Mixed precision training with 8-bit Adam
Efficient AI Model Training with PyTorch

Dennis Lee
Data Engineer, Amazon
Optimizers for training efficiency
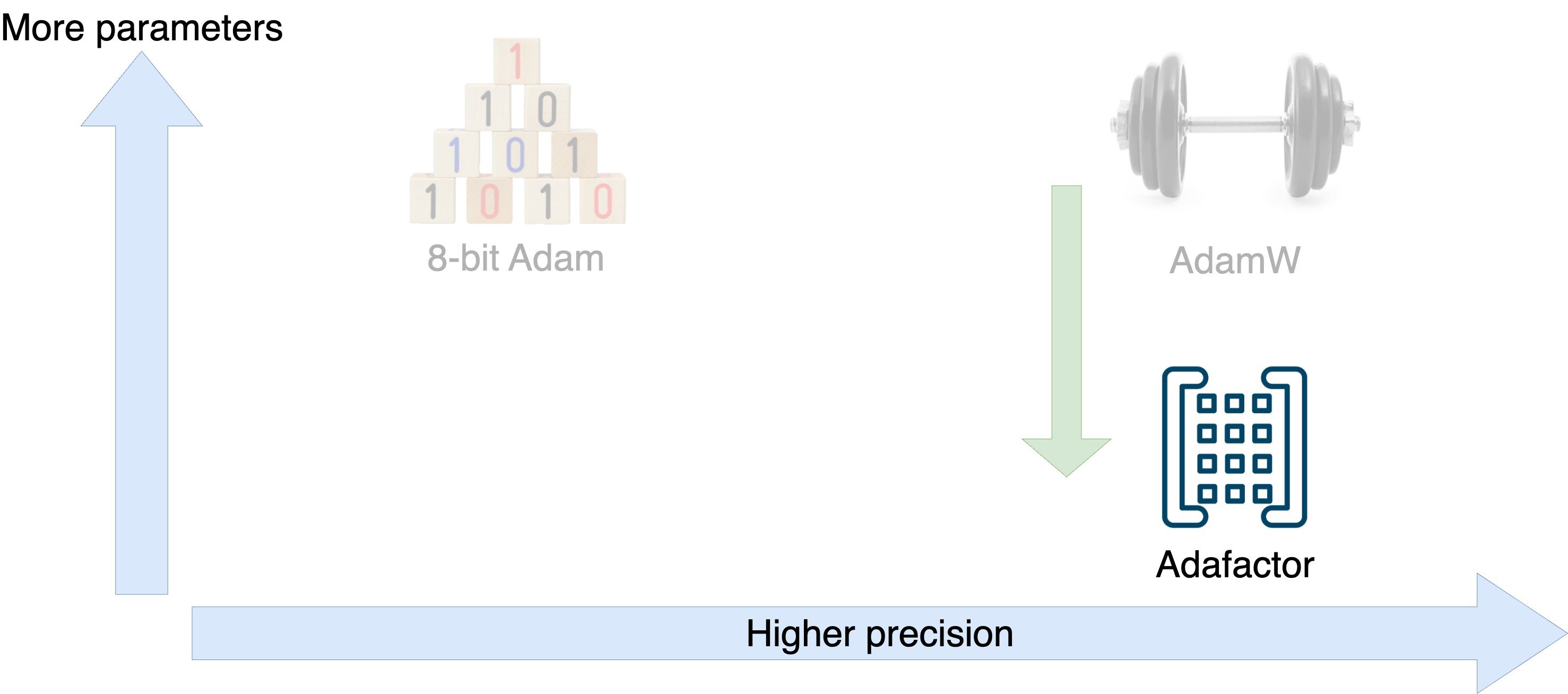
Optimizers for training efficiency
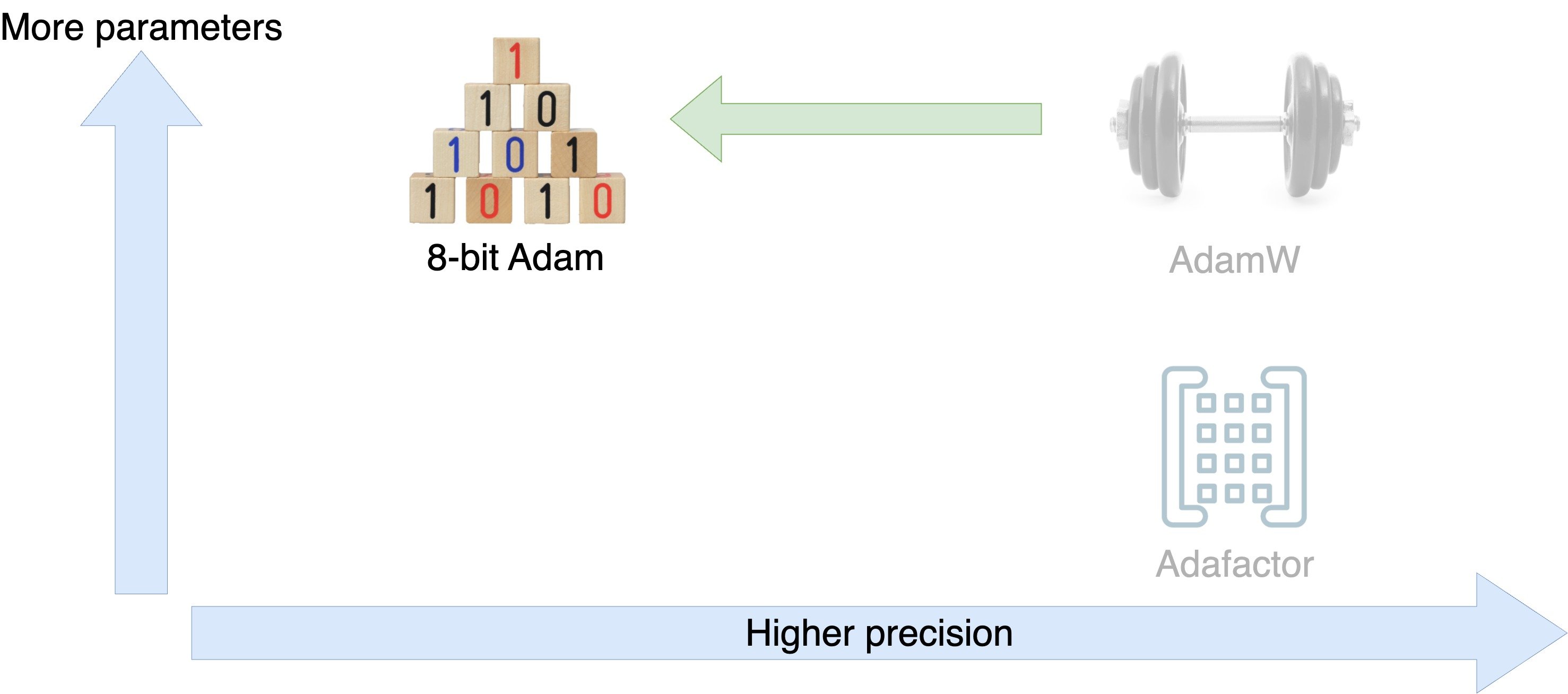
How does 8-bit Adam work?
