Balanced training with AdamW
Efficient AI Model Training with PyTorch

Dennis Lee
Data Engineer, Amazon
Efficient training
Optimizers for training efficiency

Optimizers for training efficiency

Optimizers for training efficiency

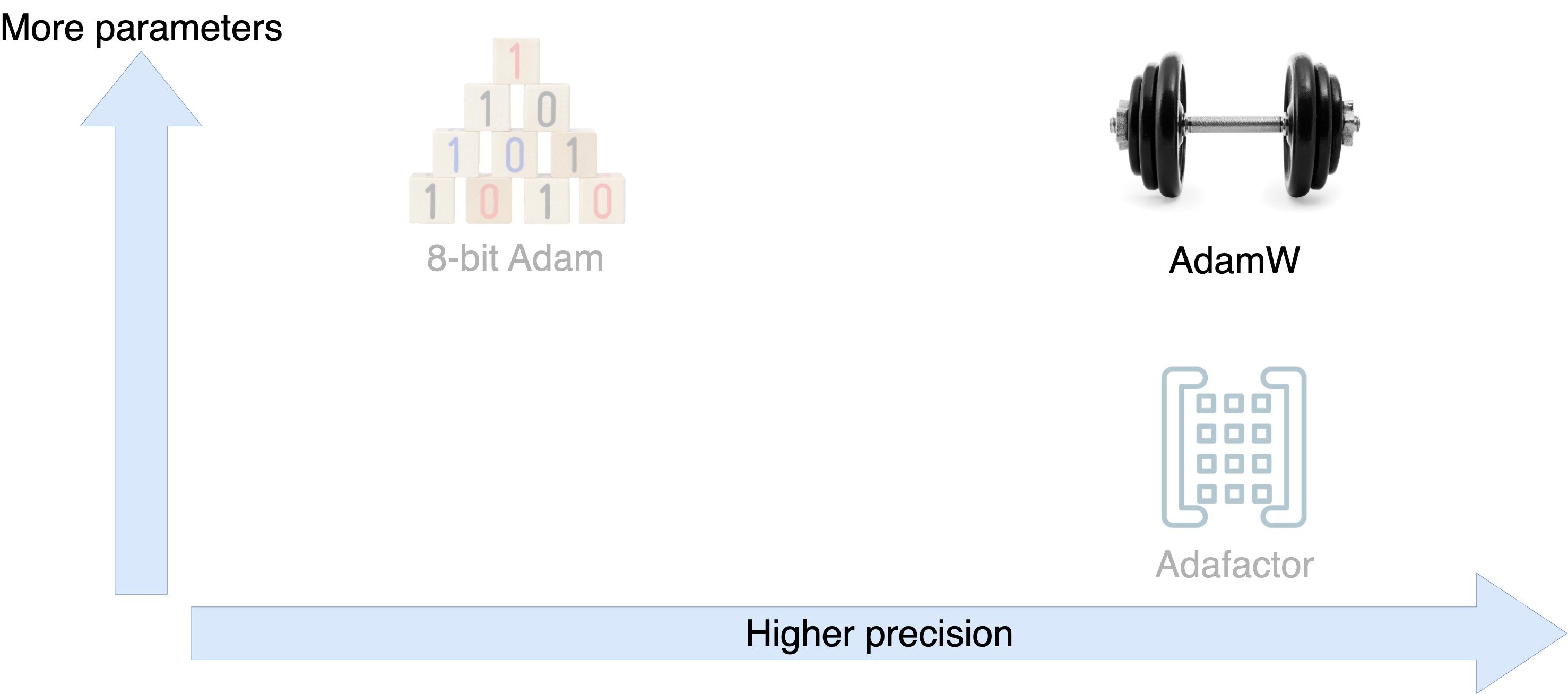
Optimizer tradeoffs
