Delta Lake table optimization
Transform and Analyze Data with Microsoft Fabric

Luis Silva
Solution Architect - Data & AI
What is Delta Lake?
- Open source storage layer for lakehouses
- ACID transactions, metadata handling and versioning
- Fabric uses Delta Lake table format (Parquet) as the standard
- Interoperability across Fabric experiences

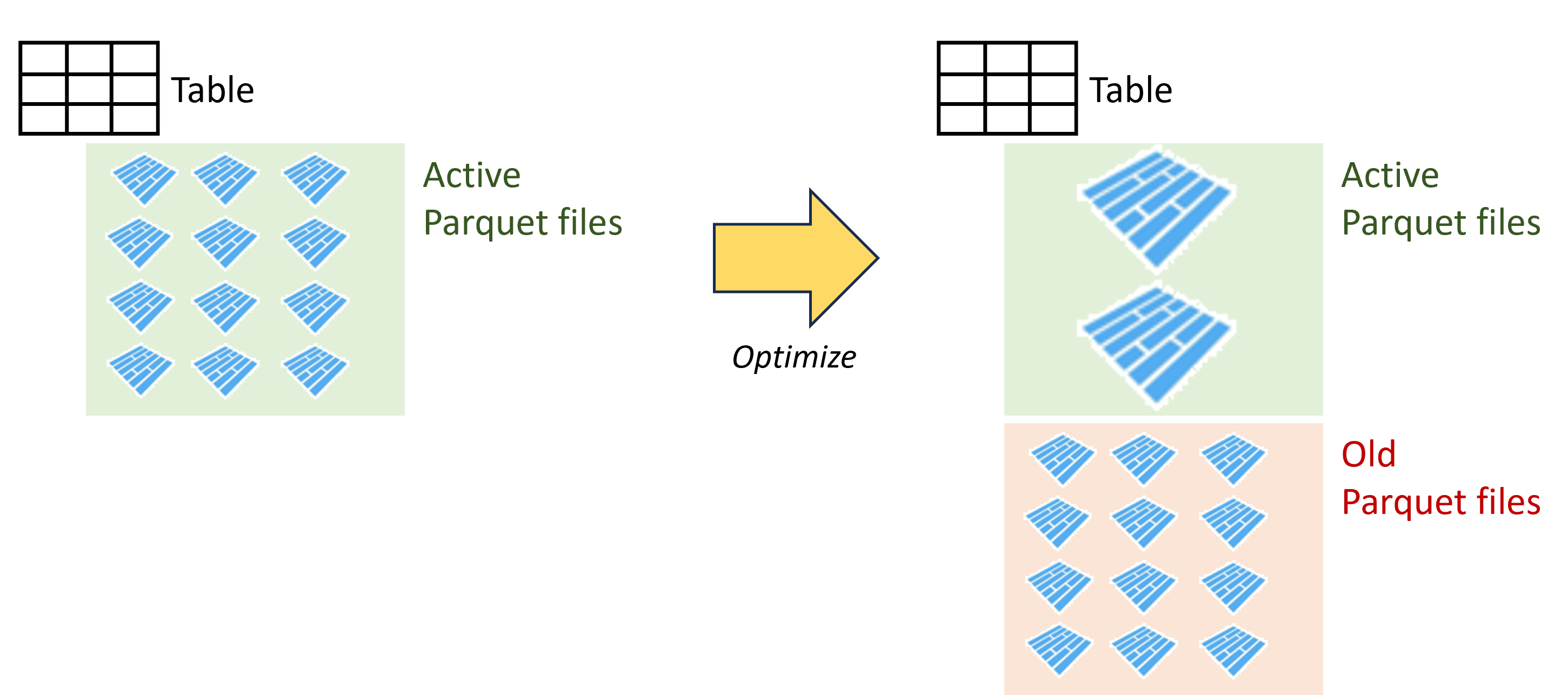
Optimize
- Consolidate multiple small Parquet files into a large file
- Ideal file size between 128MB and 1GB
- Improve compression and distribution, leading to efficient reads
- Recommended to optimize after loading large tables
Optimize
- Consolidate multiple small Parquet files into a large file
