Desempenho do modelo de crédito
Modelagem de Risco de Crédito em Python

Michael Crabtree
Data Scientist, Ford Motor Company
Acurácia do modelo
- Calcular acurácia
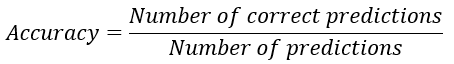
- Usar o método
.score()do scikit-learn
# Verificar a acurácia no conjunto de teste
clf_logistic1.score(X_test,y_test)
0.81
- 81% dos valores de
loan_statusprevistos corretamente
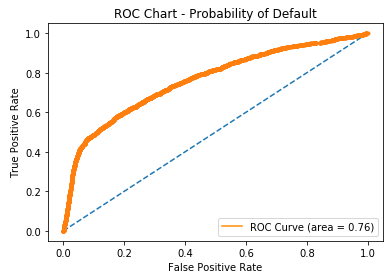
Gráficos de curva ROC
- Curva ROC (Receiver Operating Characteristic)
- Plota taxa de verdadeiros positivos (sensibilidade) vs. taxa de falsos positivos (fall-out)
fallout, sensitivity, thresholds = roc_curve(y_test, prob_default)
plt.plot(fallout, sensitivity, color = 'darkorange')
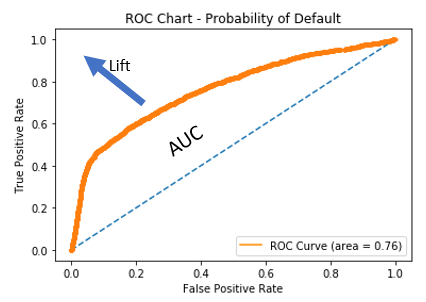
Analisando gráficos ROC
- AUC (Área Sob a Curva): área entre a curva e a predição aleatória
Limites de default
- Limite (threshold): a partir de que probabilidade é default
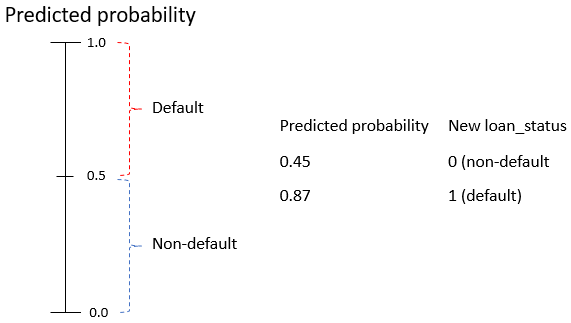
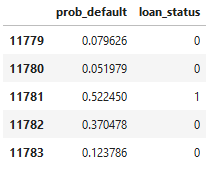
Definindo o limite
- Reclassificar empréstimos com limite
0.5
preds = clf_logistic.predict_proba(X_test)
preds_df = pd.DataFrame(preds[:,1], columns = ['prob_default'])
preds_df['loan_status'] = preds_df['prob_default'].apply(lambda x: 1 if x > 0.5 else 0)
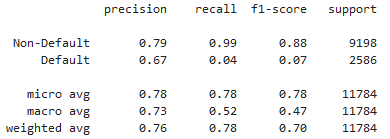
Relatórios de classificação de crédito
classification_report()no scikit-learn
from sklearn.metrics import classification_report
classification_report(y_test, preds_df['loan_status'], target_names=target_names)
Selecionando métricas de classificação
- Selecionar e salvar partes específicas do
classification_report() - Usar
precision_recall_fscore_support()do scikit-learn
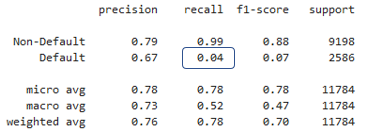
from sklearn.metrics import precision_recall_fscore_support
precision_recall_fscore_support(y_test,preds_df['loan_status'])[1][1]

