Bucketing & Engineering
Machine Learning with PySpark

Andrew Collier
Data Scientist, Fathom Data
Bucketing

Bucketing heights
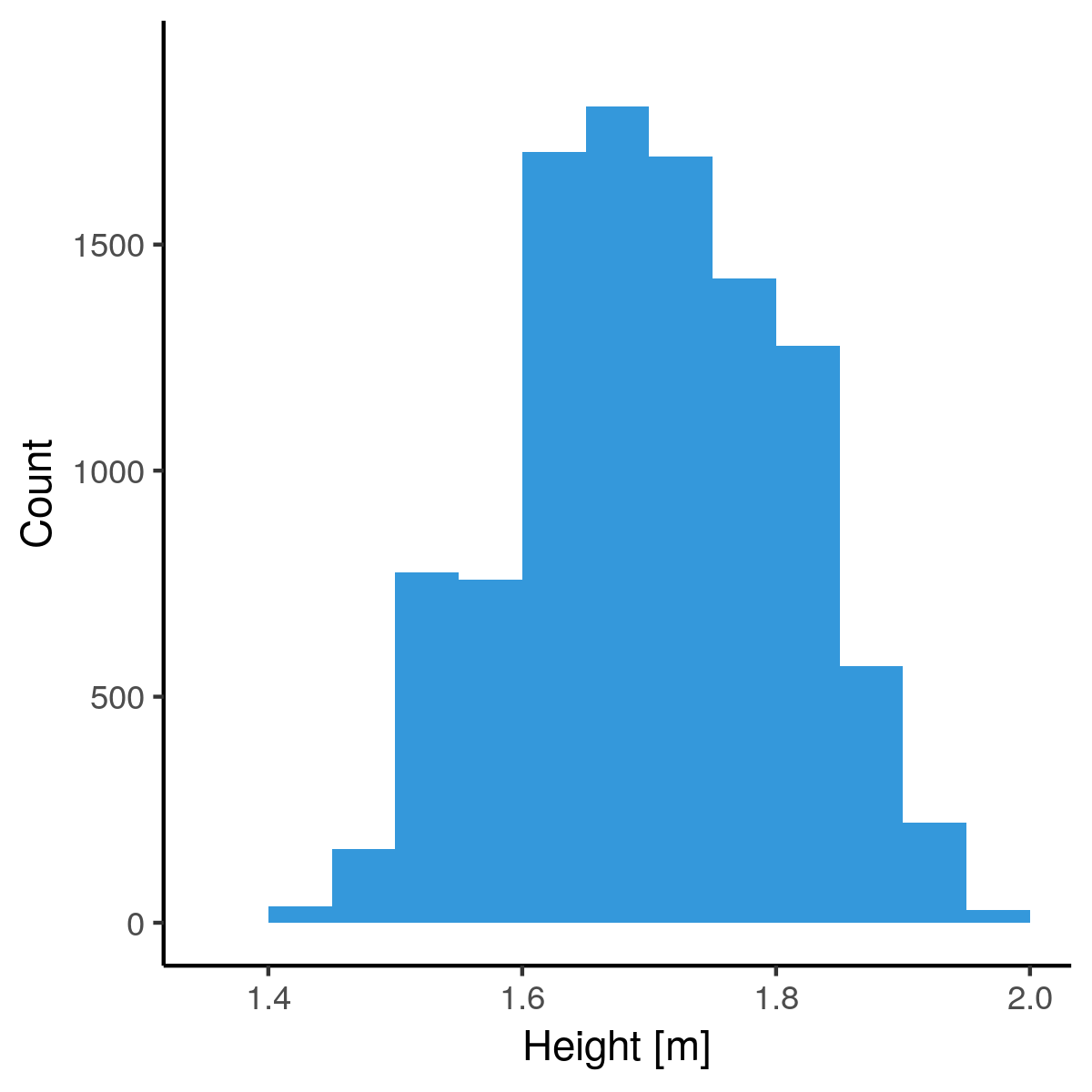
Bucketing heights
