Congratulations!
Efficient AI Model Training with PyTorch

Dennis Lee
Data Engineer, Amazon
Course journey
- Train models across multiple devices
- Ready to tackle large models with billions of parameters
- Challenges: hardware constraints, lengthy training times, memory limitations
Data preparation
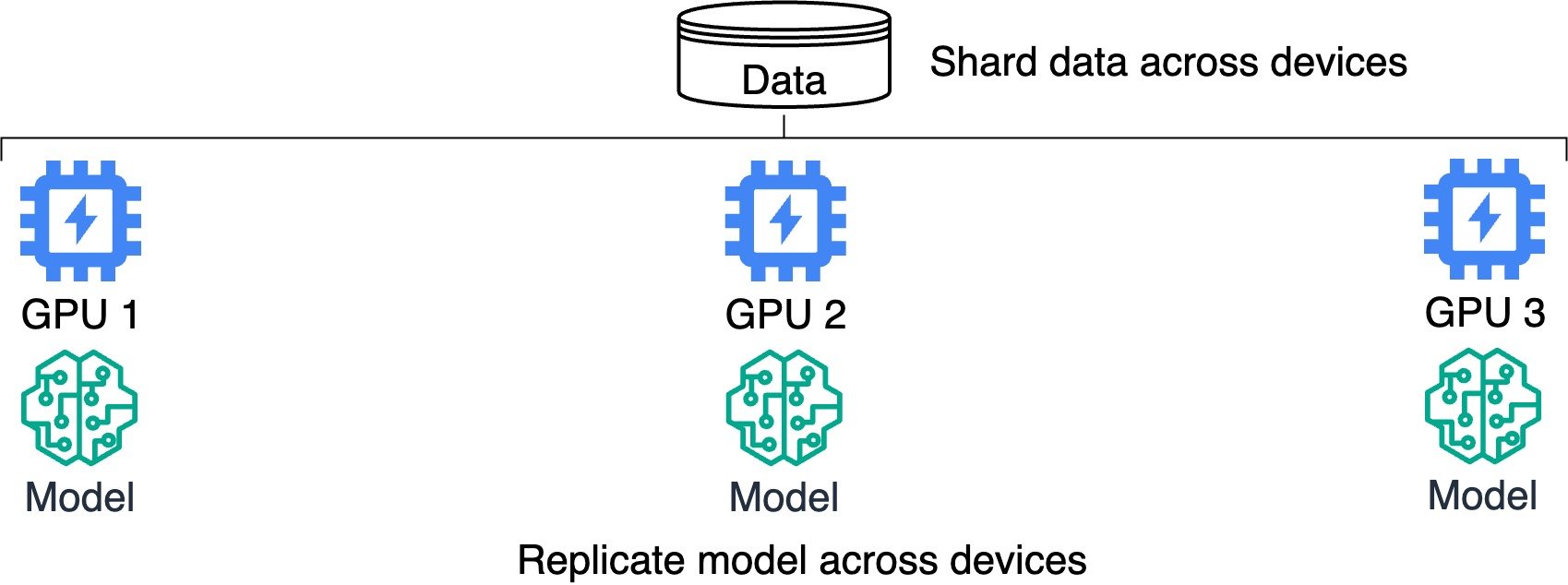
Distribute data and model across devices
Distributed training
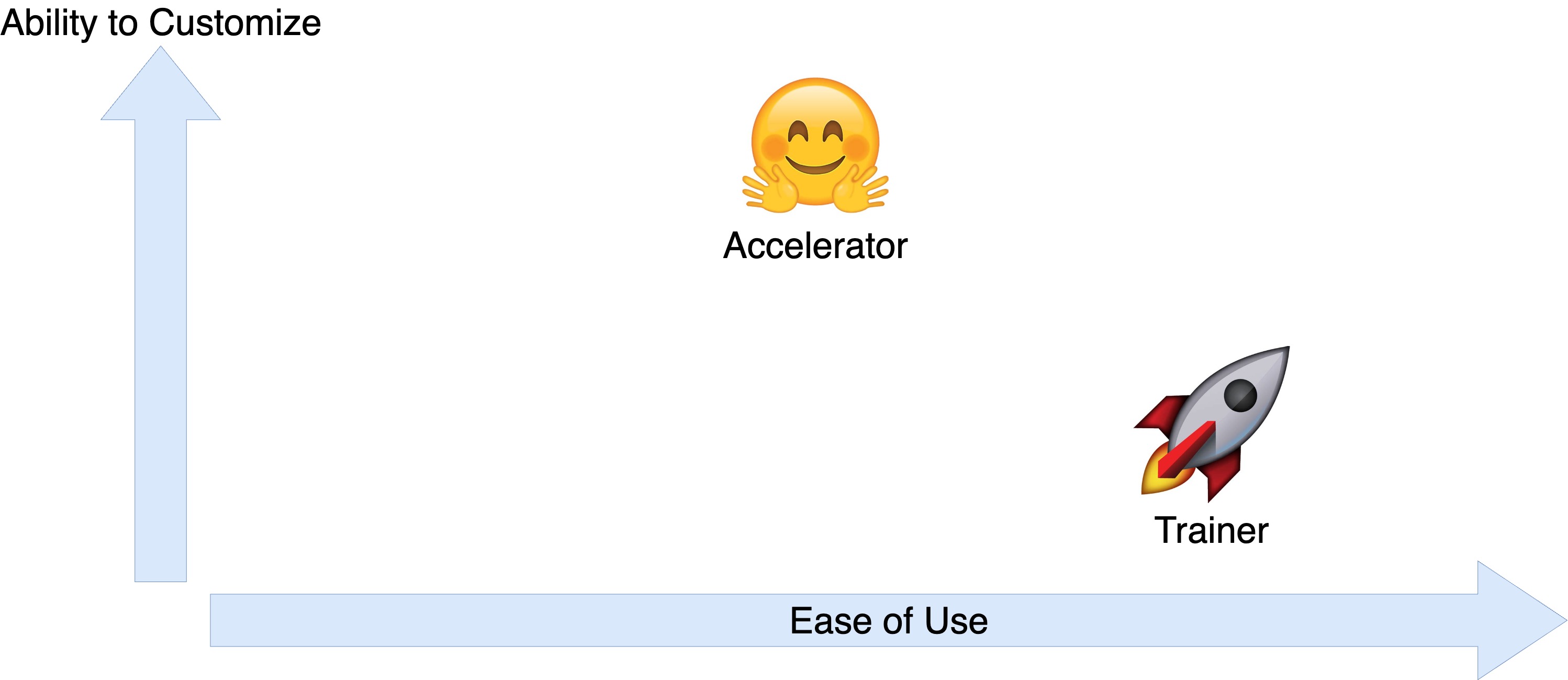
Trainer and Accelerator interfaces

Trainer and Accelerator interfaces
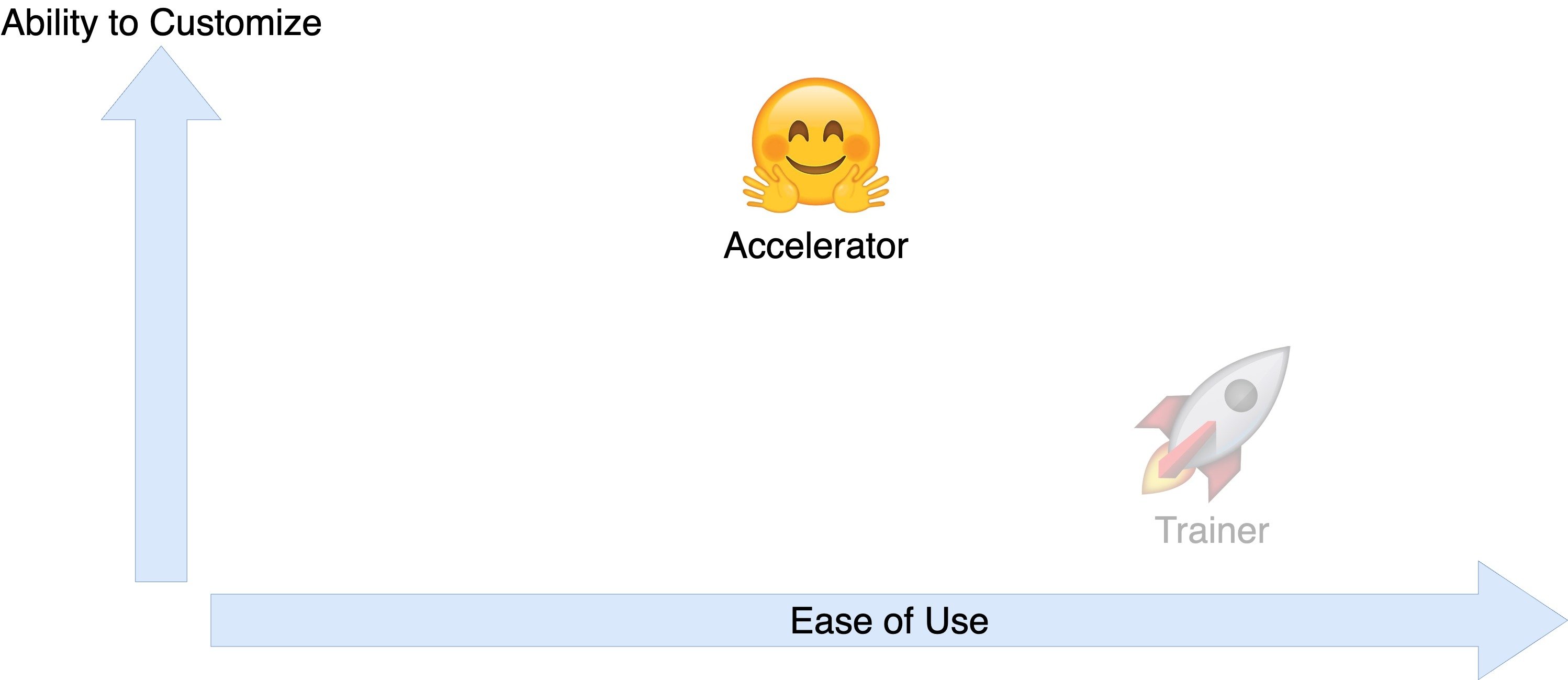