- Ideal file size between 128MB and 1GB
- Improve compression and distribution, leading to efficient reads
- Recommended to optimize after loading large tables
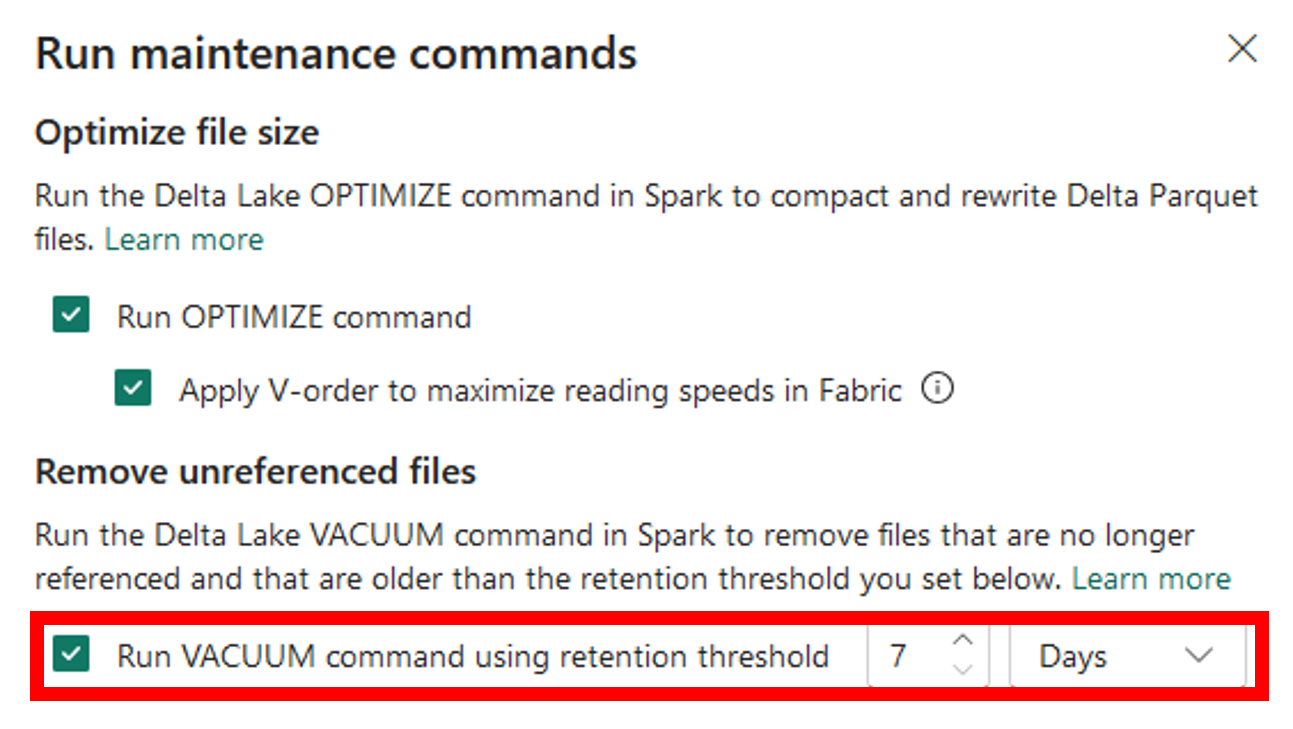
Running the Optimize command from Lakehouse explorer
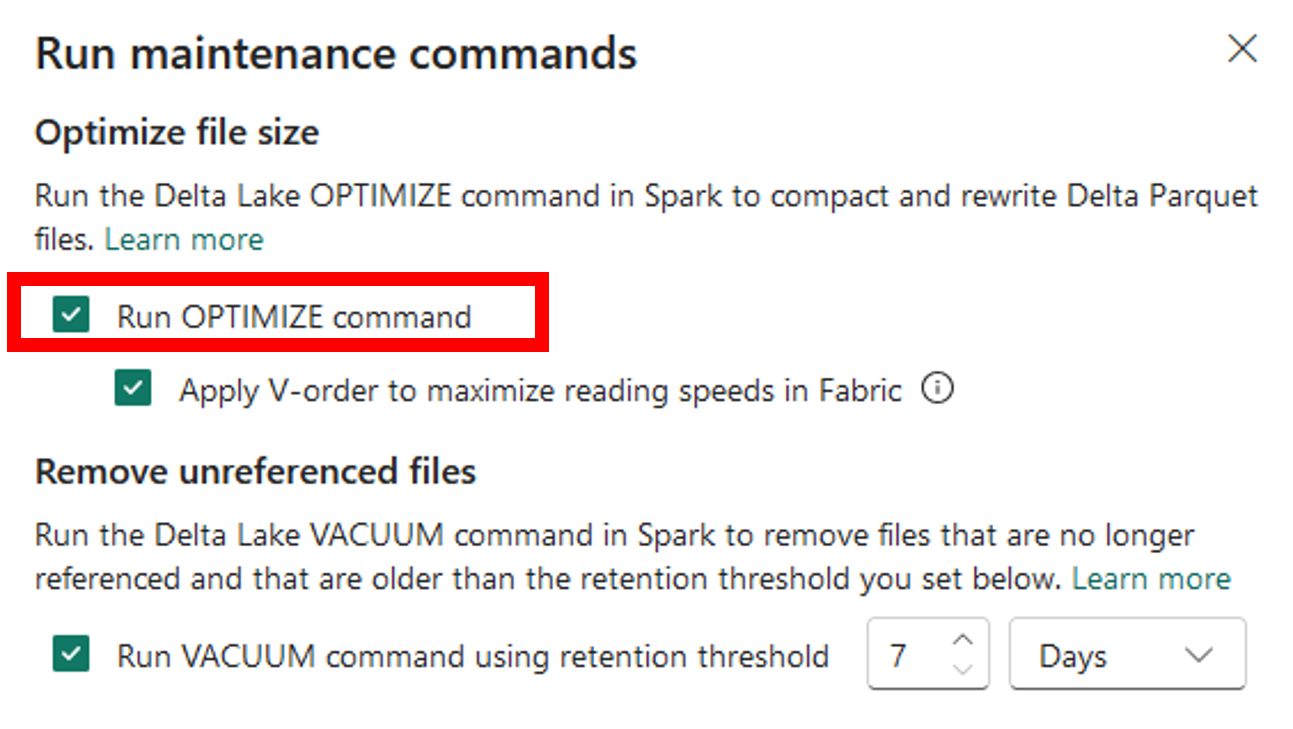
Applying V-Order from Lakehouse explorer
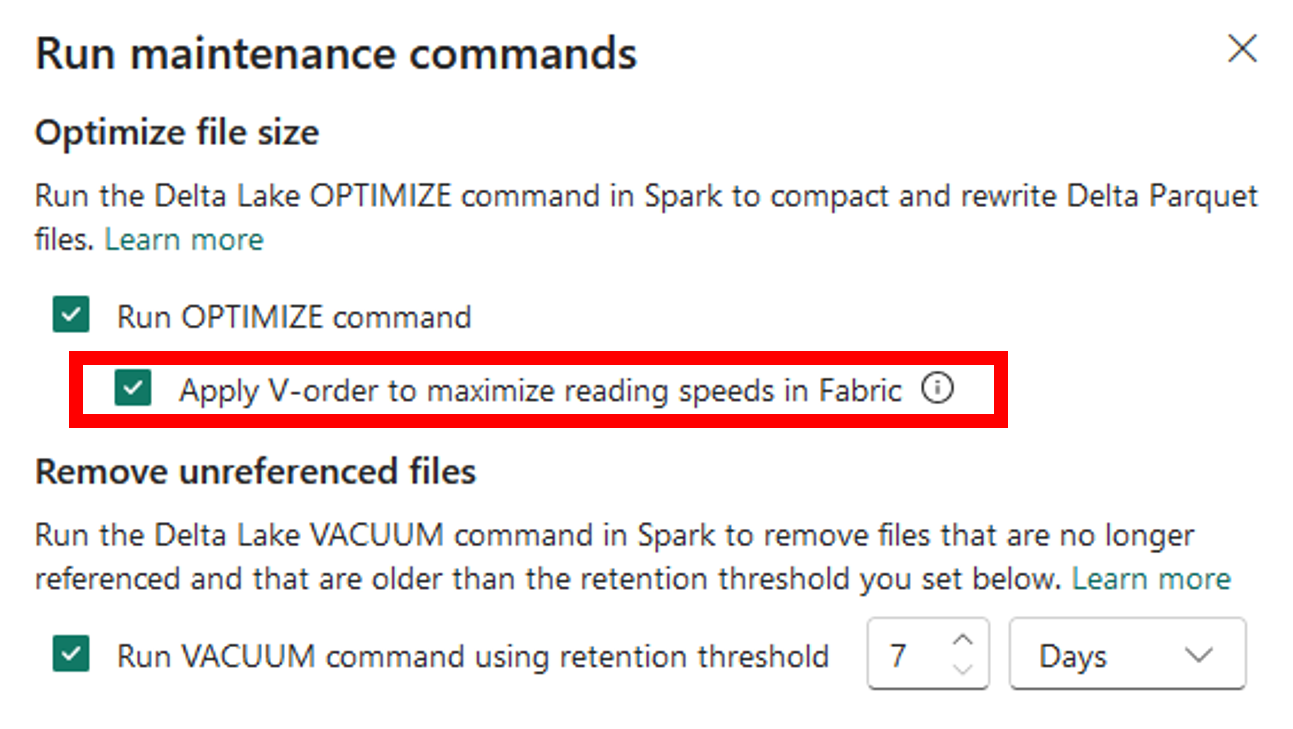