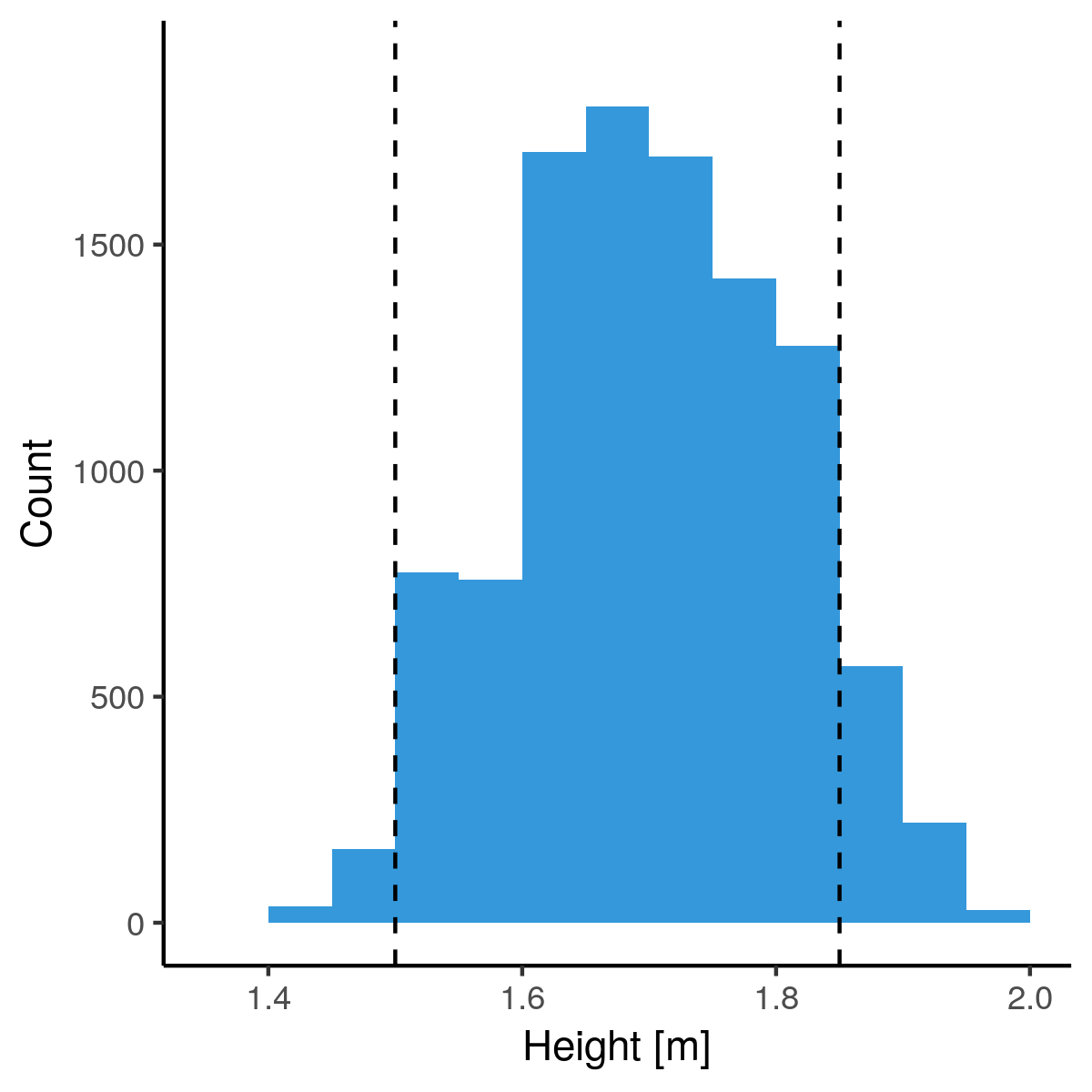
Bucketing heights
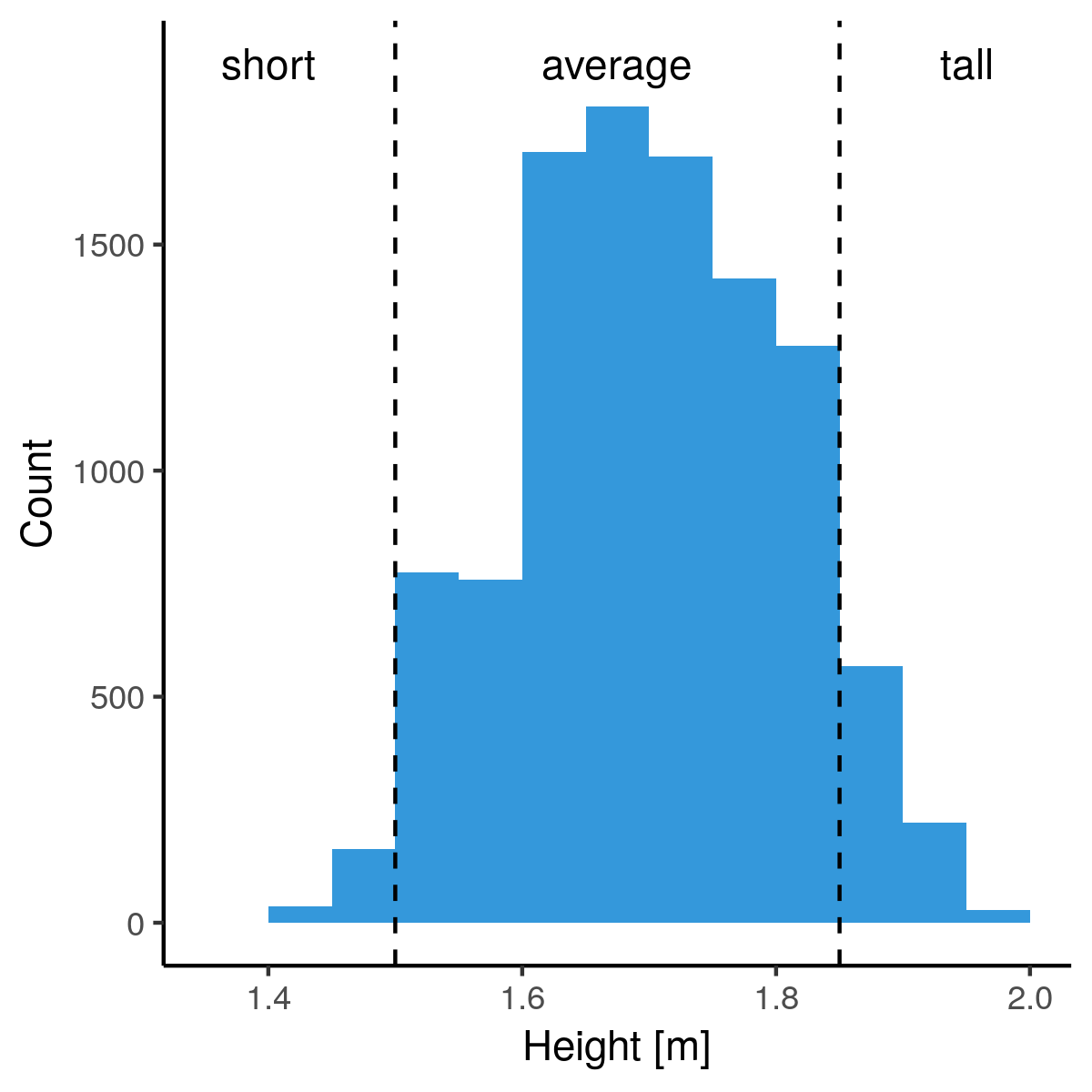