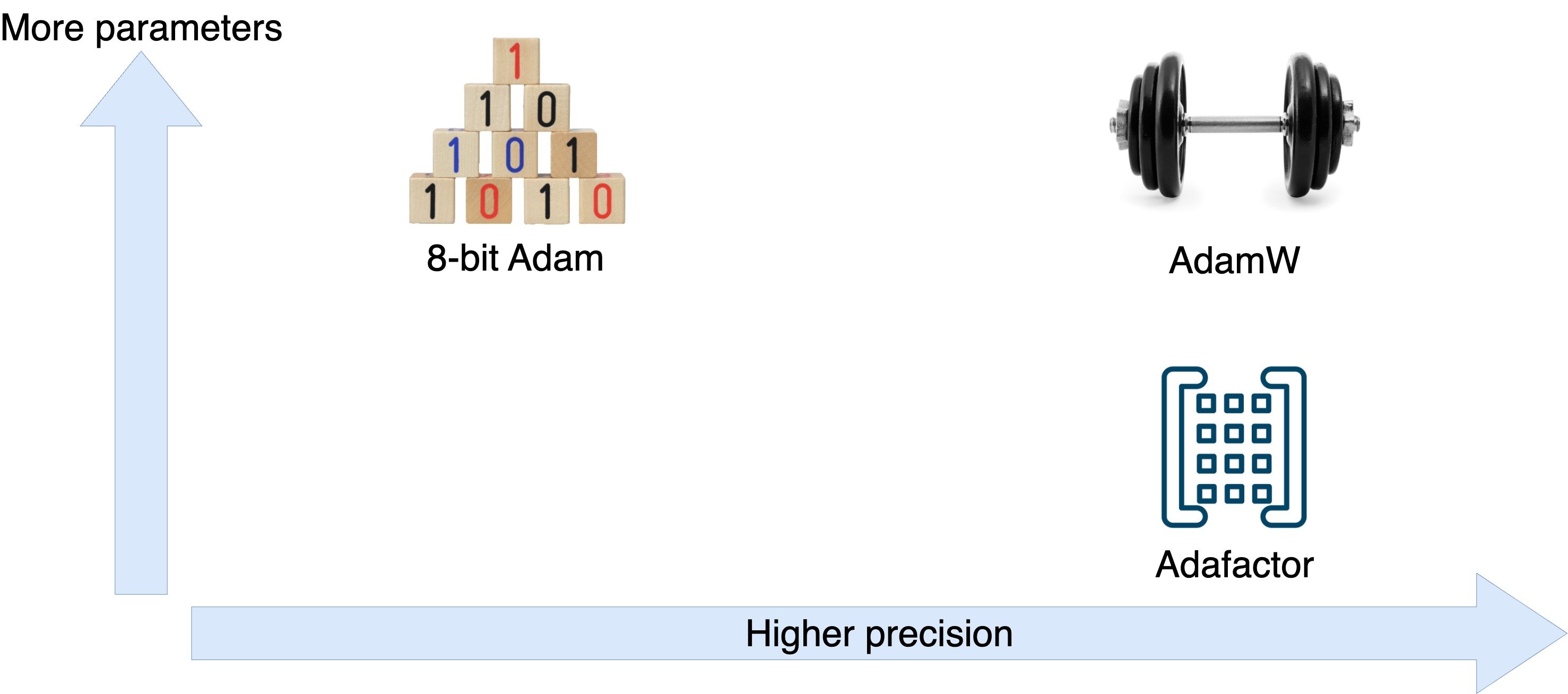
Optimizer tradeoffs
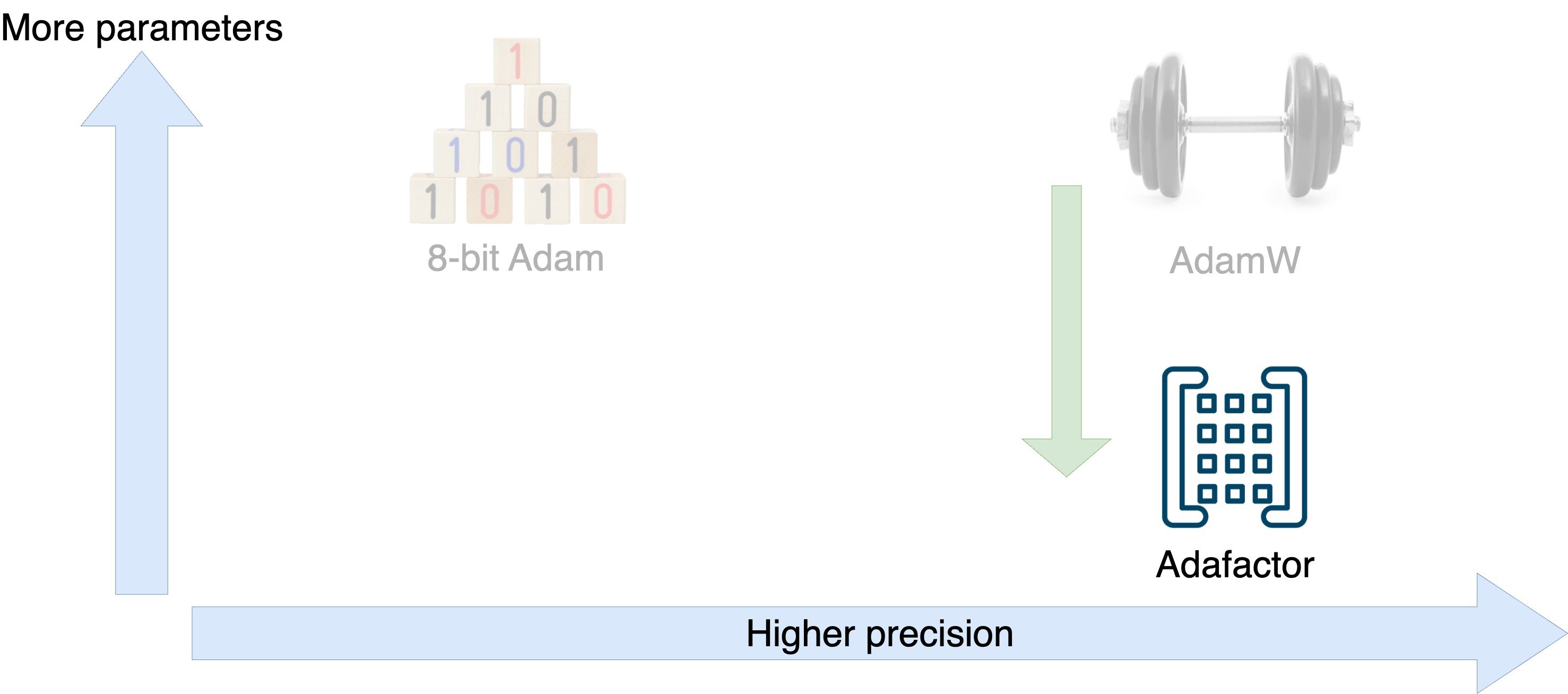
Optimizer tradeoffs
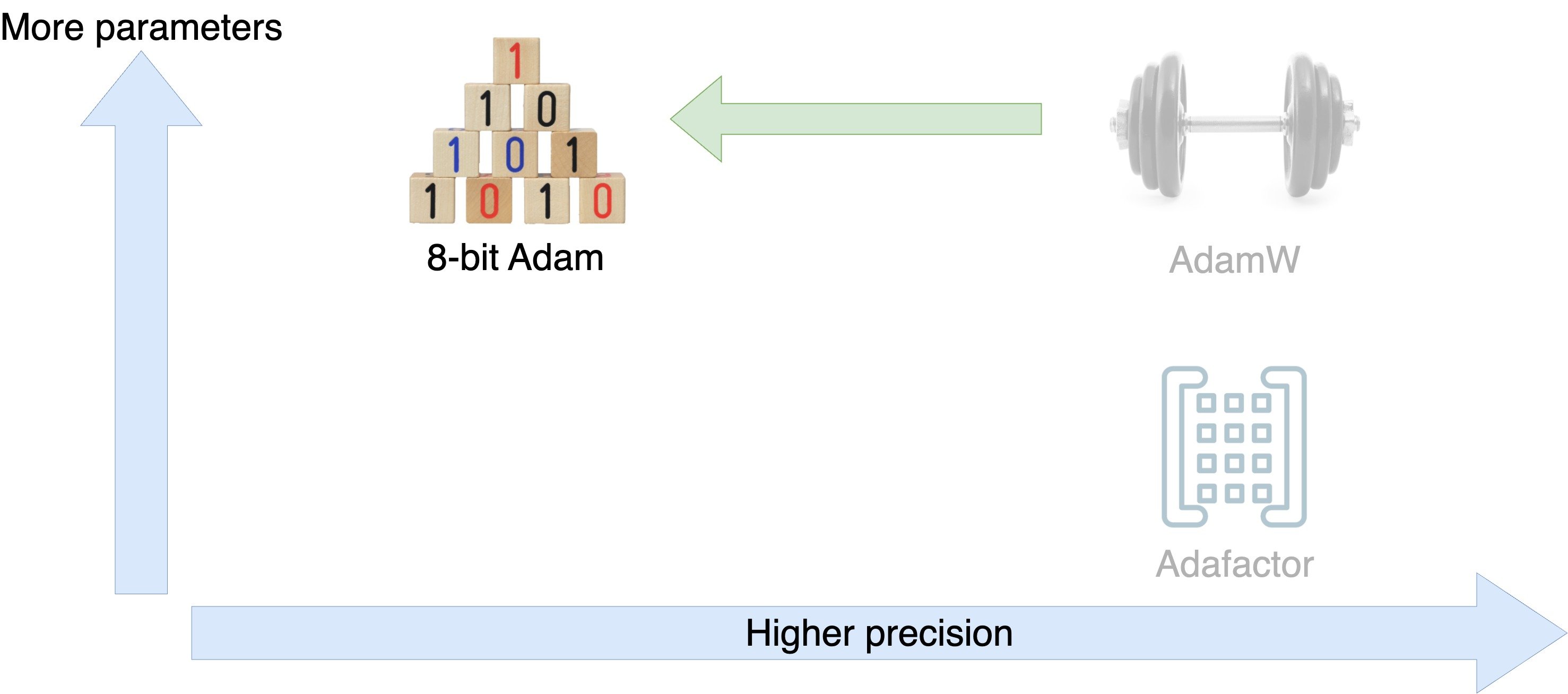
