Methods for high-quality feedback gathering
Reinforcement Learning from Human Feedback (RLHF)

Mina Parham
AI Engineer
Methods for high-quality feedback gathering
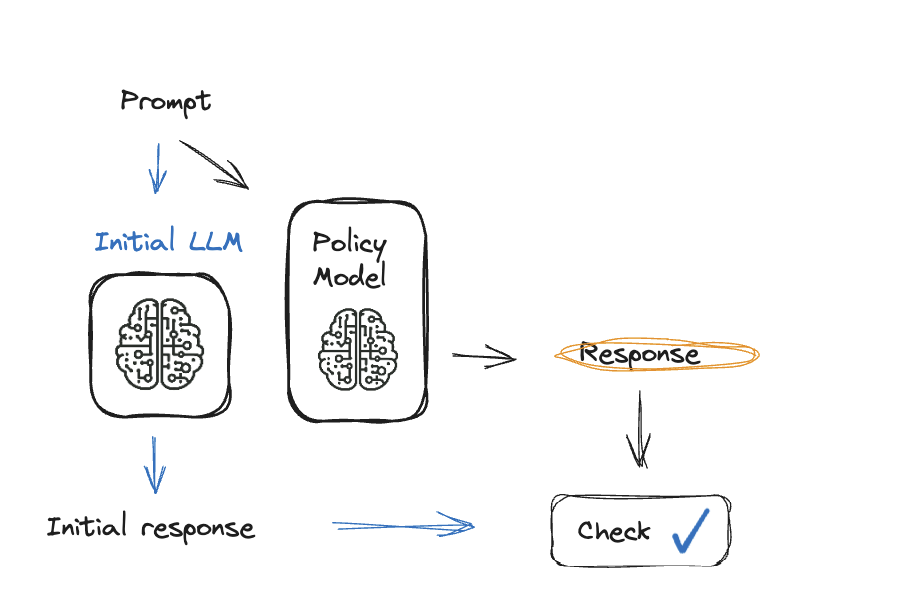
Methods for high-quality feedback gathering

Pairwise comparisons

Ratings

Psychological factors

Guidelines for collecting high-quality feedback