Bucketing heights
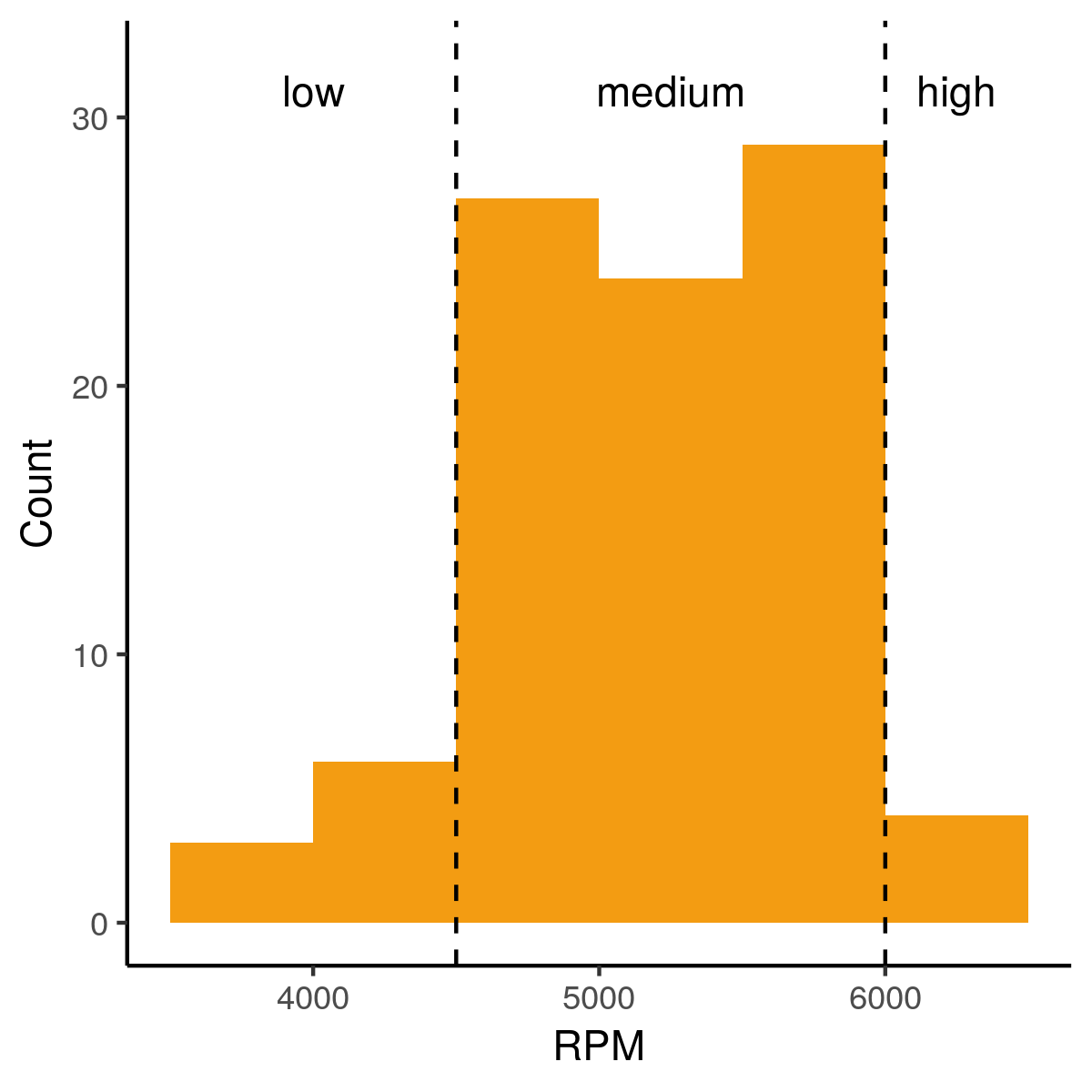
RPM histogram
