Gradient checkpointing and local SGD
Efficient AI Model Training with PyTorch

Dennis Lee
Data Engineer, Amazon
Improving training efficiency

Gradient checkpointing improves memory efficiency

Local SGD addresses communication efficiency

What is gradient checkpointing?
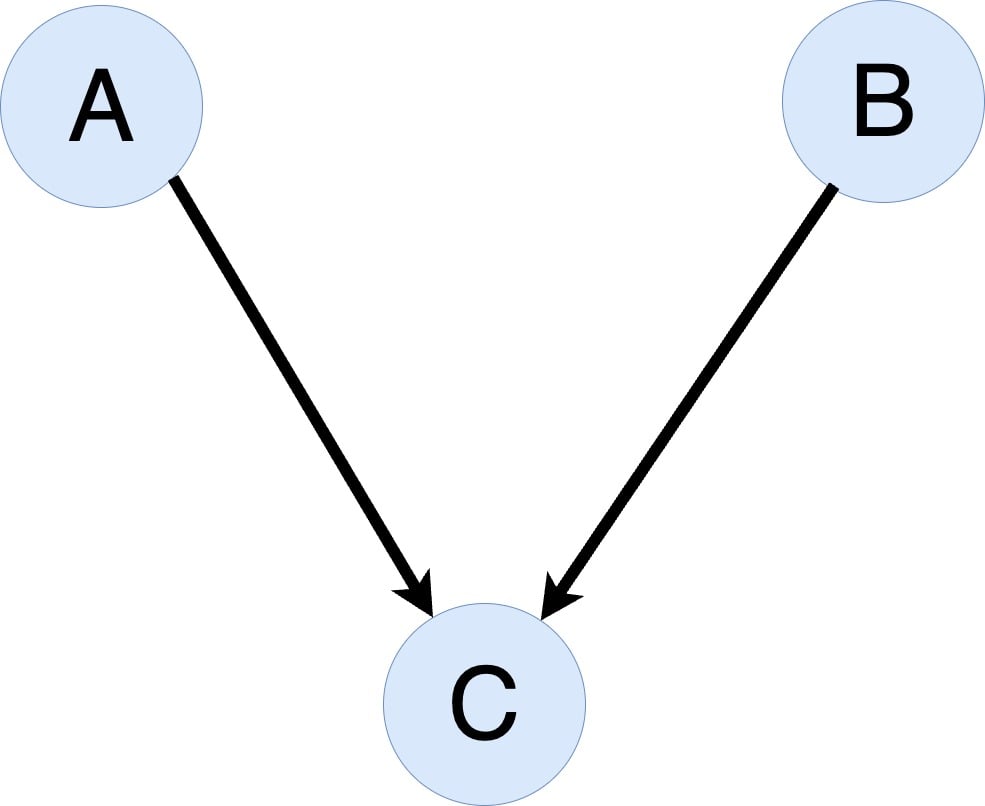
What is gradient checkpointing?
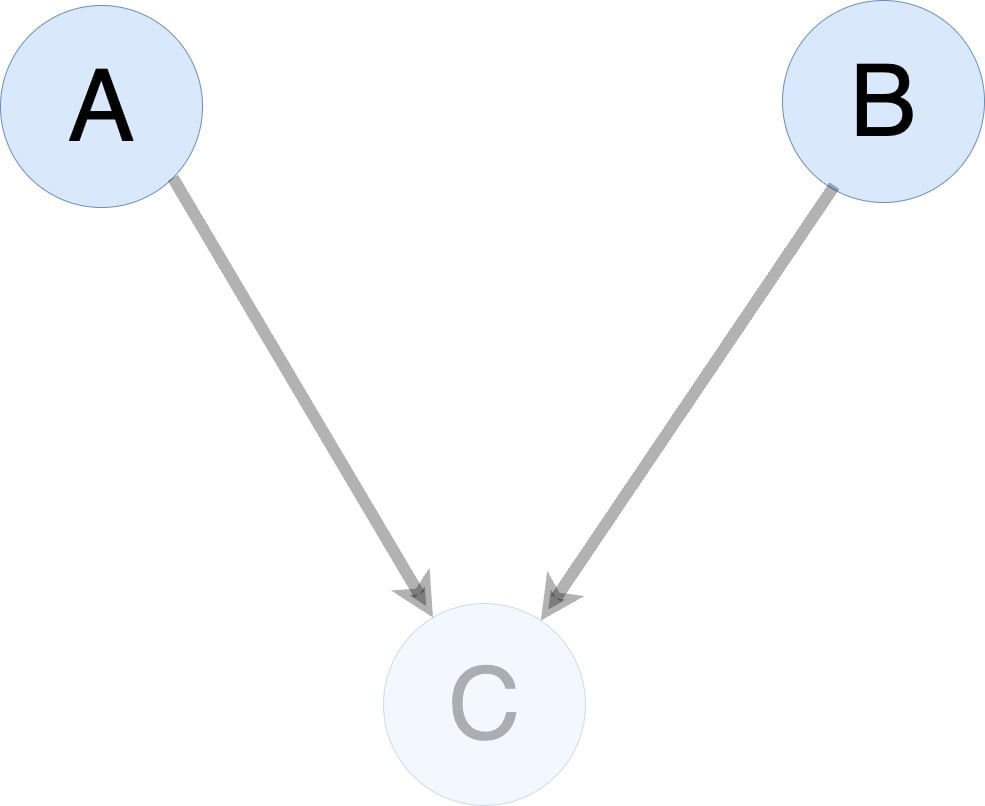
What is gradient checkpointing?
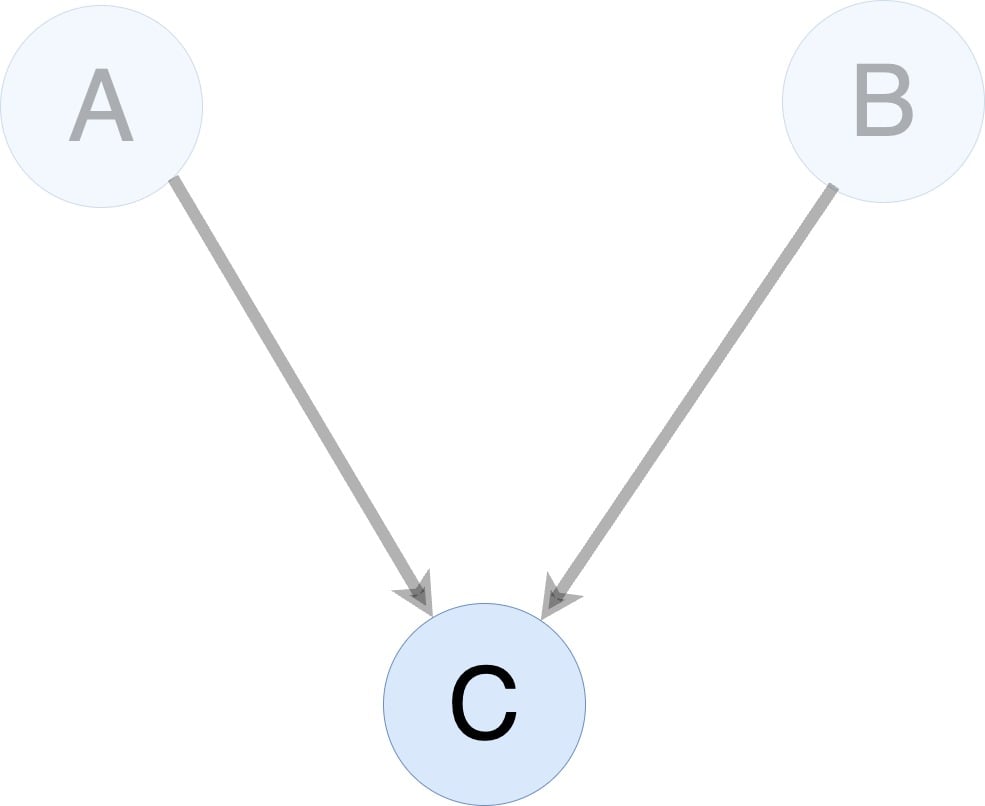
What is gradient checkpointing?
What is gradient checkpointing?