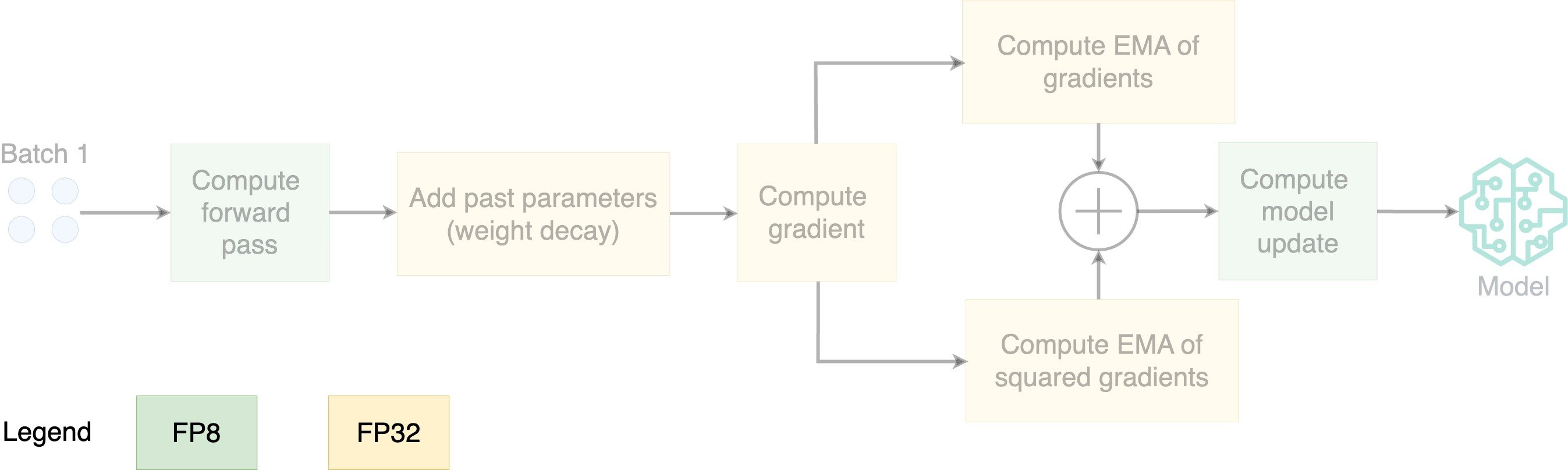
- Store parameters in FP8; optimize in FP32
How does 8-bit Adam work?
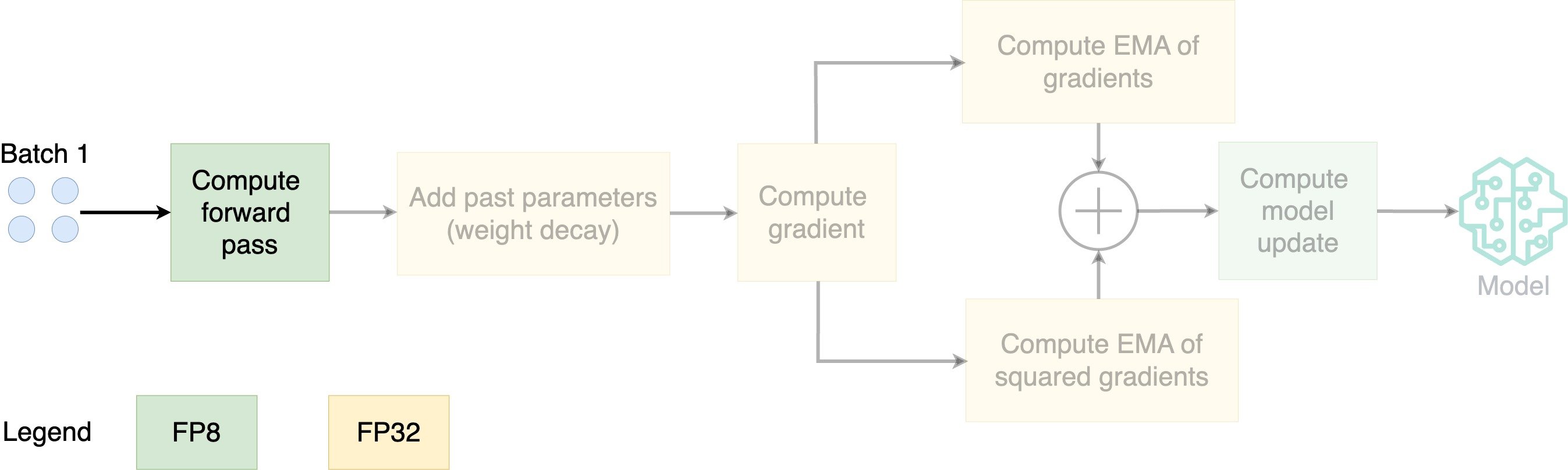
- Store parameters in FP8; optimize in FP32
How does 8-bit Adam work?