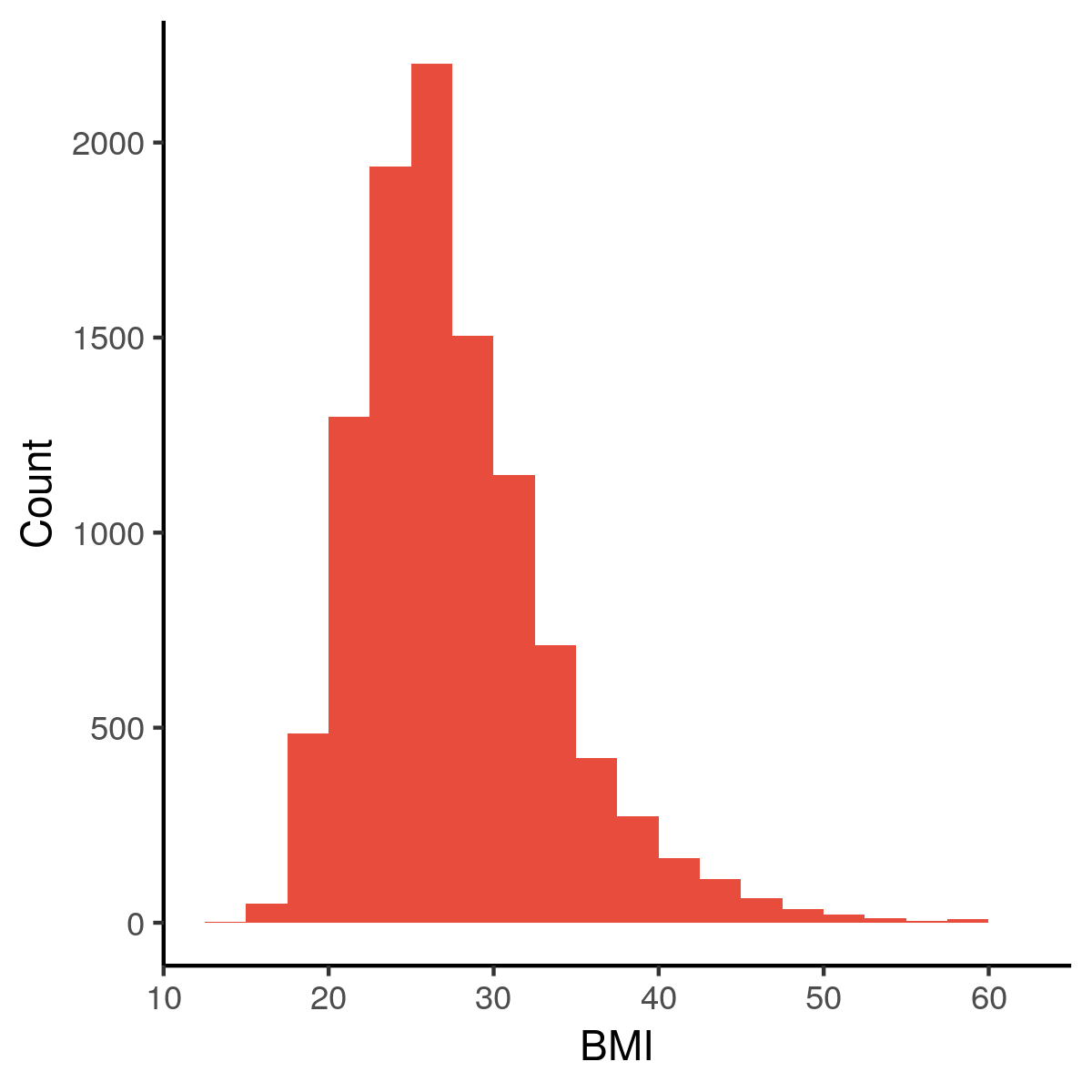
Mass & Height to BMI
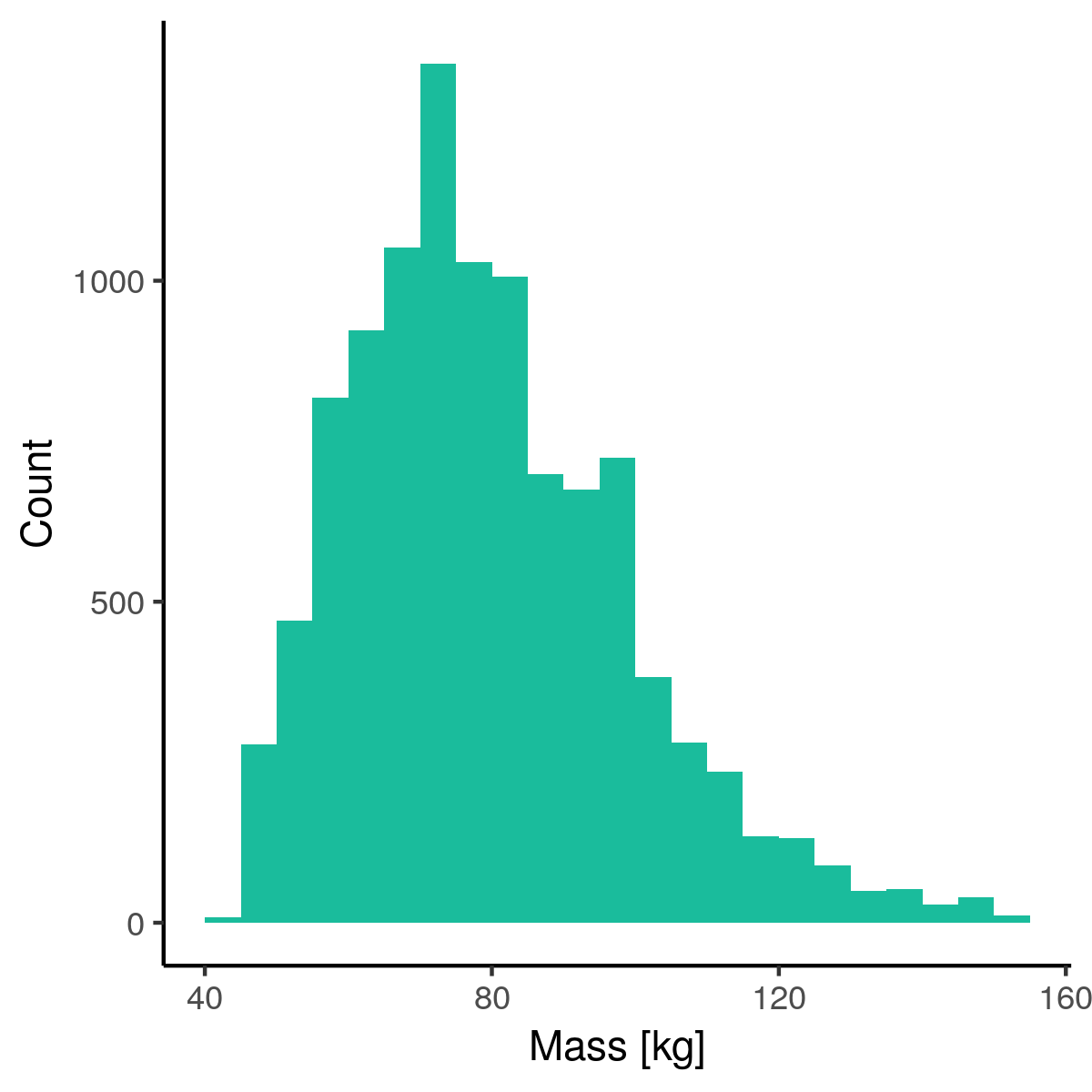
Mass & Height to BMI
Machine Learning with PySpark
Andrew Collier
Data Scientist, Fathom Data

