Data Engineering in Microsoft Fabric
Transform and Analyze Data with Microsoft Fabric

Luis Silva
Solution Architect - Data & AI
Data Analytics End To End
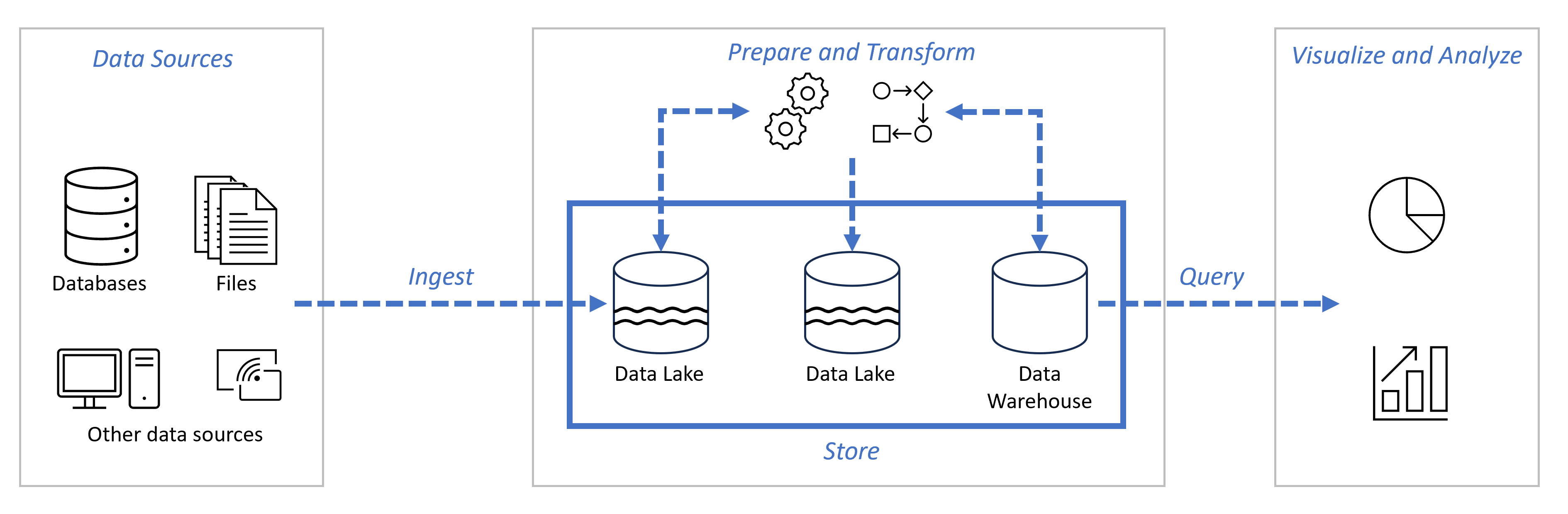
Data Factory
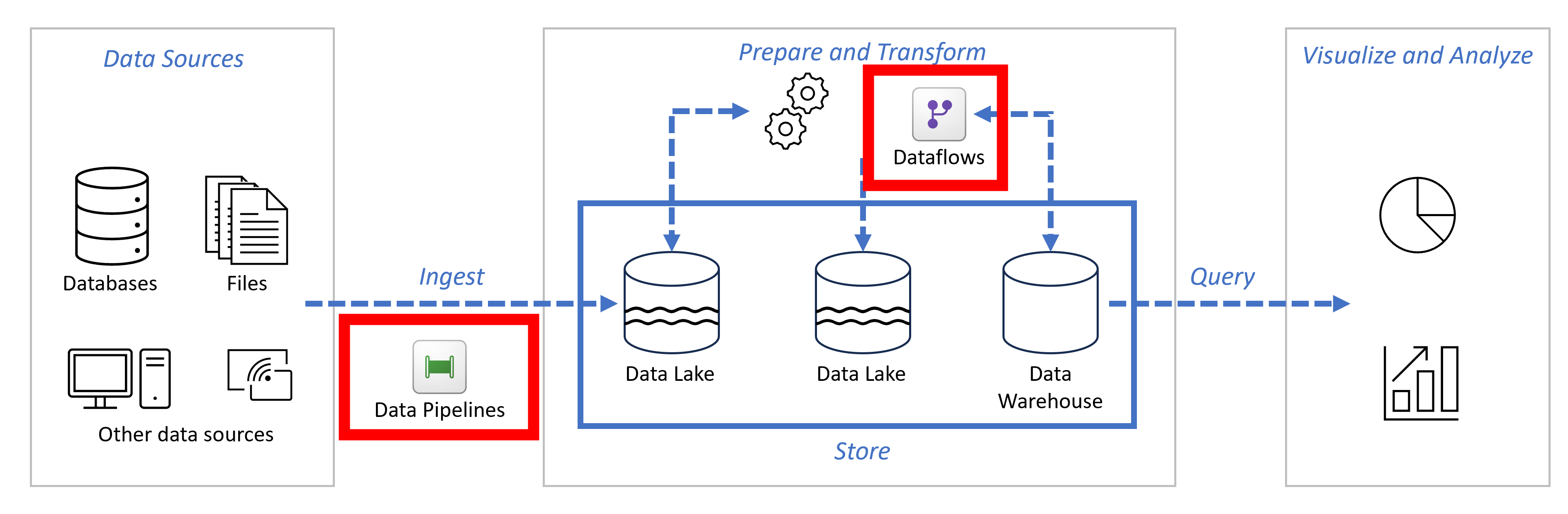
Dataflows

Data Pipelines
Synapse Data Engineering
