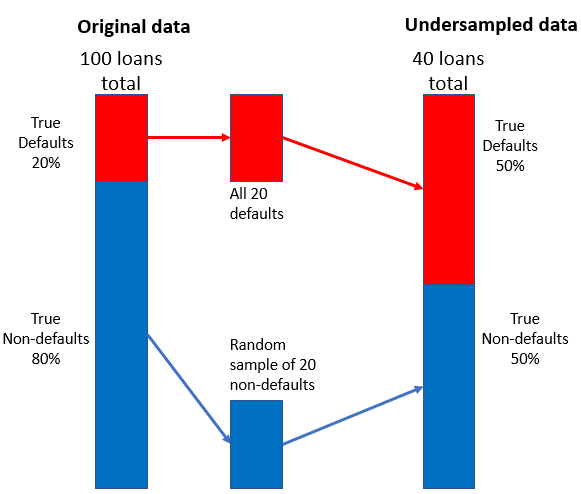
Desbalanceamento em dados de empréstimos
Modelagem de Risco de Crédito em Python

Michael Crabtree
Data Scientist, Ford Motor Company
Função de perda do modelo
- Gradient Boosted Trees no
xgboostusam log-loss como função de perda- O objetivo é minimizá-la
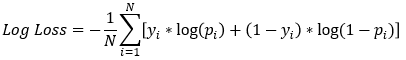
| Status real do empréstimo | Prob. prevista | Log-loss |
|---|---|---|
| 1 | 0.1 | 2.3 |
| 0 | 0.9 | 2.3 |
- Um default previsto errado tem impacto financeiro pior
Estratégia de subamostragem
- Combine uma amostra aleatória menor de não inadimplentes com os inadimplentes