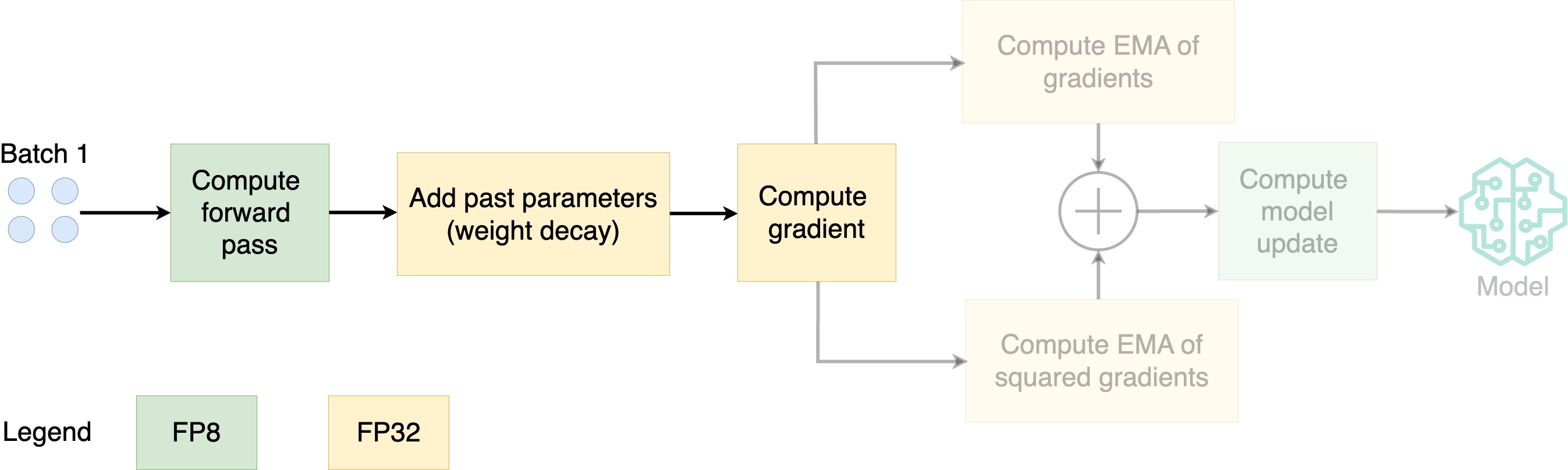
- Store parameters in FP8; optimize in FP32
How does 8-bit Adam work?

- Store parameters in FP8; optimize in FP32
- EMA: exponential moving average
- Compute the EMA of the gradients and squared gradients
How does 8-bit Adam work?