Trainer and Accelerator interfaces
Efficient training
Drivers of efficiency

Drivers of efficiency

- Memory efficiency
- Gradient accumulation: train on larger batches
- Gradient checkpointing: decrease model footprint
Drivers of efficiency

- Memory efficiency
- Gradient accumulation: train on larger batches
- Gradient checkpointing: decrease model footprint
- Communication efficiency: local SGD
Drivers of efficiency

- Memory efficiency
- Gradient accumulation: train on larger batches
- Gradient checkpointing: decrease model footprint
- Communication efficiency: local SGD
- Computational efficiency: mixed precision training
Optimizers
Optimizer tradeoffs
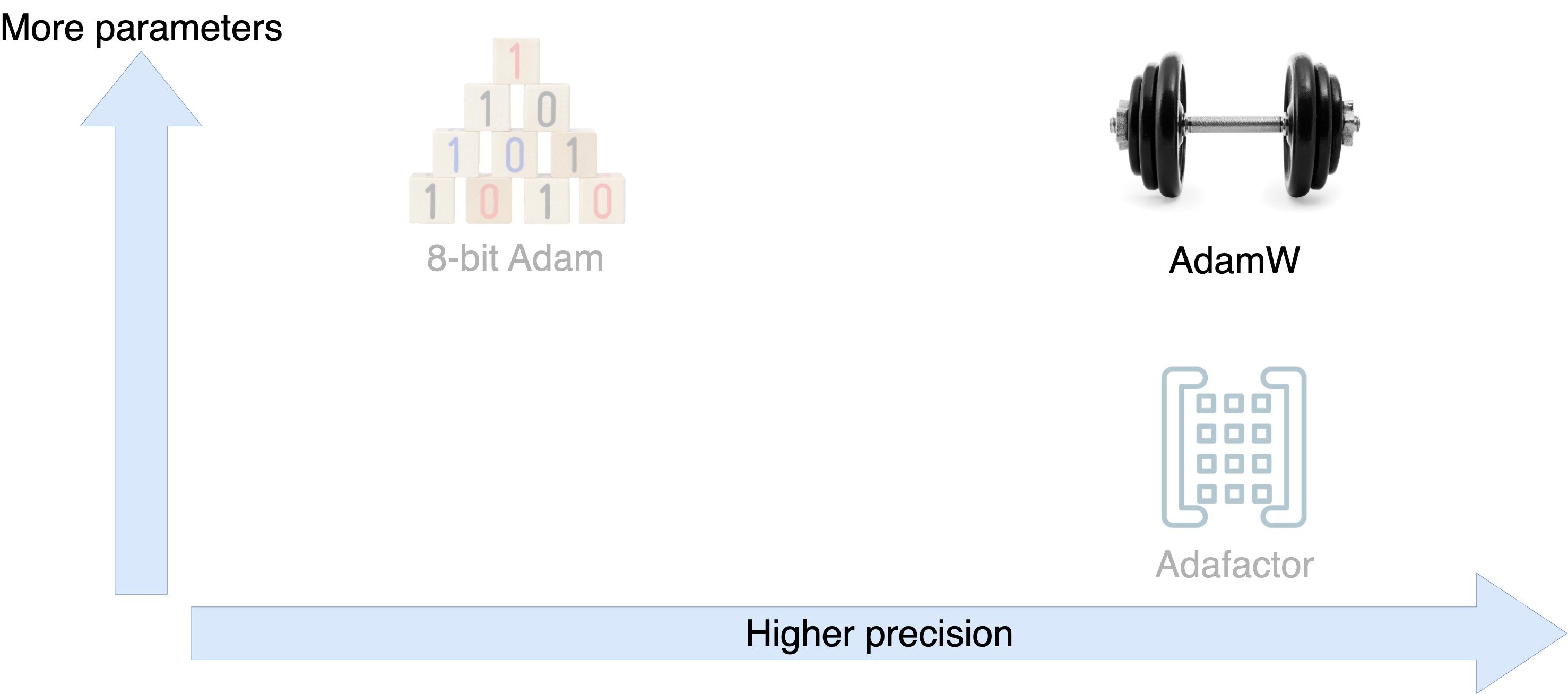
Optimizer tradeoffs
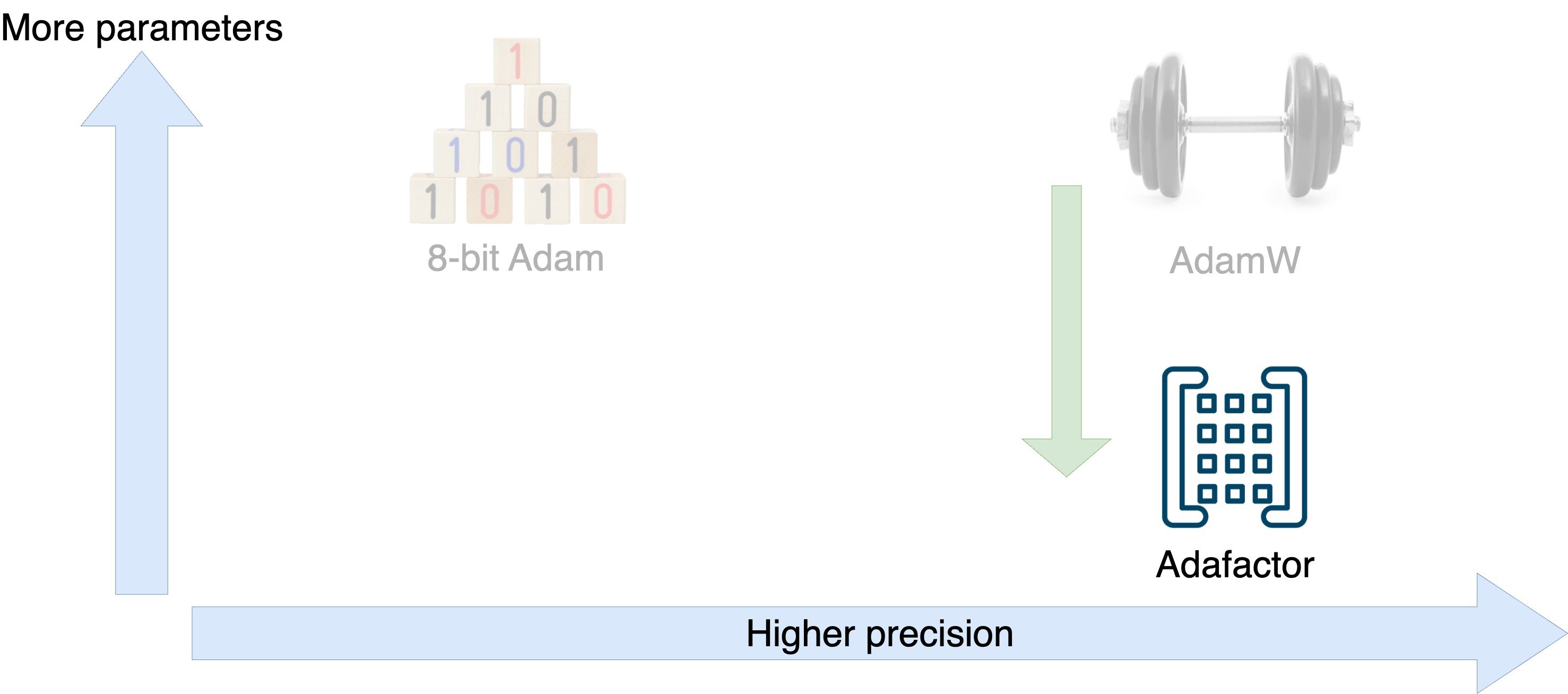
Optimizer tradeoffs
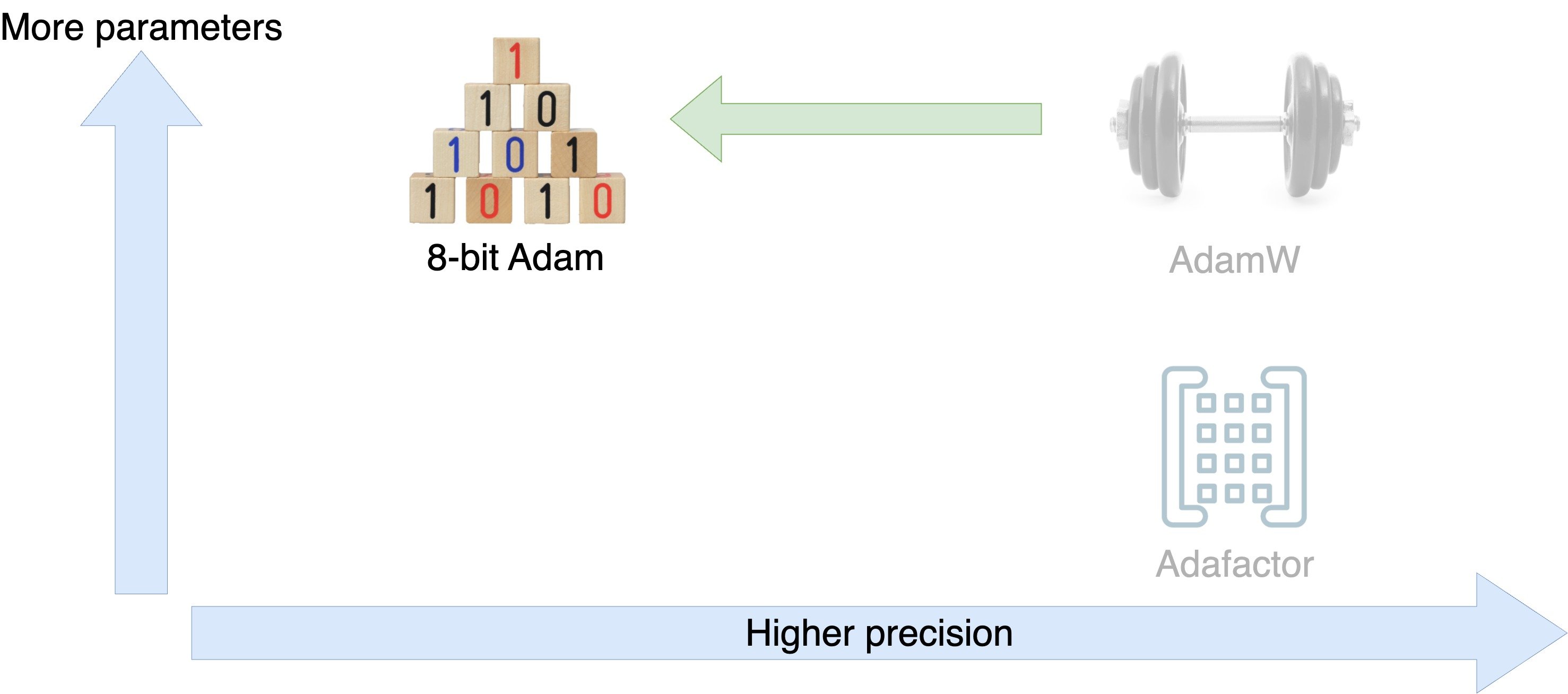
Equipped to excel in distributed training