What is gradient checkpointing?
What is gradient checkpointing?
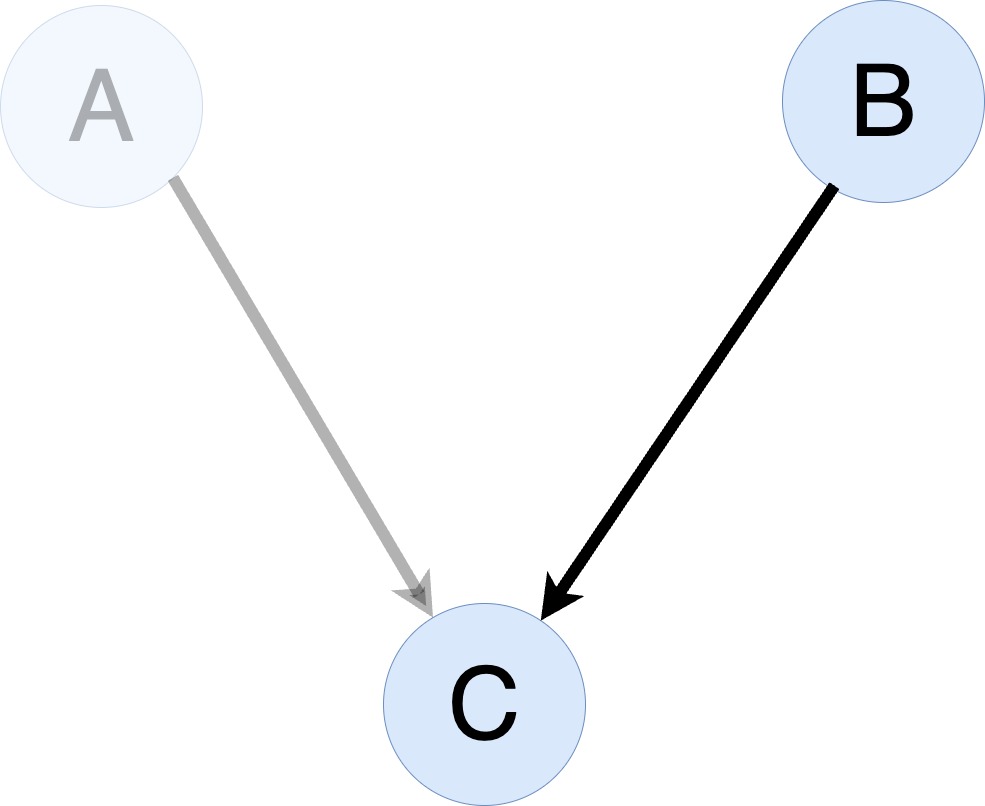
Trainer and Accelerator
Trainer and Accelerator

From Trainer to Accelerator
Local SGD improves communication efficiency
What is local SGD?

- Each device computes gradients in parallel
What is local SGD?

- Each device computes gradients in parallel
- Gradient synchronization: Driver node updates model parameters on each device
- Local SGD: Reduce frequency of gradient synchronization

