Efficient fine-tuning in RLHF
Reinforcement Learning from Human Feedback (RLHF)

Mina Parham
AI Engineer
Parameter-efficient fine-tuning
- Fine-tuning a full model
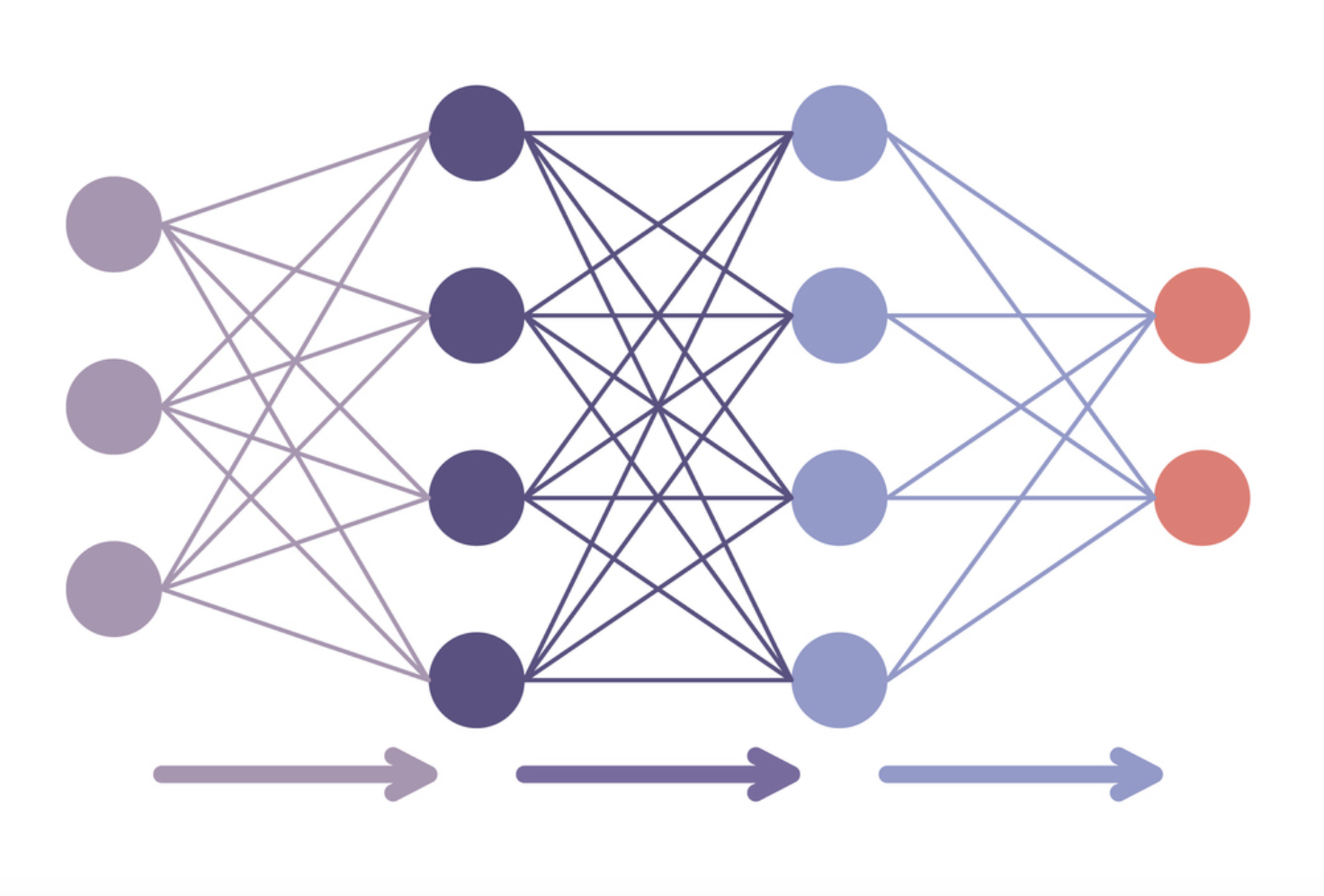