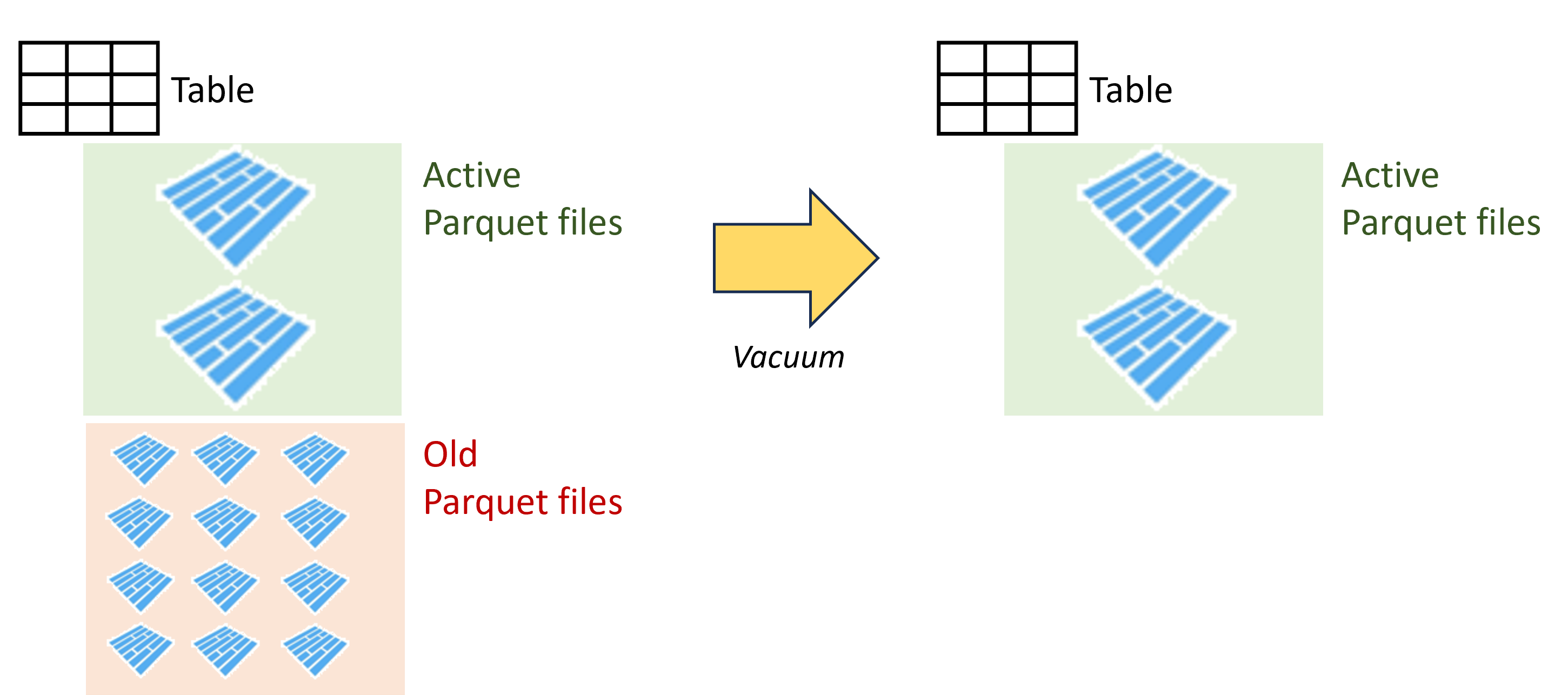
Vacuum
- Remove older files that are no longer needed and that are older than the retention threshold
- Reduce cloud storage costs
Vacuum
- Remove older files that are no longer needed and that are older than the retention threshold
- Reduce cloud storage costs
Running Vacuum from Lakehouse explorer