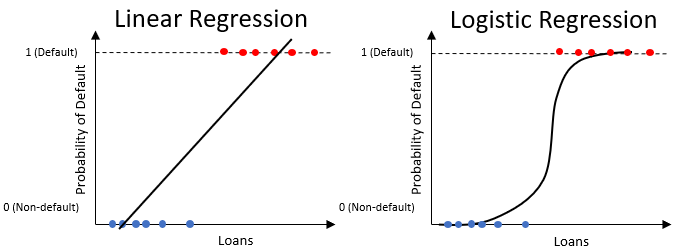
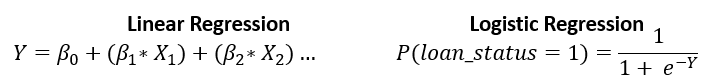Regressão logística para probabilidade de inadimplência
Modelagem de Risco de Crédito em Python

Michael Crabtree
Data Scientist, Ford Motor Company
Prevendo probabilidades
- Probabilidades de inadimplência como resultado de ML
- Aprender a partir das colunas (features)
- Modelos de classificação (inadimplente, adimplente)
- Dois modelos mais comuns:
- Regressão logística
- Árvore de decisão
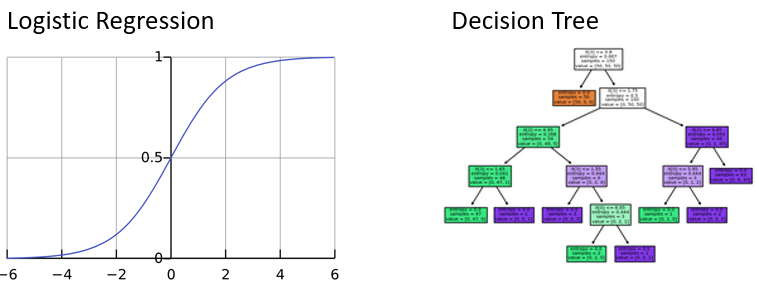
Regressão logística
- Parecida com regressão linear, mas só gera valores entre
0e1