Estratégia de crédito e perda mínima esperada
Modelagem de Risco de Crédito em Python

Michael Crabtree
Data Scientist, Ford Motor Company
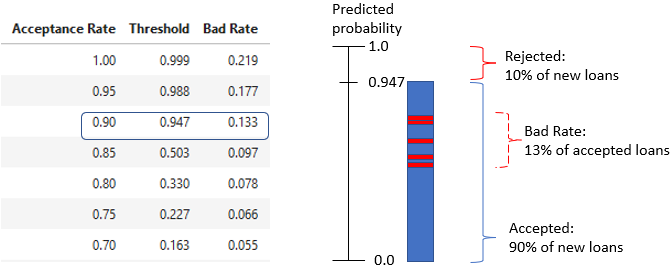
Interpretação da tabela de estratégia
strat_df = pd.DataFrame(zip(accept_rates, thresholds, bad_rates),
columns = ['Acceptance Rate','Threshold','Bad Rate'])
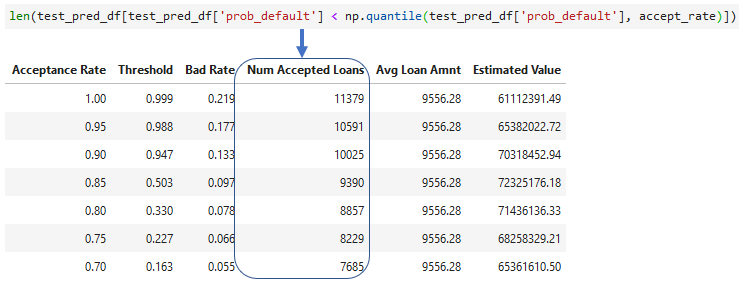
Adicionando empréstimos aceitos
- Quantidade de empréstimos aceitos para cada taxa
- Pode usar
len()ou.count()
- Pode usar
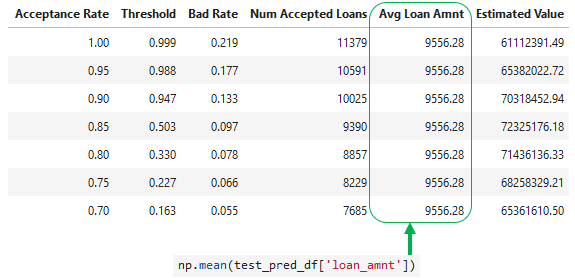
Adicionando valor médio do empréstimo
- Média de
loan_amntno conjunto de teste
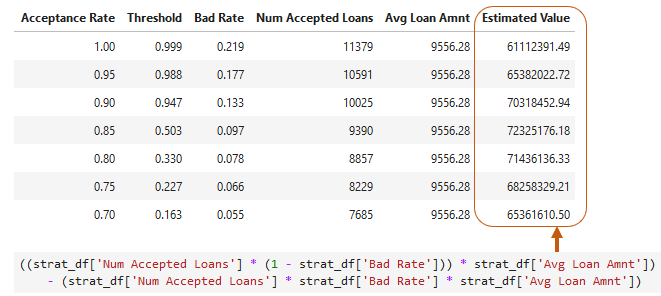
Estimando o valor da carteira
- Média dos aprovados sem default menos a média dos aprovados com default
- Assume que cada default perde o
loan_amnt
Perda total esperada
- Quanto esperamos perder com os defaults da carteira
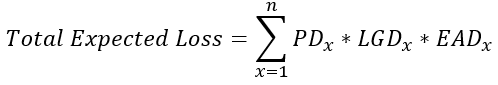
# Probability of default (PD)
test_pred_df['prob_default']
# Exposure at default = loan amount (EAD)
test_pred_df['loan_amnt']
# Loss given default = 1.0 for total loss (LGD)
test_pred_df['loss_given_default']