Optimizer tradeoffs
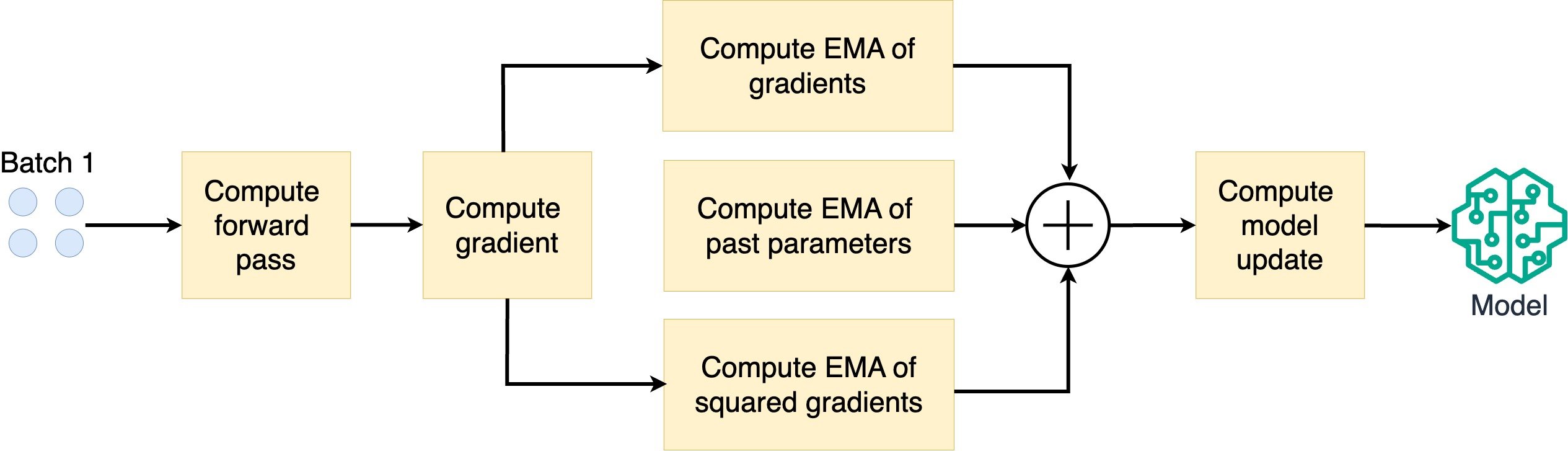
How does AdamW work?
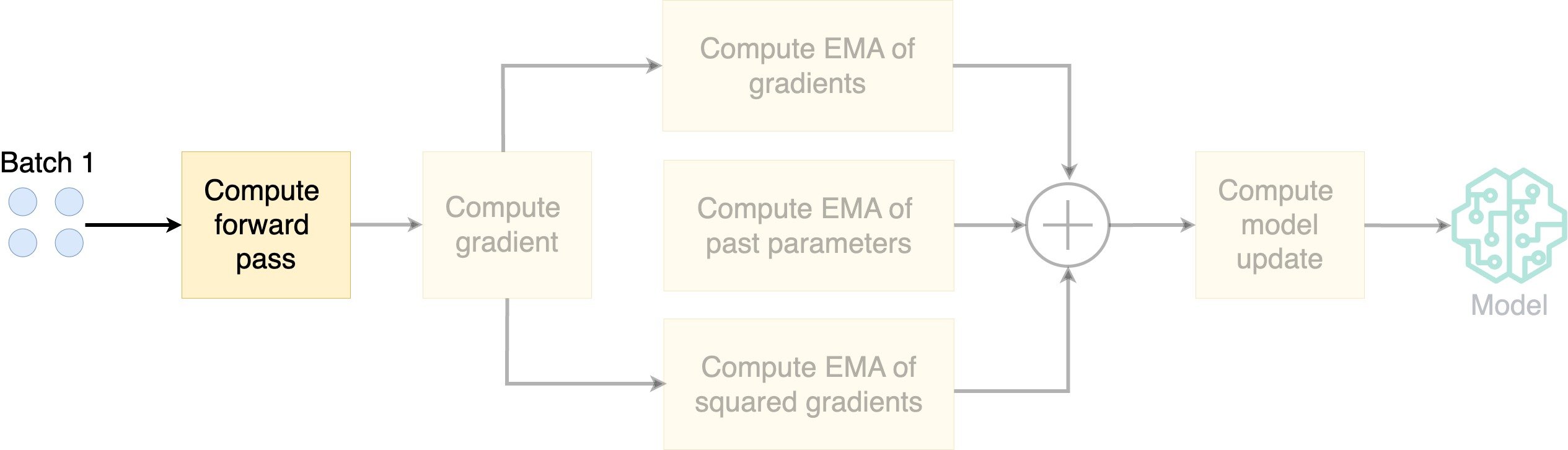
How does AdamW work?
How does AdamW work?
