Improving the features we use for classification
Machine Learning for Time Series Data in Python

Chris Holdgraf
Fellow, Berkeley Institute for Data Science
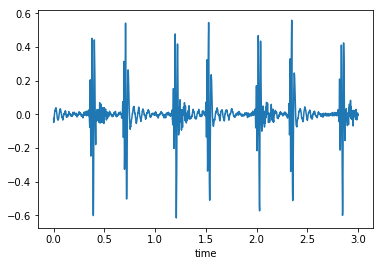
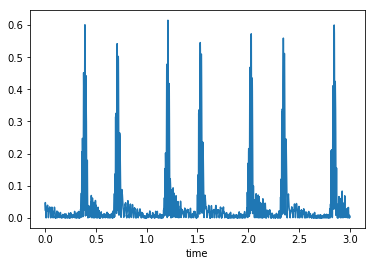
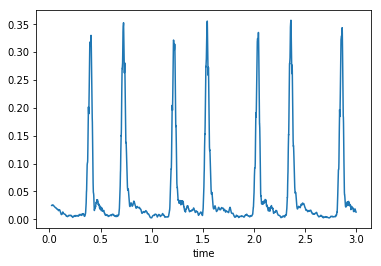
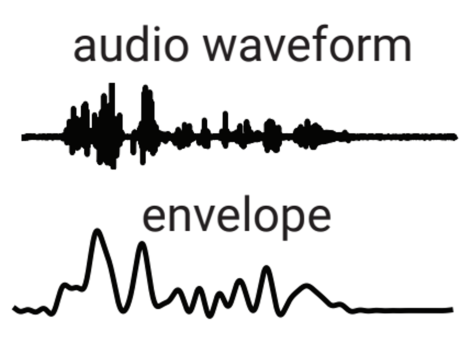
The auditory envelope
- Smooth the data to calculate the auditory envelope
- Related to the total amount of audio energy present at each moment of time
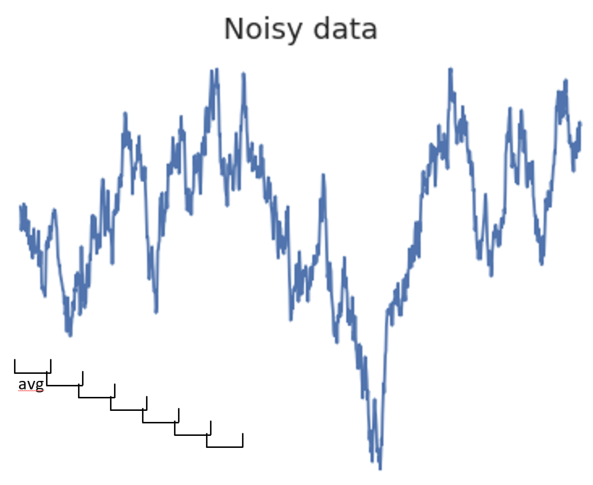
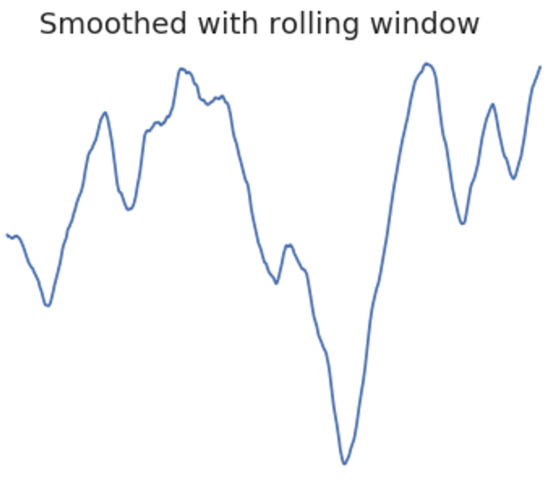
Smoothing your data