Reward models explored
Reinforcement Learning from Human Feedback (RLHF)

Mina Parham
AI Engineer
Process so far
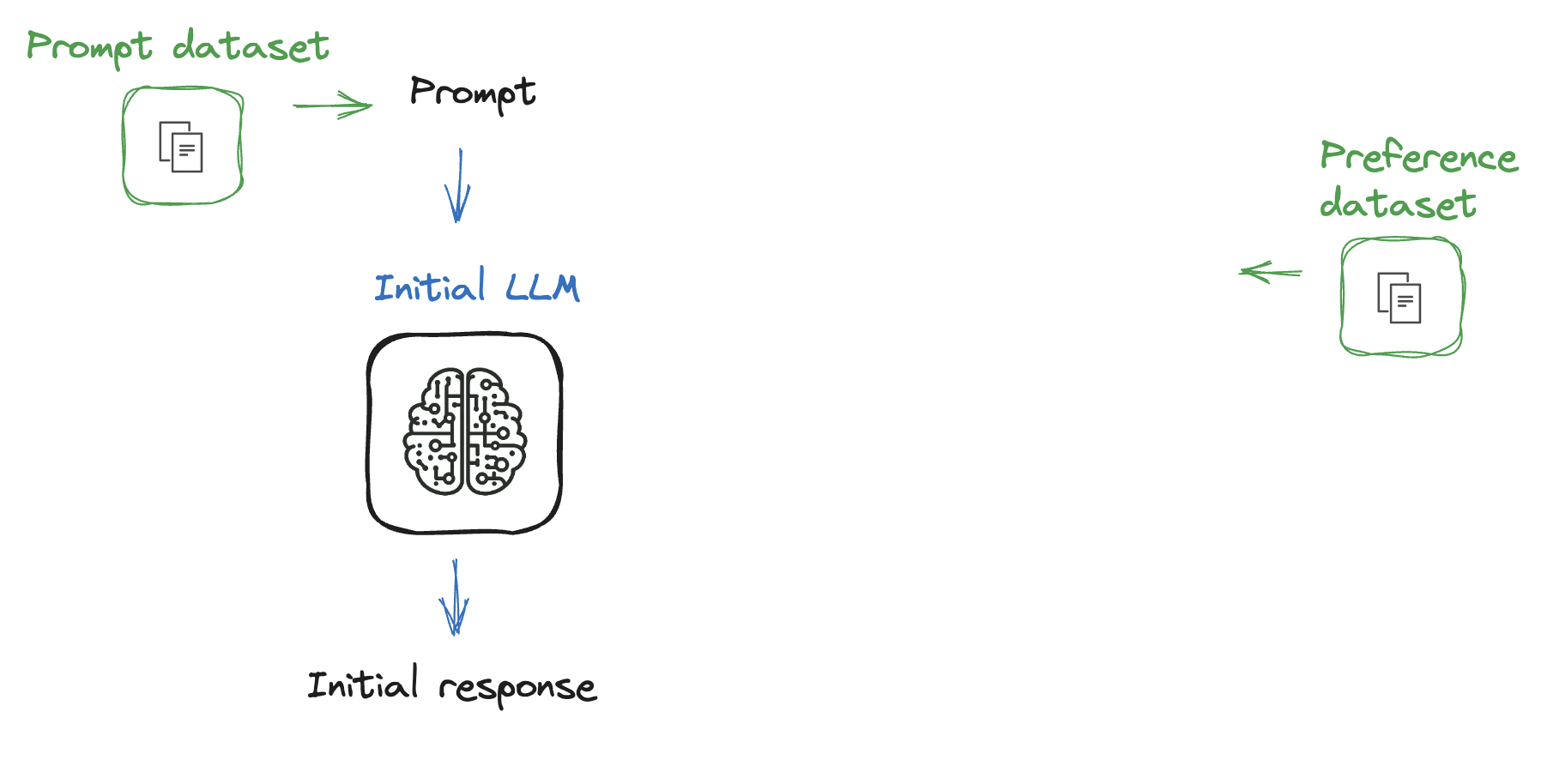
Process so far

What is a reward model?
What is a reward model?
- Model informs the agent
- Agent evaluates the model to maximize rewards


