Evaluate models with Accelerator
Efficient AI Model Training with PyTorch

Dennis Lee
Data Engineer, Amazon
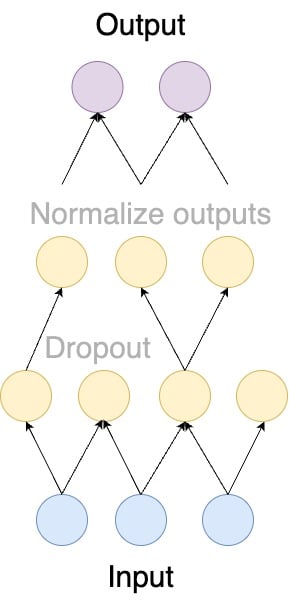
Why put a model in evaluation mode?
Dropout and batch normalization
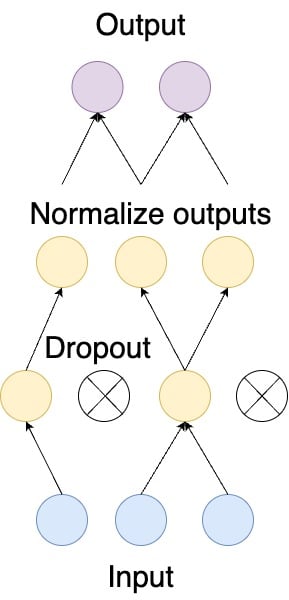
Why put a model in evaluation mode?
Dropout and batch normalization
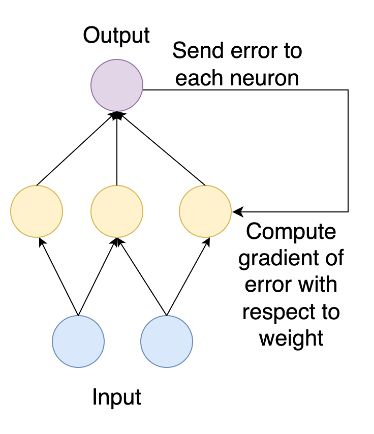
Disable gradients with torch.no_grad()
Computing gradients in backpropagation