Introduction to RLHF
Reinforcement Learning from Human Feedback (RLHF)

Mina Parham
AI Engineer
Welcome to the course!
- Topic: Reinforcement Learning from Human Feedback (RLHF)

Welcome to the course!
- Topic: Reinforcement Learning from Human Feedback (RLHF)
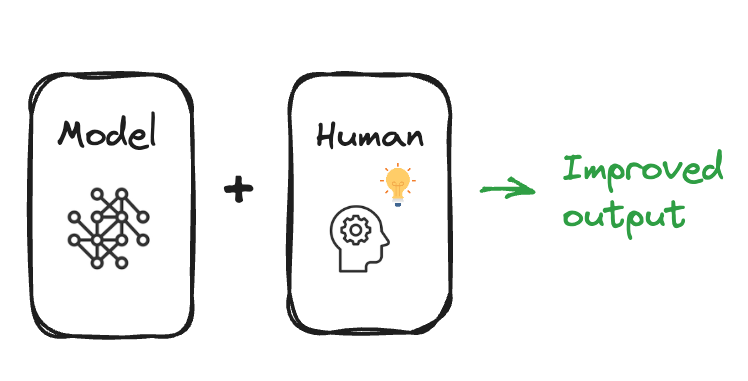
Reinforcement learning review
Reinforcement learning review

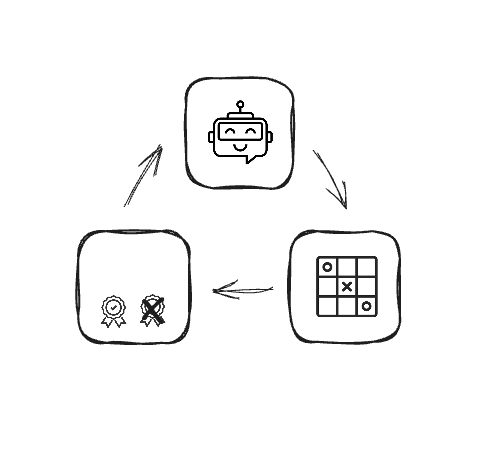
Reinforcement learning review
Reinforcement learning review
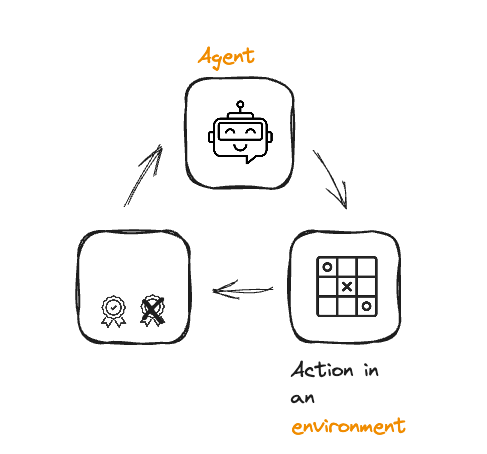
From RL to RLHF

From RL to RLHF
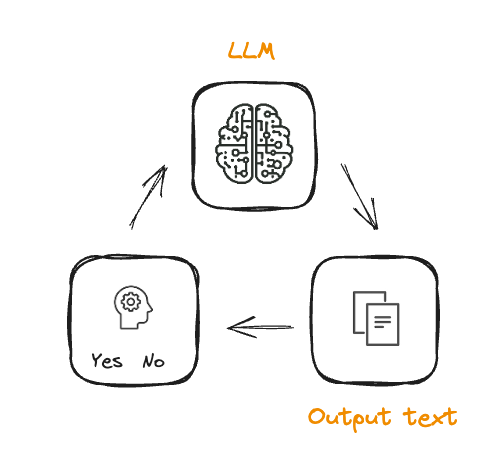
From RL to RLHF
- Training the reward model
- Alignment with human preferences

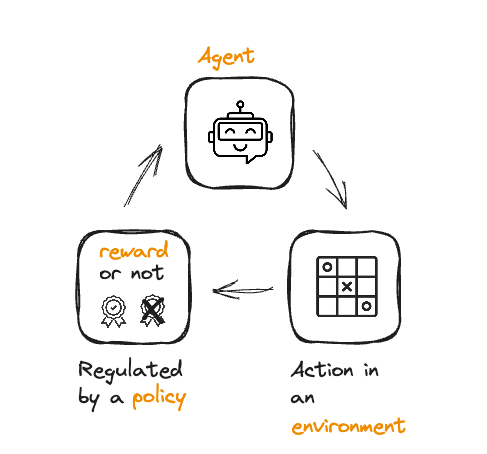
LLM fine-tuning in RLHF
LLM fine-tuning in RLHF