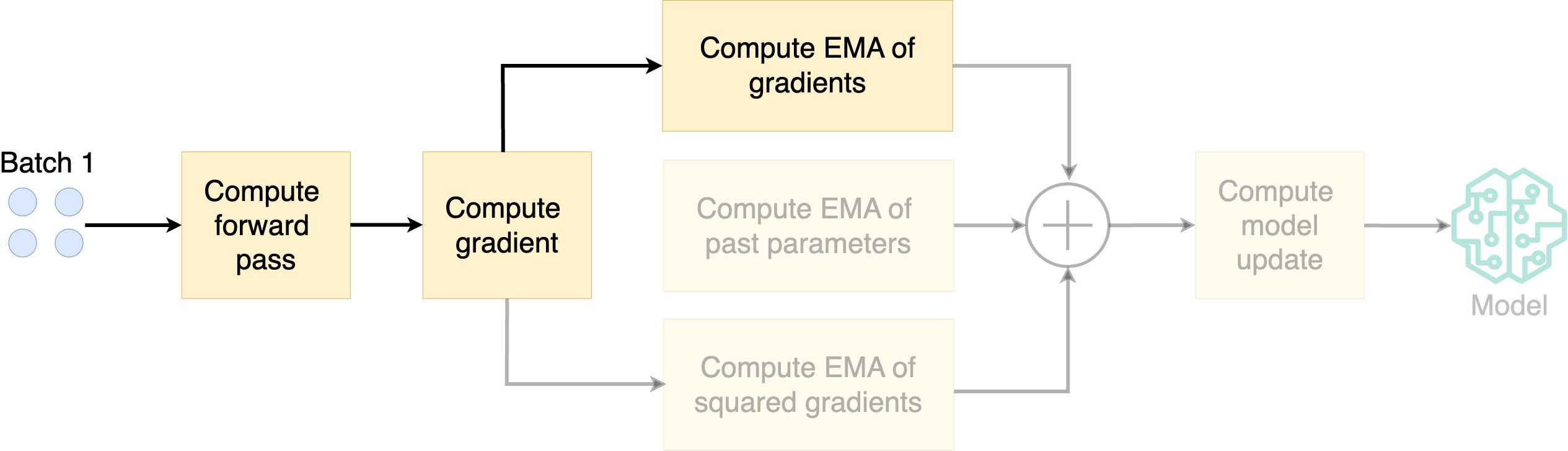
- Compute the exponential moving average (EMA) of the gradients
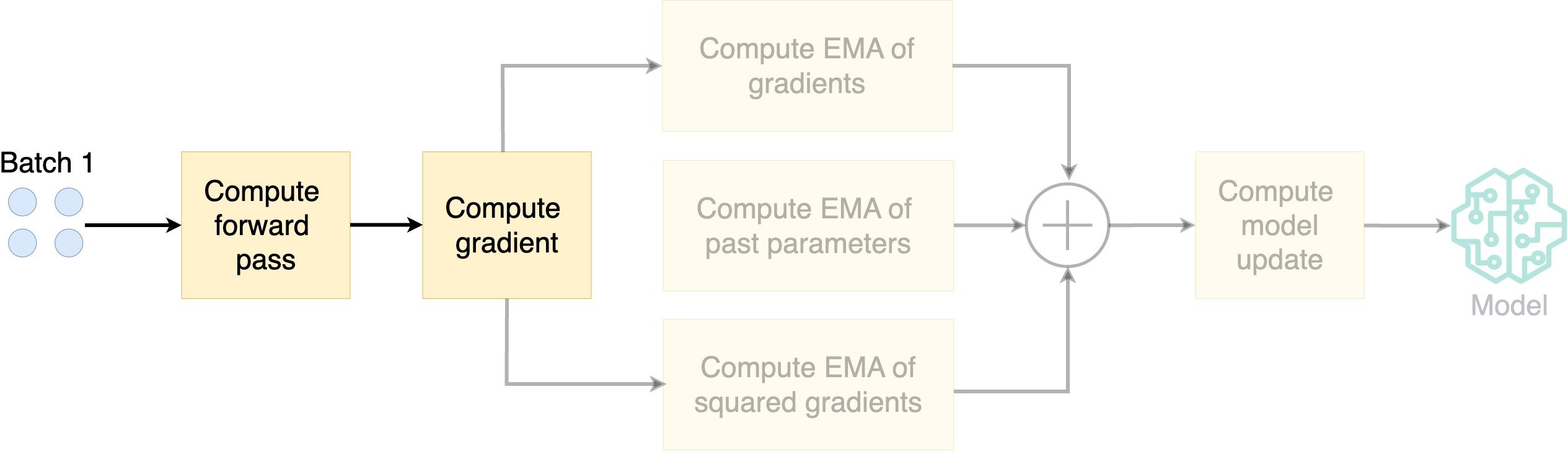
How does AdamW work?
