Model metrics and adjustments
Reinforcement Learning from Human Feedback (RLHF)

Mina Parham
AI Engineer
Why use a reference model?

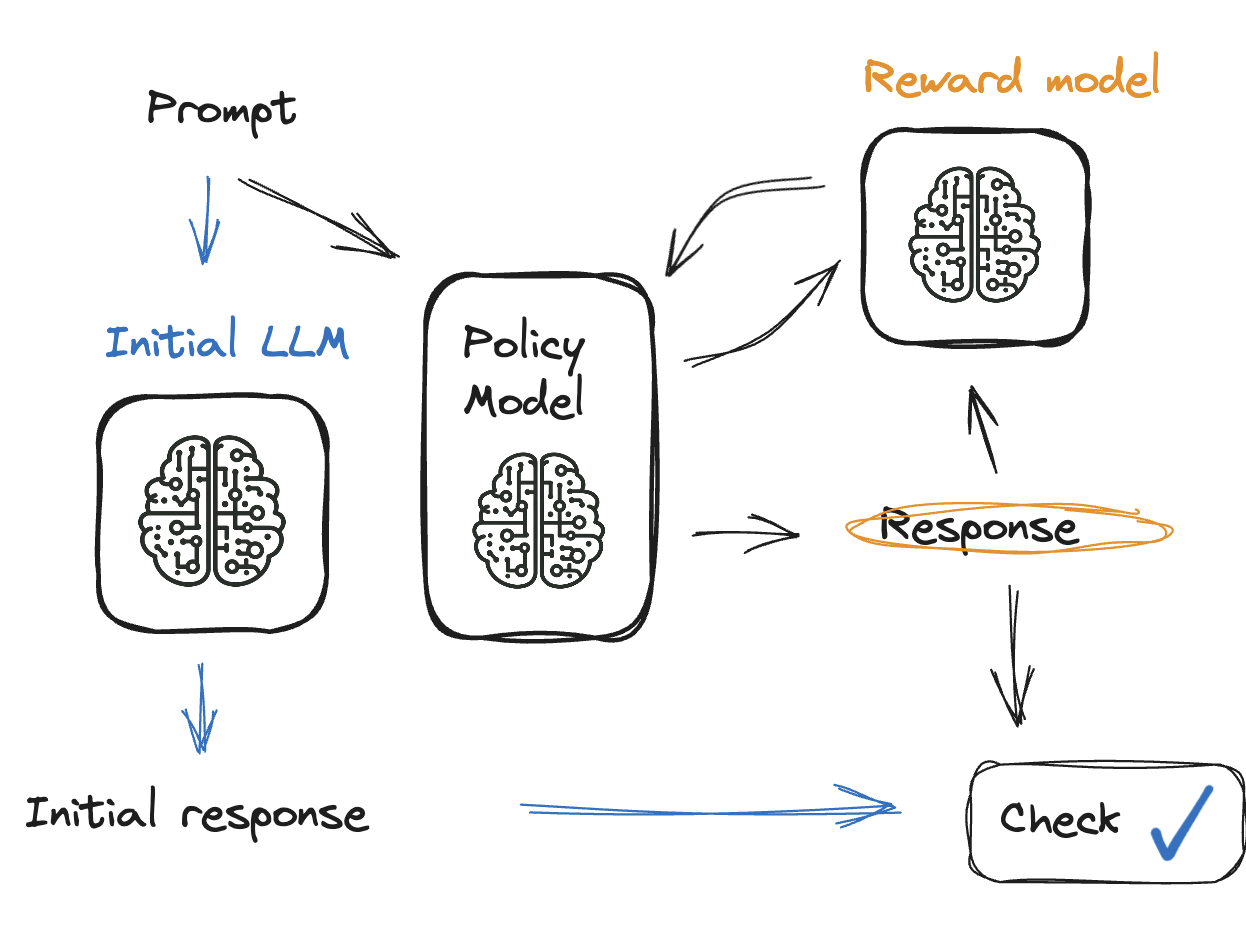
Checking model output
Solution: KL divergence