The full RLHF process

The full RLHF process

The full RLHF process

The full RLHF process

The full RLHF process
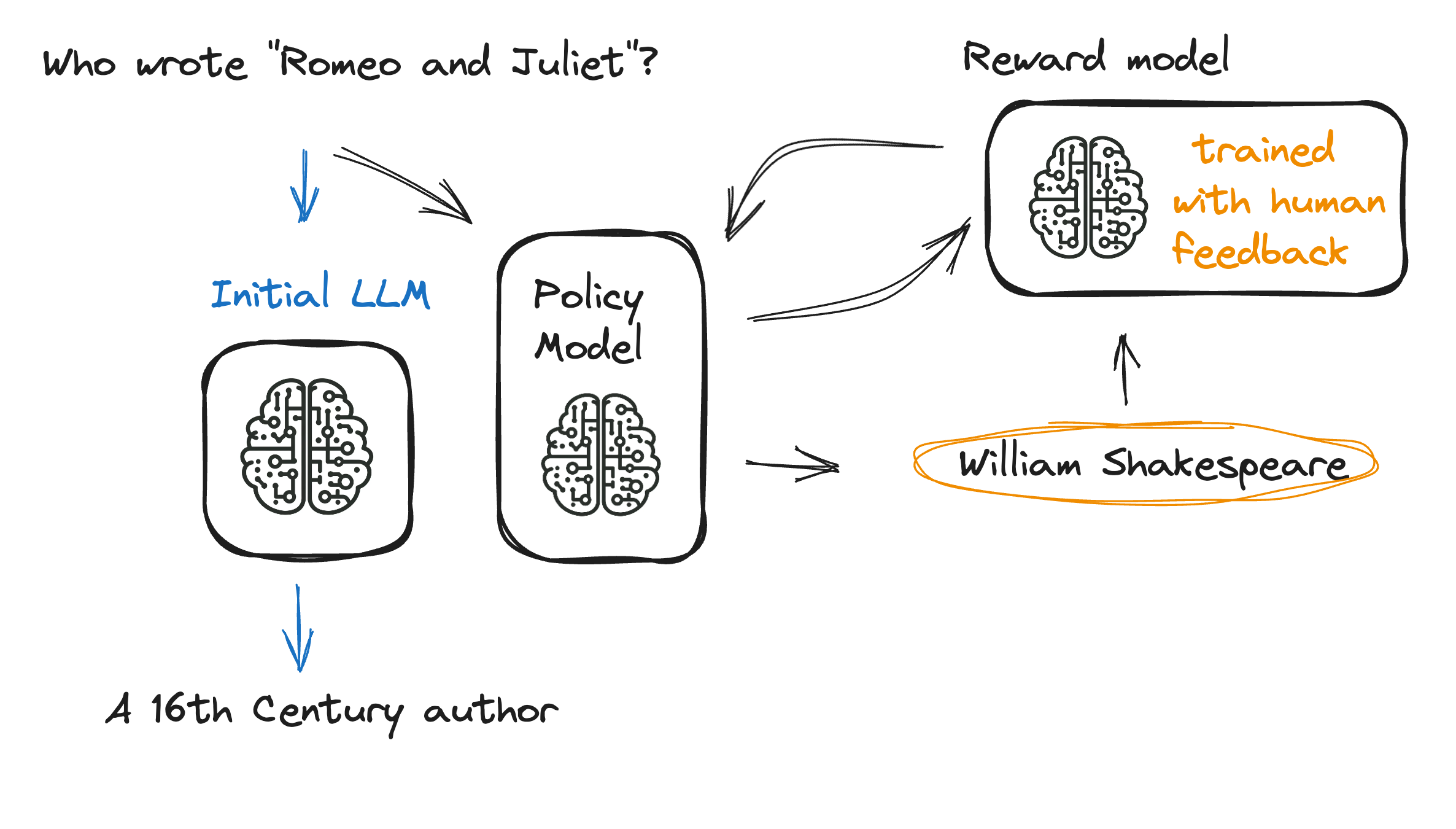
The full RLHF process


