Exploring pre-trained LLMs
Reinforcement Learning from Human Feedback (RLHF)

Mina Parham
AI Engineer
The importance of fine-tuning
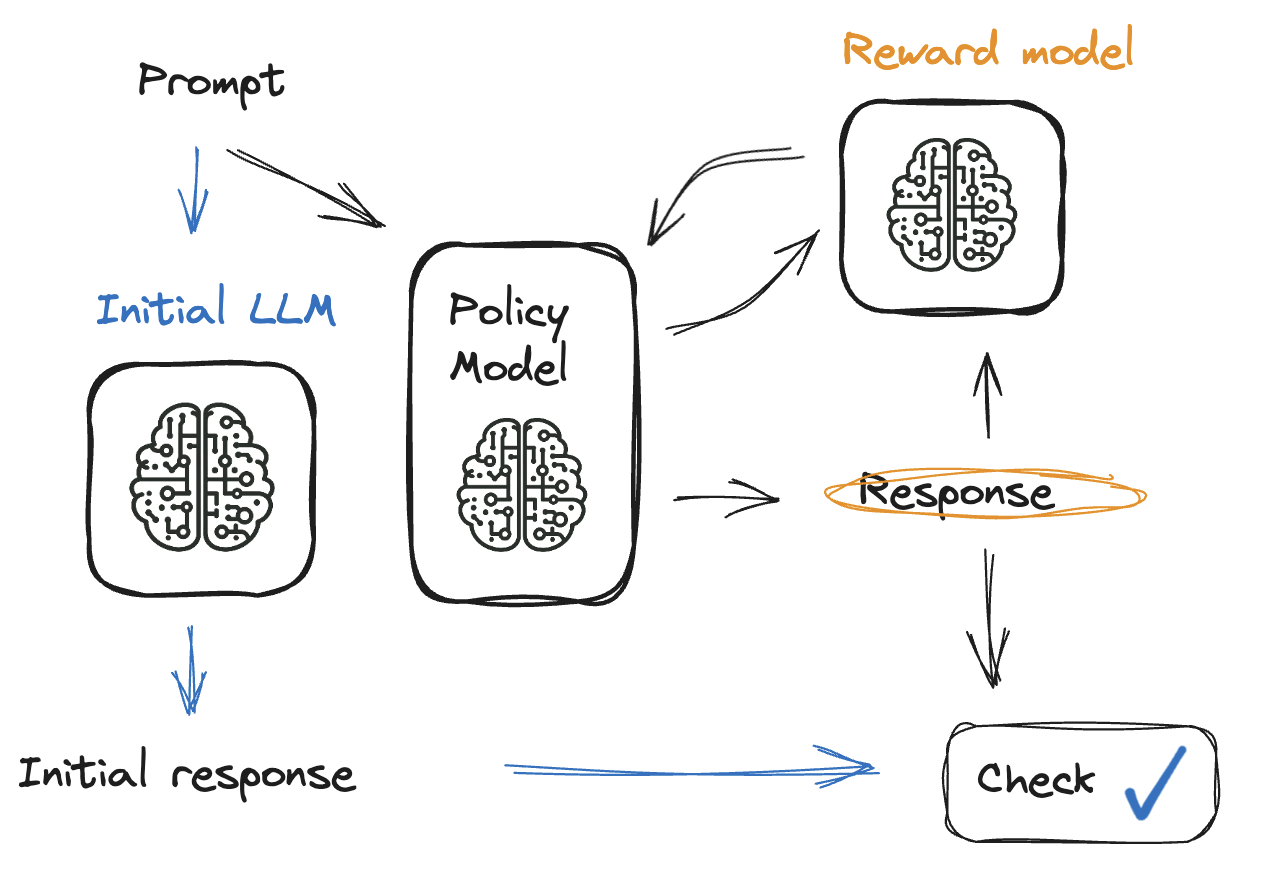
The importance of fine-tuning

A step-by-step guide to fine-tuning an LLM
A step-by-step guide to fine-tuning an LLM
A step-by-step guide to fine-tuning an LLM