- Compute the exponential moving average (EMA) of the gradients
- Compute EMA of squared gradients
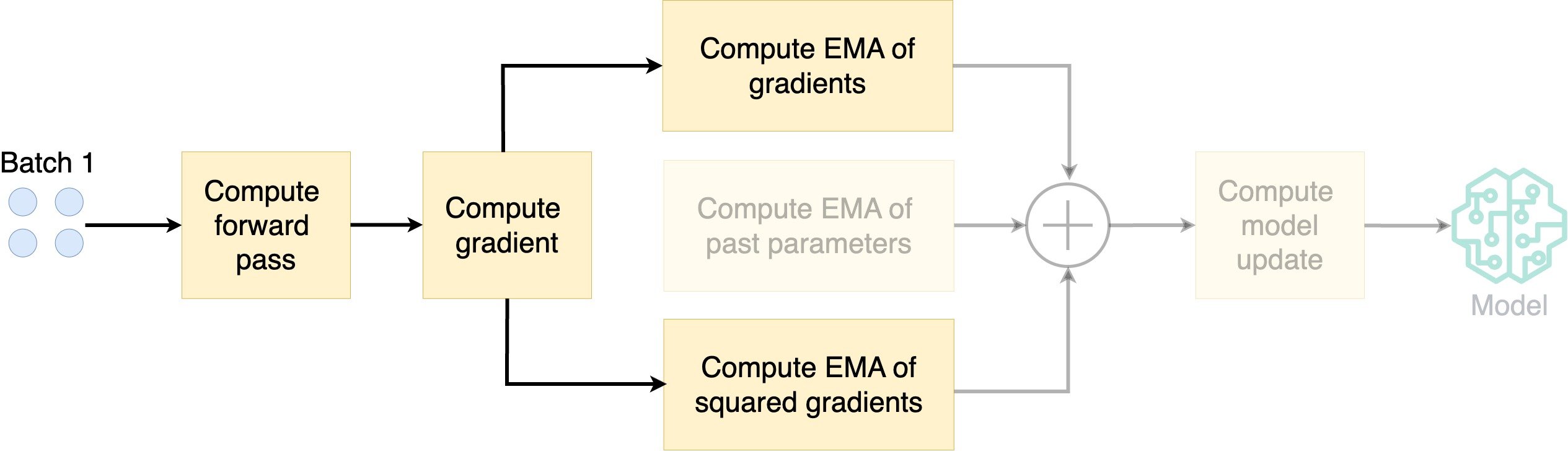
How does AdamW work?
- Compute the exponential moving average (EMA) of the gradients
- Compute EMA of squared gradients
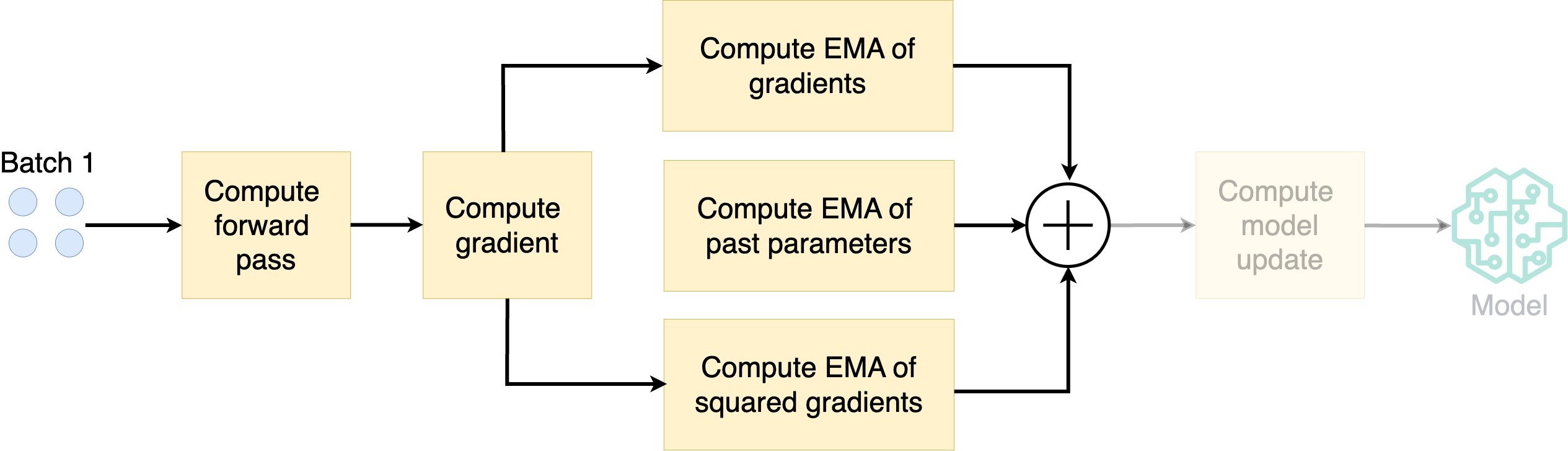
How does AdamW work?