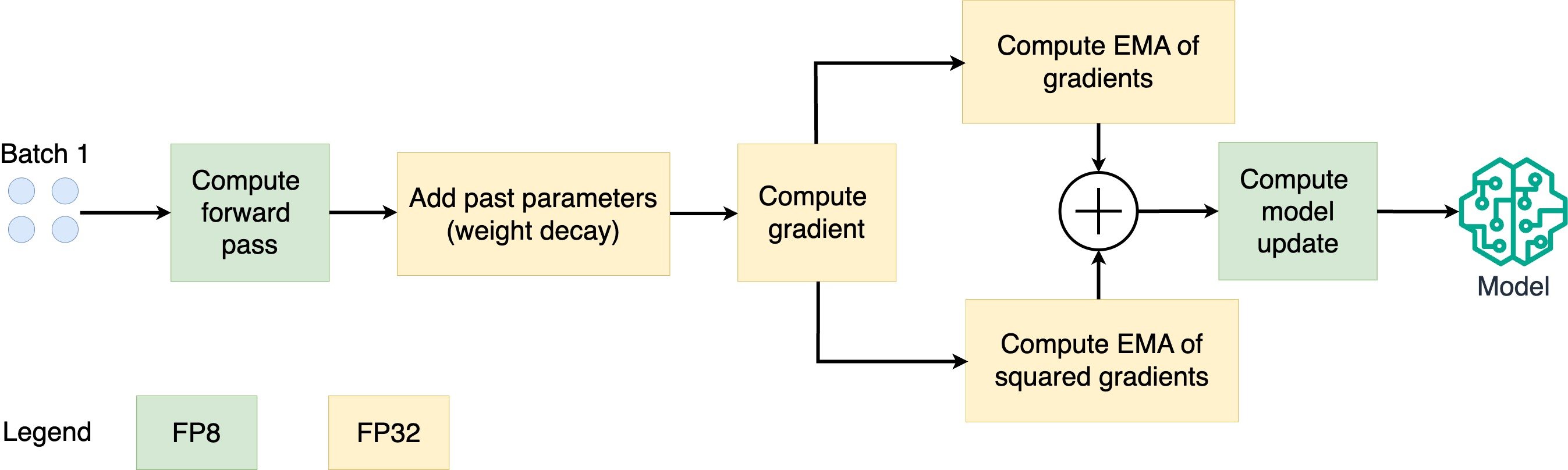
- Store parameters in FP8; optimize in FP32
- EMA: exponential moving average
- Compute the EMA of the gradients and squared gradients
