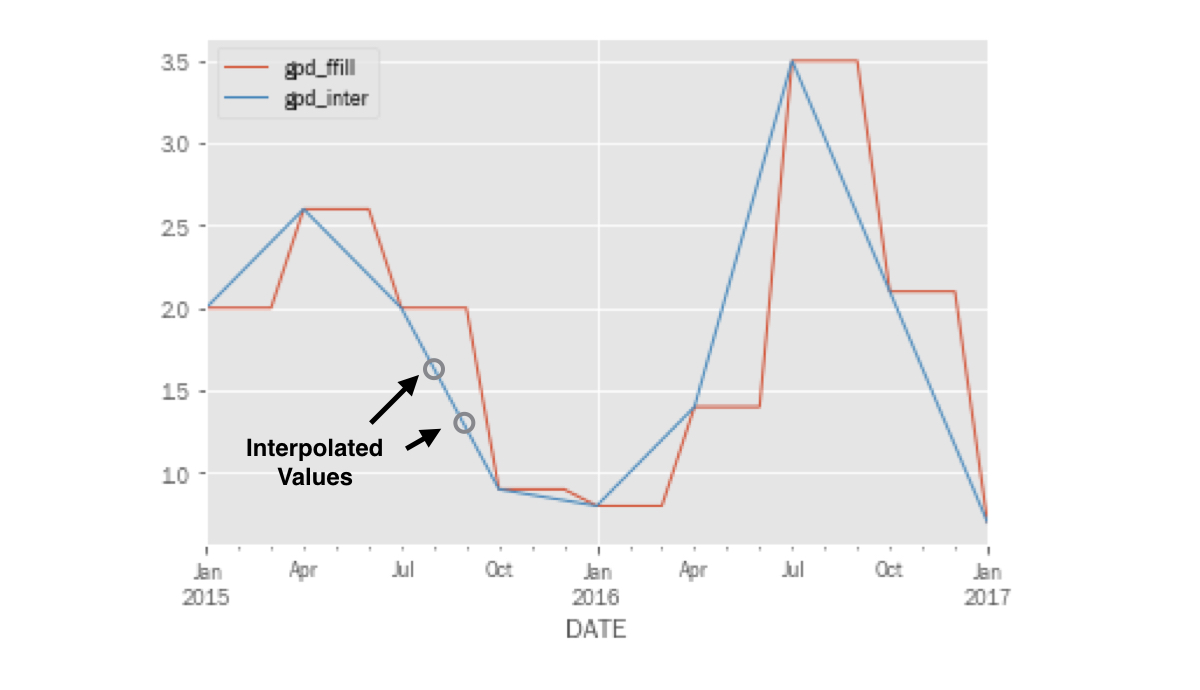
Plotar crescimento do PIB real interpolado
pd.concat([gdp_1, gdp_2], axis=1).loc['2015':].plot()
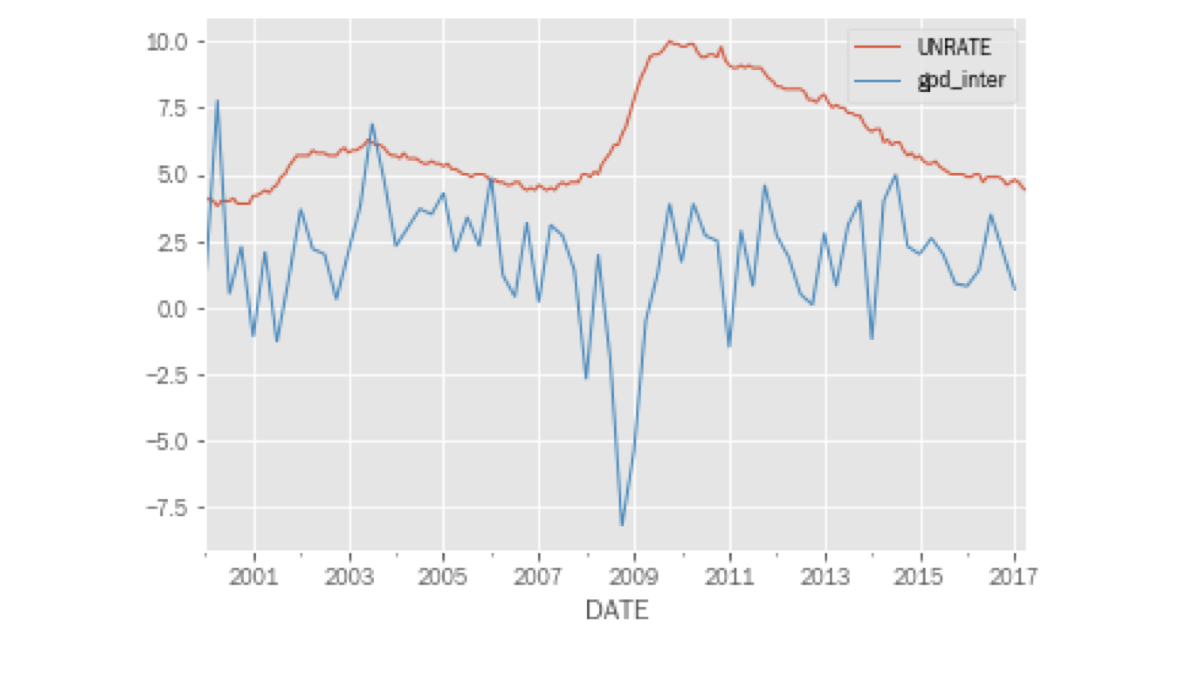
Combinar crescimento do PIB e desemprego
pd.concat([unrate, gdp_inter], axis=1).plot();