- Compute the exponential moving average (EMA) of the gradients
- Compute EMA of squared gradients
Memory usage of AdamW
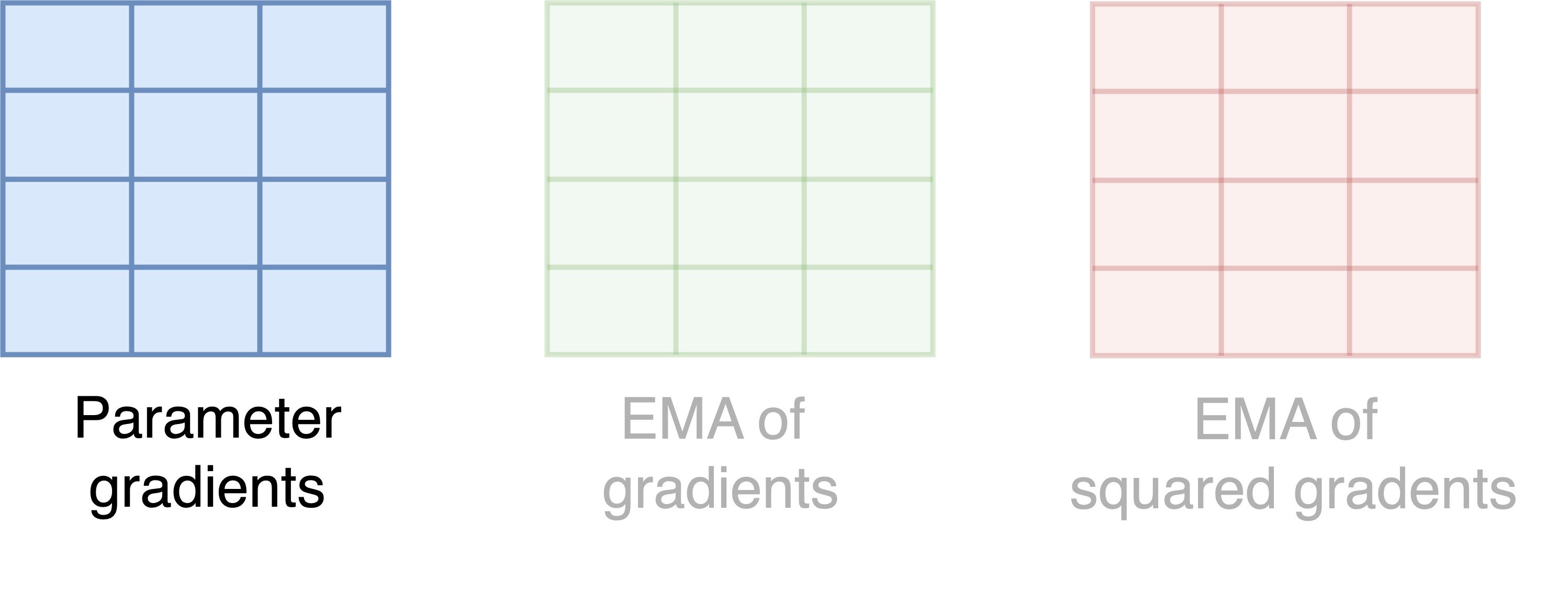
- Each square is a parameter, and each color is a state
Memory usage of AdamW
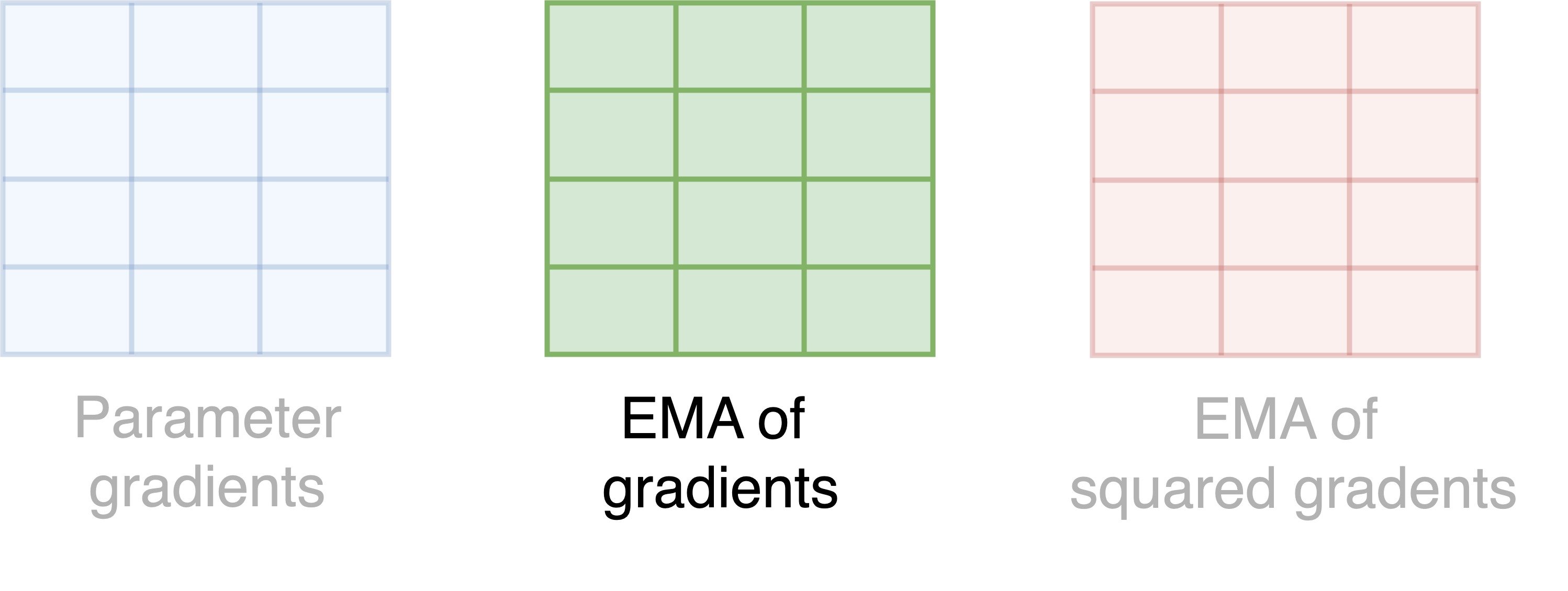