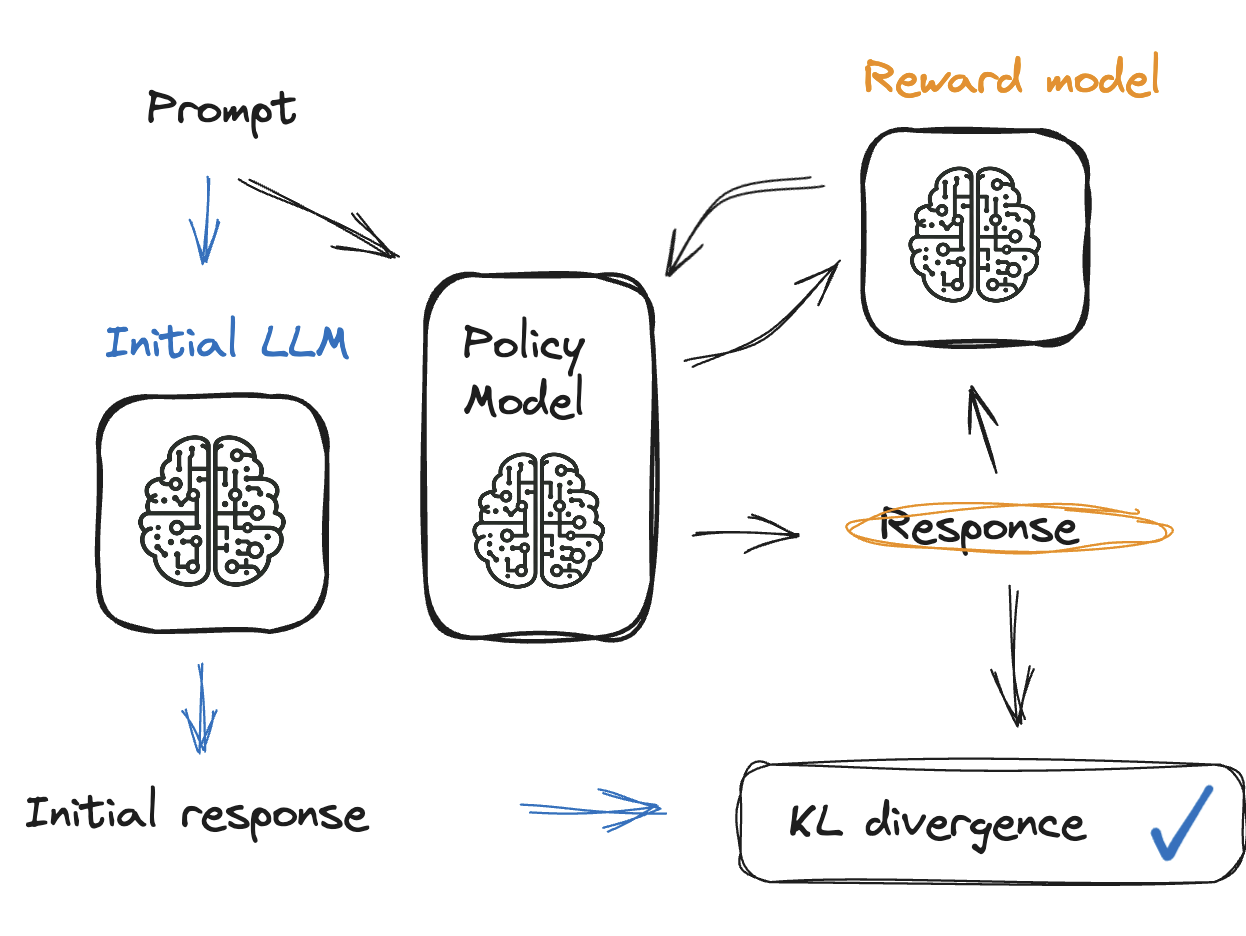
Solution: KL divergence
- Penalty is added to the reward model
- Penalty redirects the model if it produces unrelated outputs
- KL divergence compares current and reward model

- Between 0 and 10, and never negative