How does 8-bit Adam save memory?
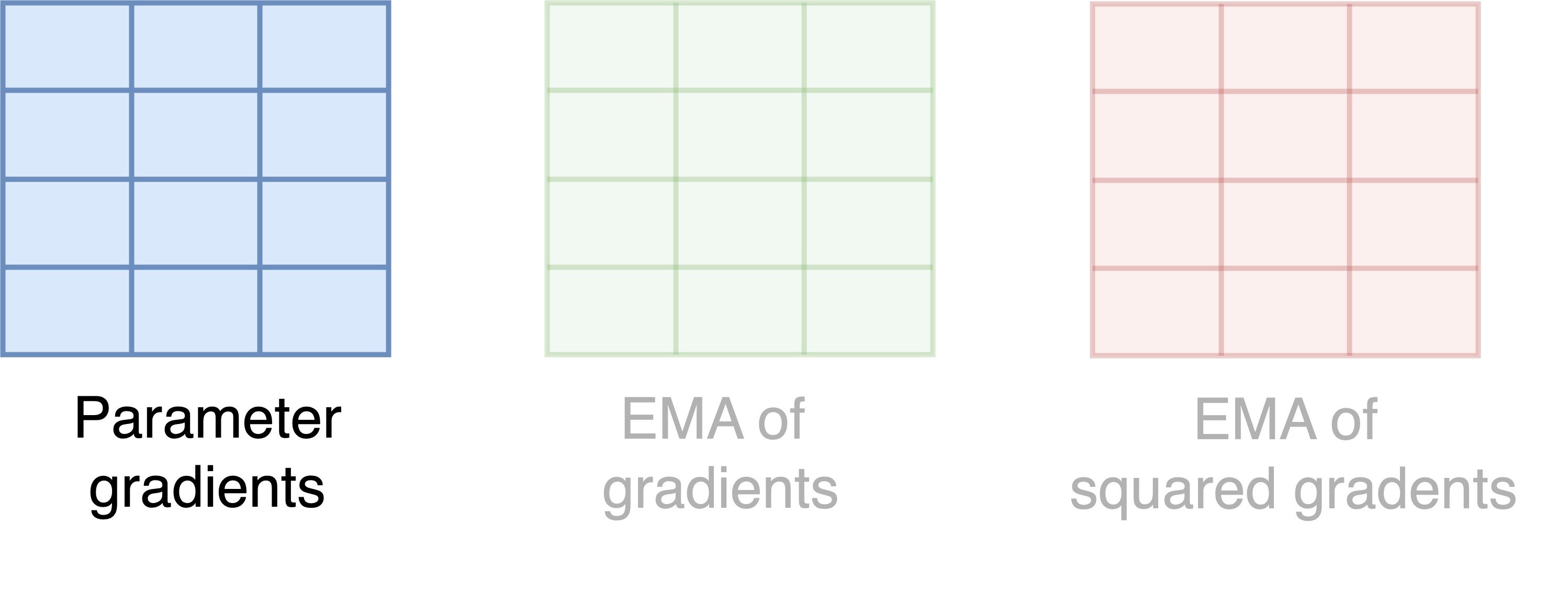
How does 8-bit Adam save memory?
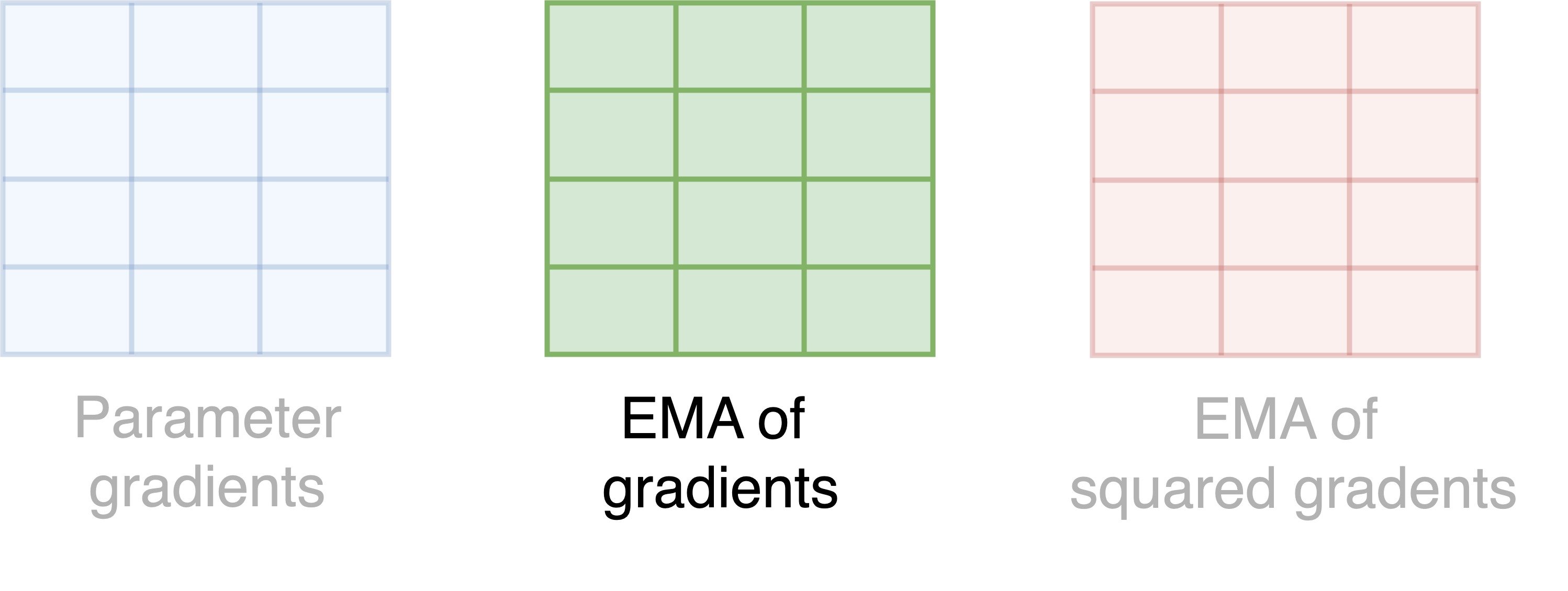
How does 8-bit Adam save memory?