Parameter-efficient fine-tuning
- Fine-tuning with PEFT
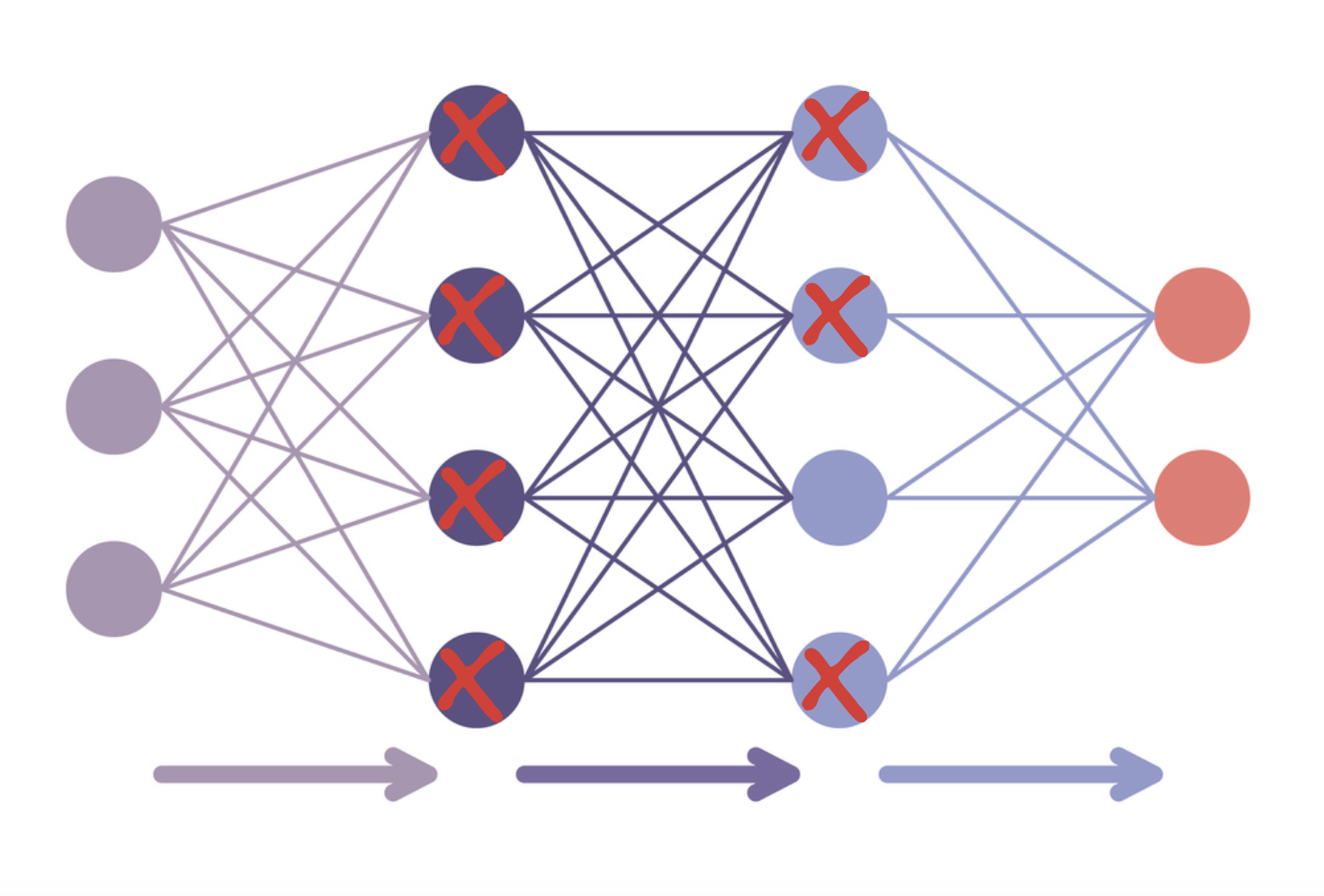
- LoRA: adjusts only a few layers
- Quantization: lowers data type precision

