Validação cruzada para modelos de crédito
Modelagem de Risco de Crédito em Python

Michael Crabtree
Data Scientist, Ford Motor Company
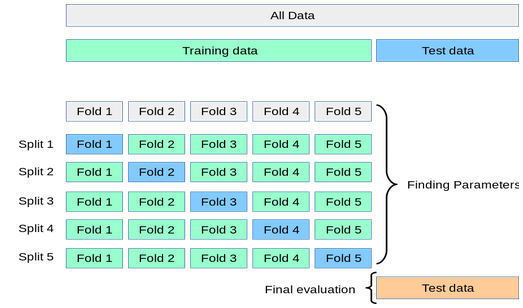
Como funciona a validação cruzada
- Processa partes do treino (chamadas folds) e testa contra a parte não usada
- Teste final no conjunto de teste real
1 https://scikit-learn.org/stable/modules/cross_validation.html
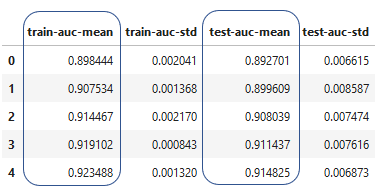
Resultados da validação cruzada
- Cria um data frame com os valores da validação cruzada