- Each square is a parameter, and each color is a state
Memory usage of AdamW
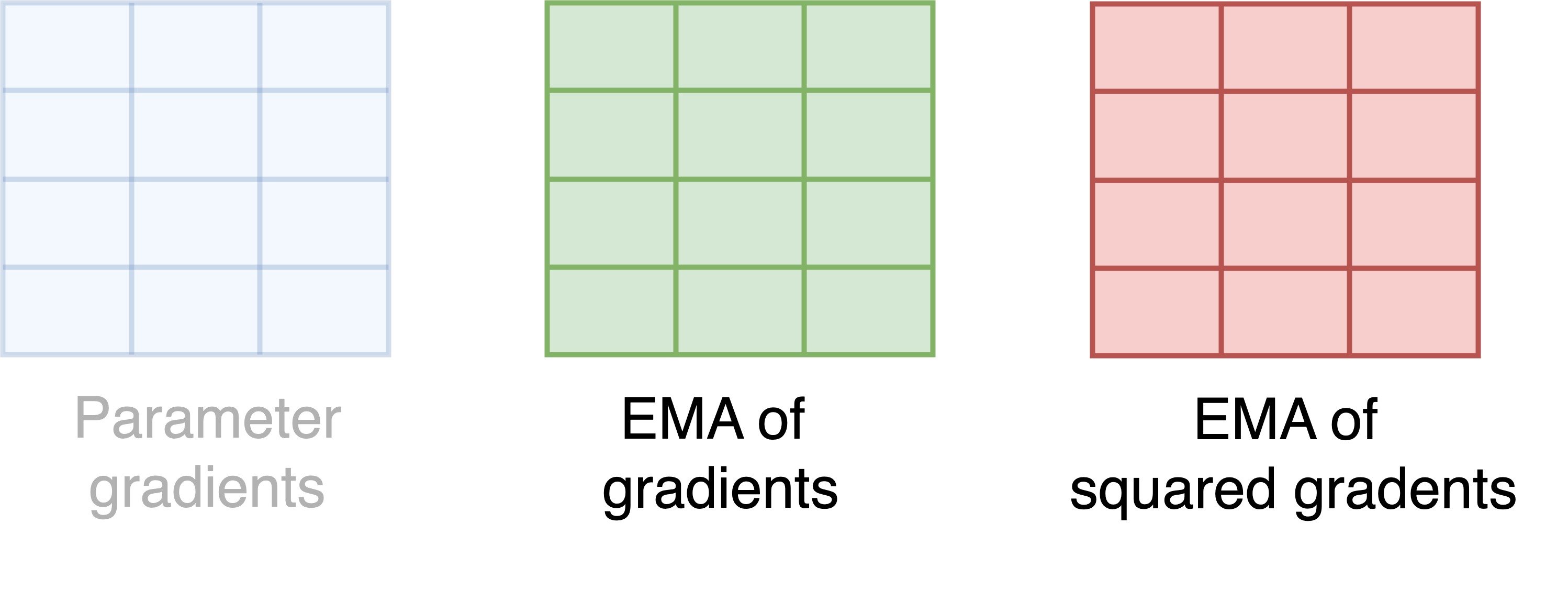
- Each square is a parameter, and each color is a state
- Memory per parameter = 8 bytes = 4 bytes per state * 2 states
- Total memory = Memory per parameter (8 bytes) * Number of parameters
Trainer and Accelerator