One-sample proportion tests
Hypothesis Testing in R

Richie Cotton
Data Evangelist at DataCamp
Calculating the p-value
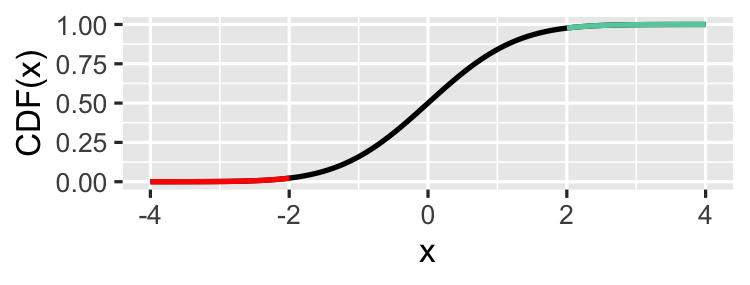 Left-tailed ("less than")
Left-tailed ("less than")
p_value <- pnorm(z_score)
Right-tailed ("greater than")
p_value <- pnorm(z_score, lower.tail = FALSE)