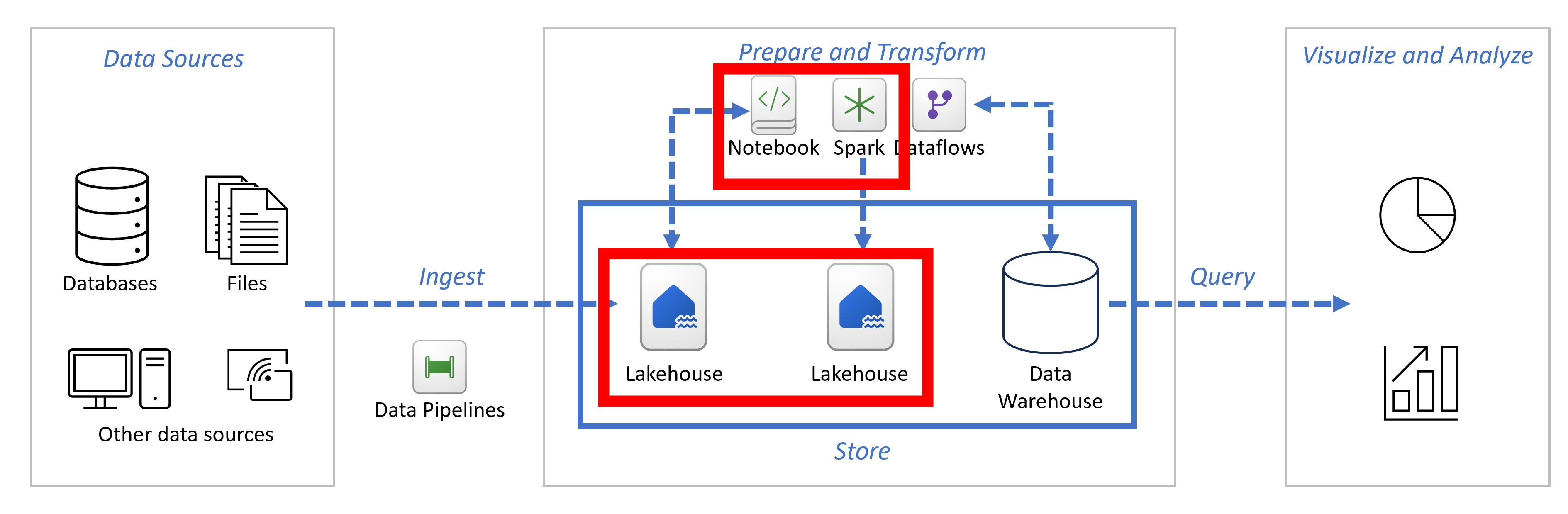
Lakehouses

Notebooks
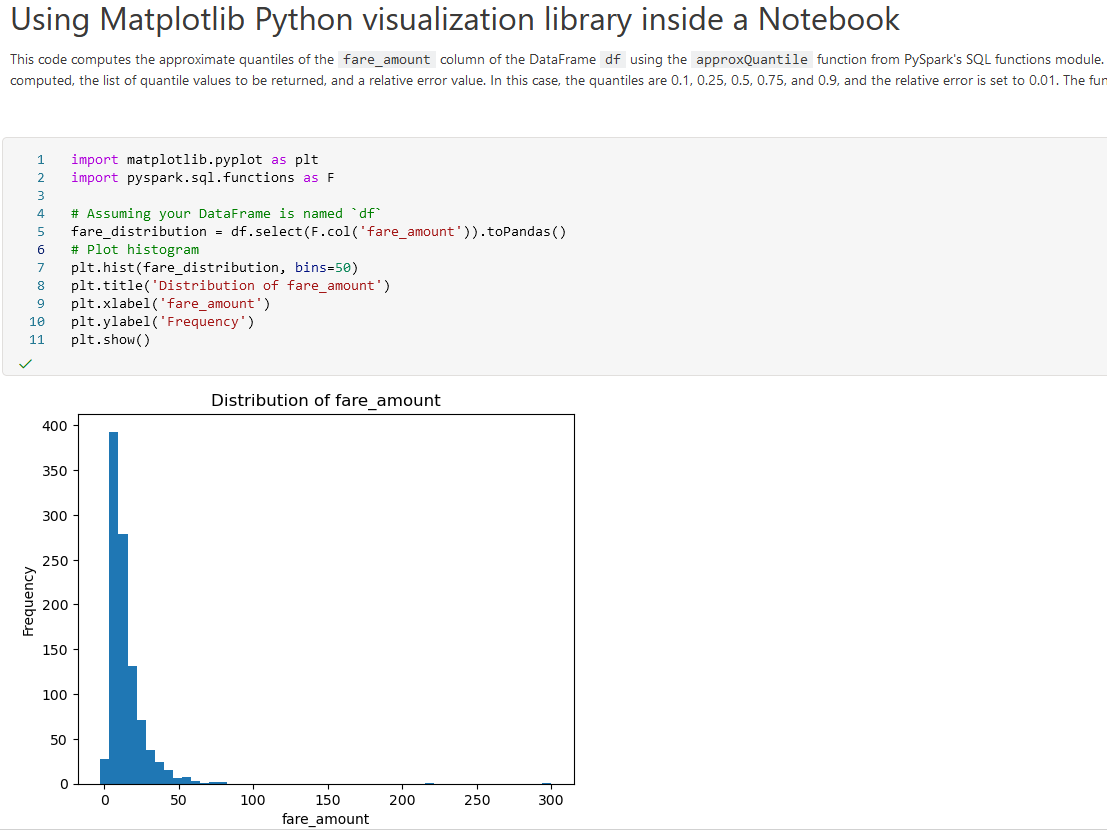
Apache Spark Job Definitions
Synapse Data Warehouse