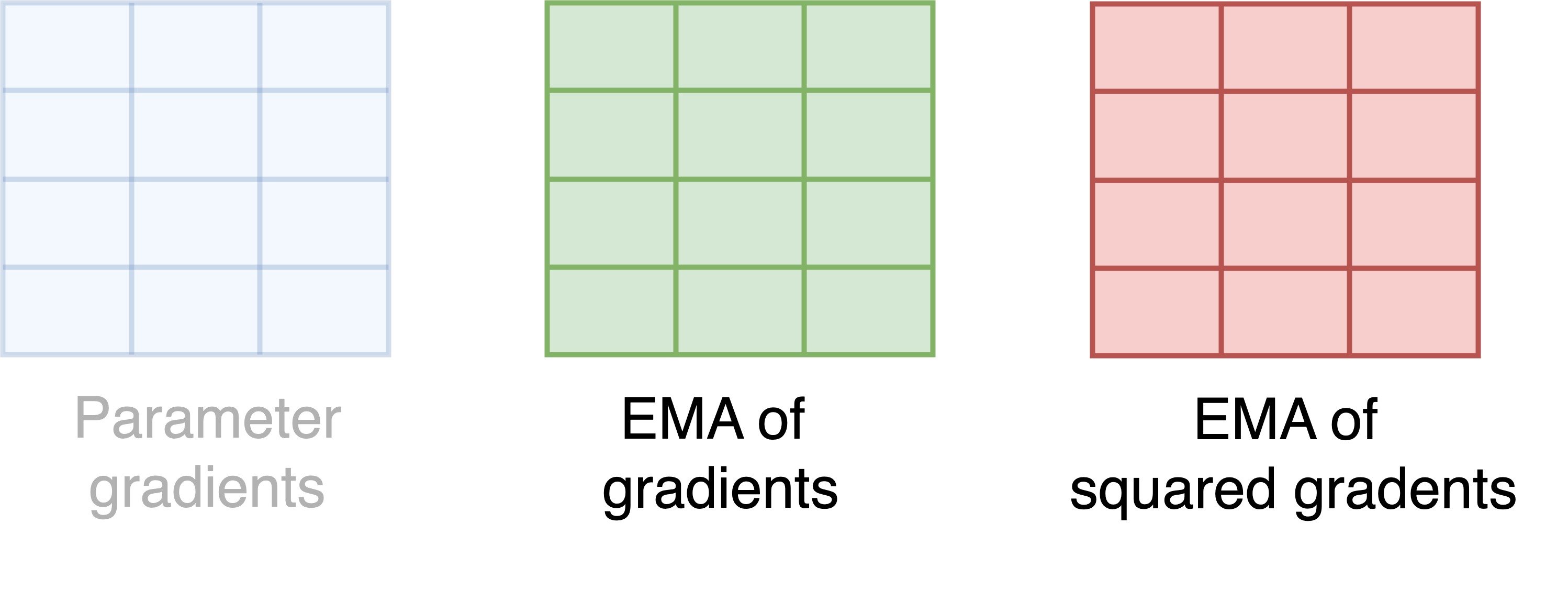
- Each square is a parameter, and each color is a state
- Memory per parameter = 2 bytes = 1 byte per state * 2 states
- Total memory = Memory per parameter (2 bytes) * Number of parameters

