Taxas de aceitação de crédito
Modelagem de Risco de Crédito em Python

Michael Crabtree
Data Scientist, Ford Motor Company
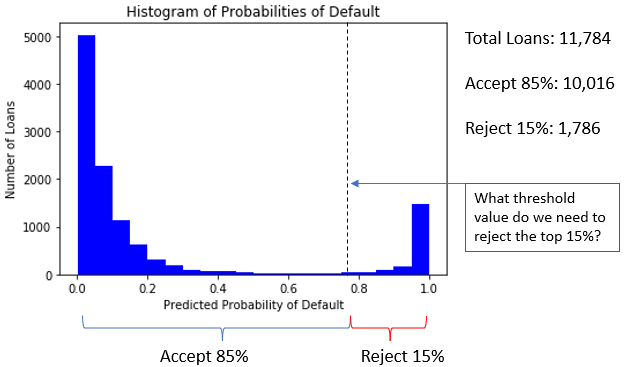
Entendendo a taxa de aceitação
- Exemplo: aceitar 85% dos empréstimos com menor
prob_default
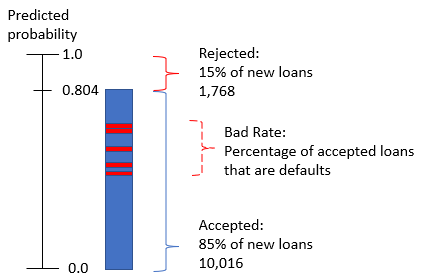
Taxa de inadimplência
- Mesmo com um limiar calculado, alguns empréstimos aceitos vão inadimplir
- São empréstimos com
prob_defaultperto da faixa onde o modelo não está bem calibrado
Cálculo da taxa de inadimplência
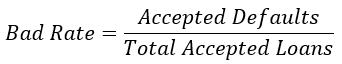
#Calculate the bad rate
np.sum(accepted_loans['true_loan_status']) / accepted_loans['true_loan_status'].count()
- Se não inadimplente é
0e inadimplente é1, entãosum()é a contagem de inadimplentes - O
.count()de uma única coluna é igual ao número de linhas do data frame

