Training with PPO
Reinforcement Learning from Human Feedback (RLHF)

Mina Parham
AI Engineer
Fine-Tuning with reinforcement learning
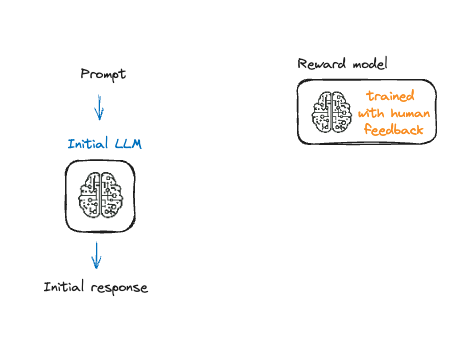
Fine-Tuning with reinforcement learning
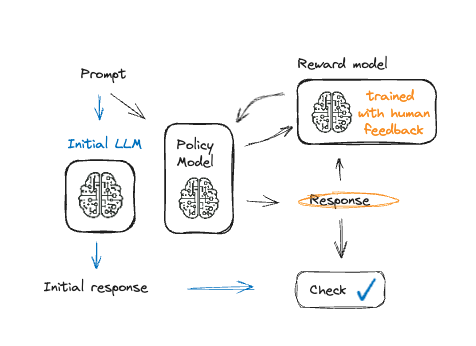
Fine-Tuning a Language Model with PPO
Fine-Tuning a Language Model with PPO
Fine-Tuning a Language Model with PPO
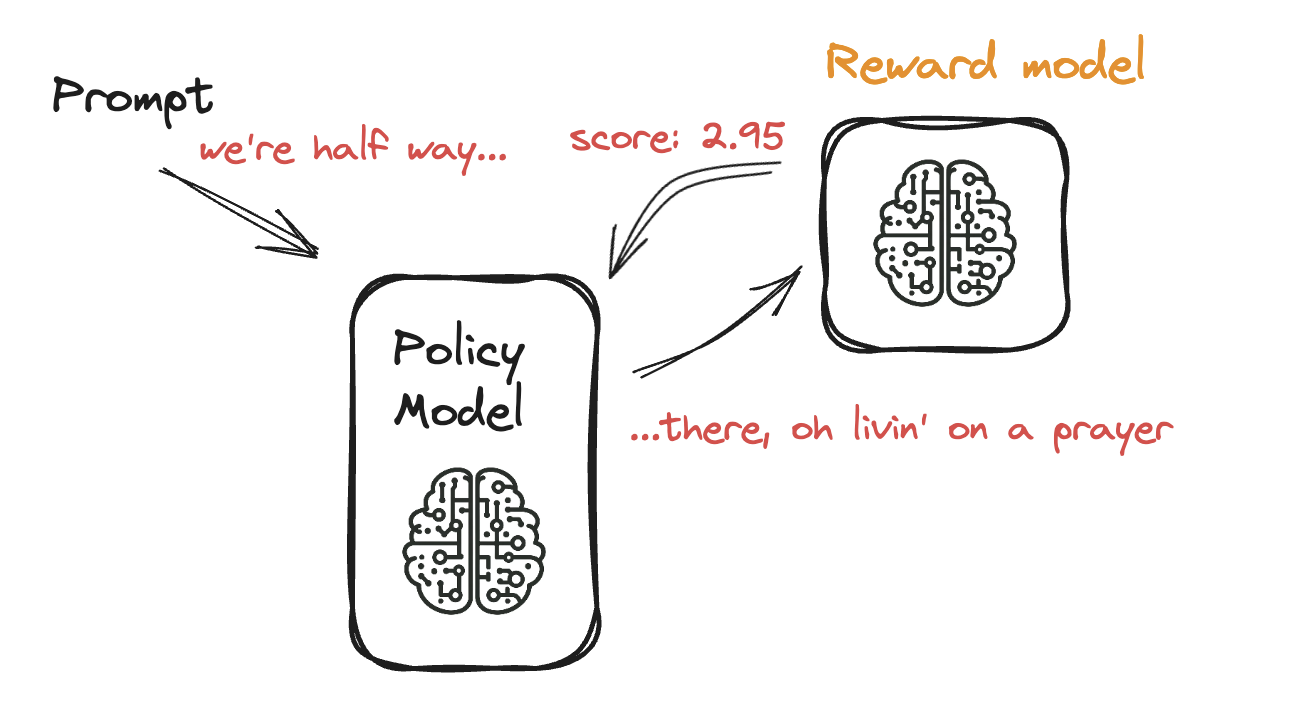
Fine-Tuning a Language Model with PPO
- PPO: gradual adjustment for the model
- Avoids overfitting to feedback