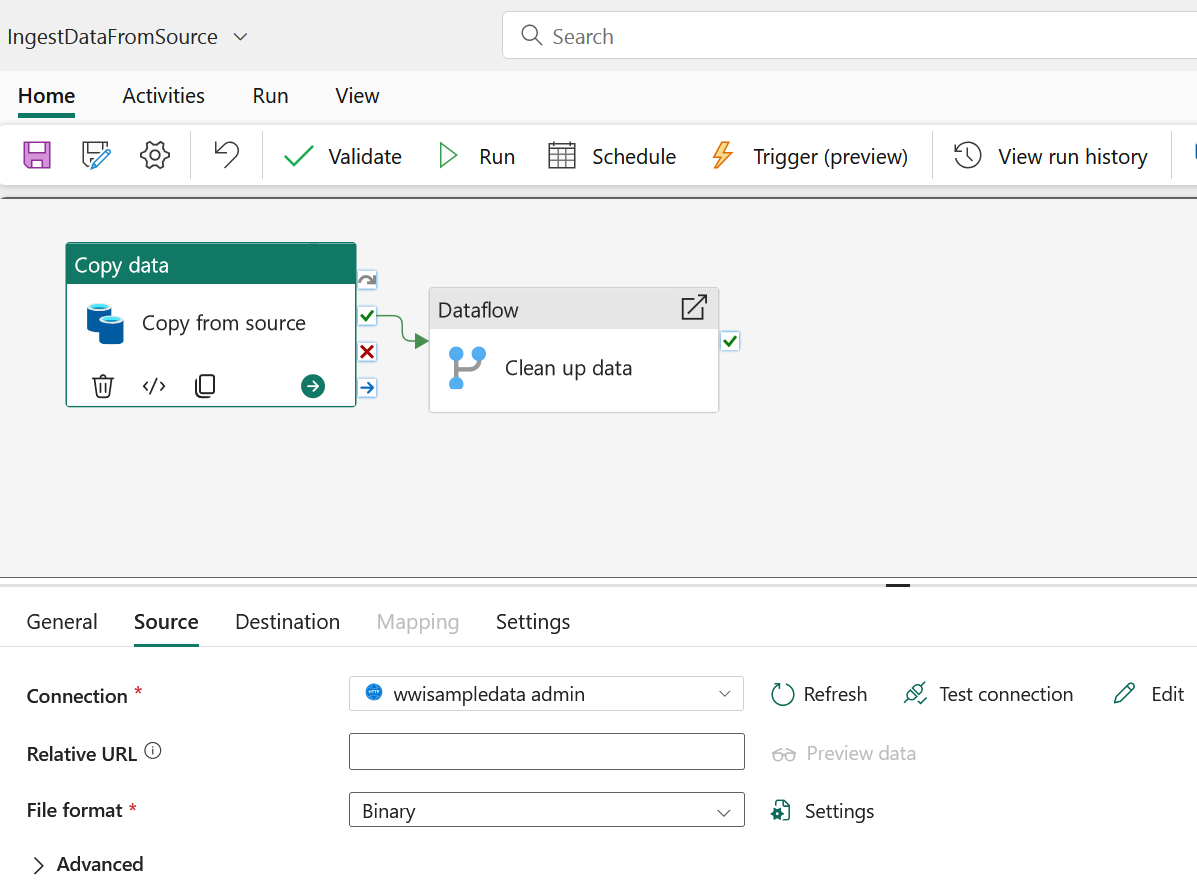
Choosing a Data Copy Tool

Choosing a Data Copy Tool
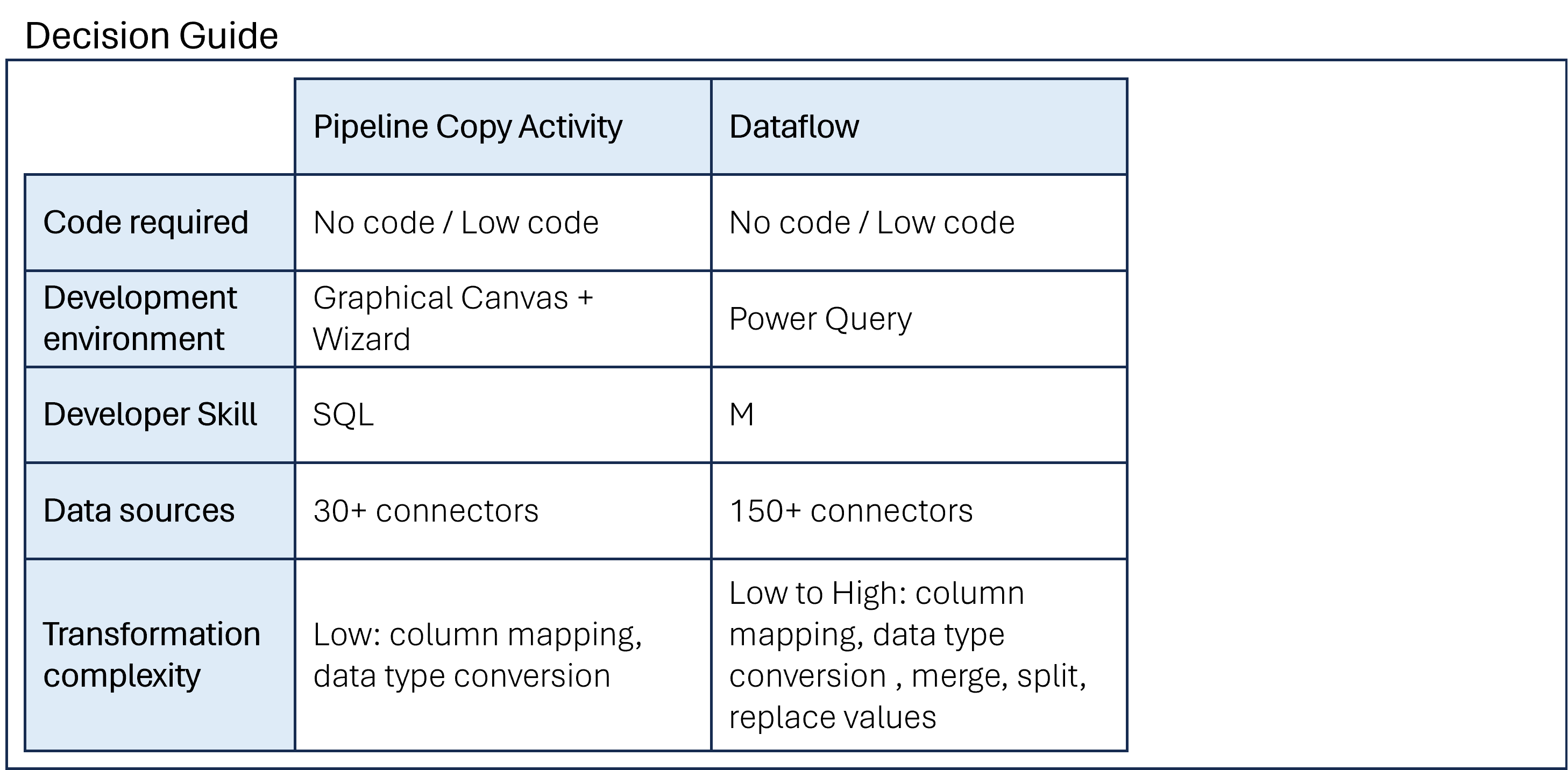
Choosing a Data Copy Tool


