Fine-tune models with Trainer
Efficient AI Model Training with PyTorch

Dennis Lee
Data Engineer, Amazon
Data preparation
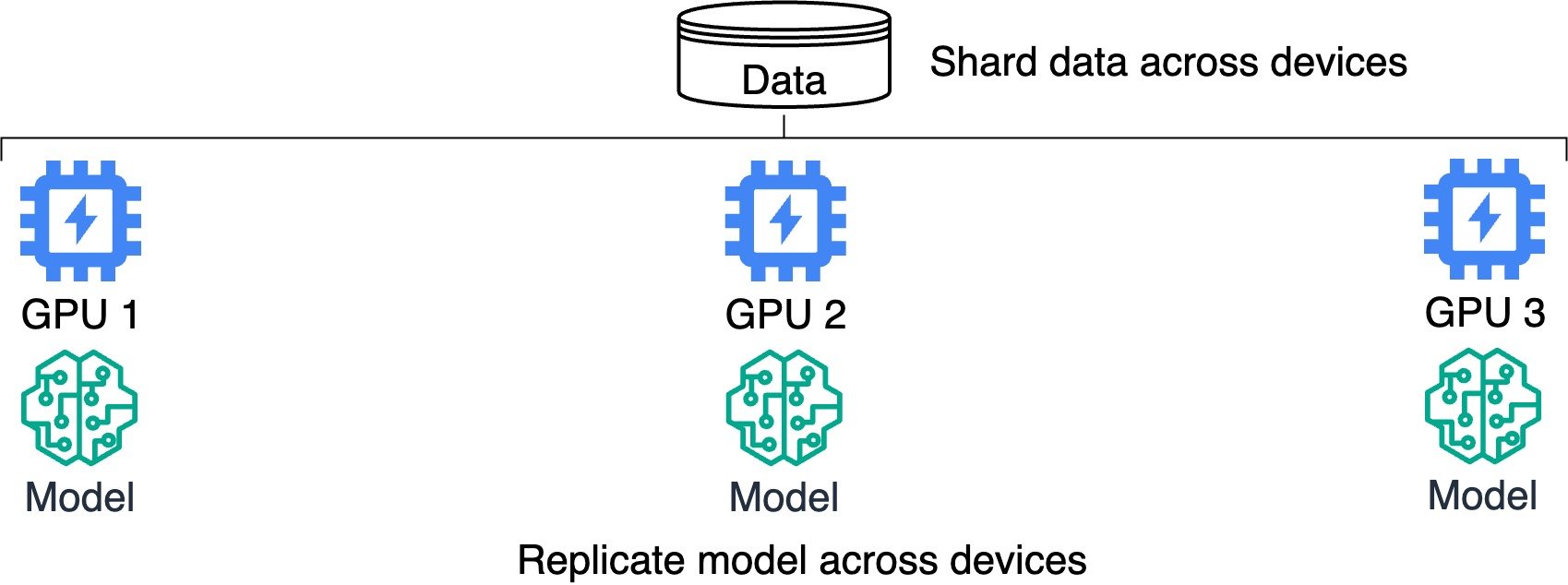
Distributed training
Trainer and Accelerator

Trainer and Accelerator
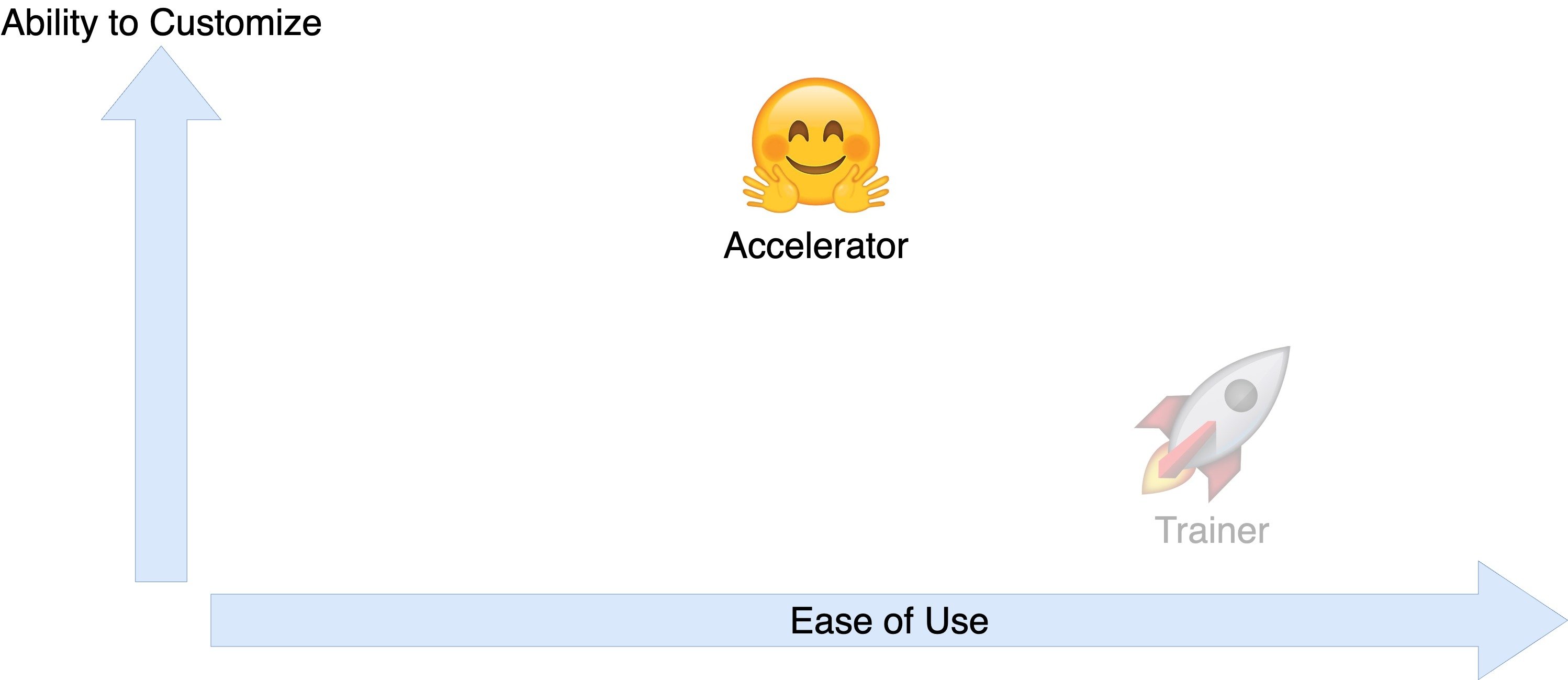
Turbocharge training with Trainer

Efficient AI Model Training with PyTorch
Dennis Lee
Data Engineer, Amazon

