Incorporating diverse feedback sources
Reinforcement Learning from Human Feedback (RLHF)

Mina Parham
AI Engineer
Improved model generalization

Reduced bias
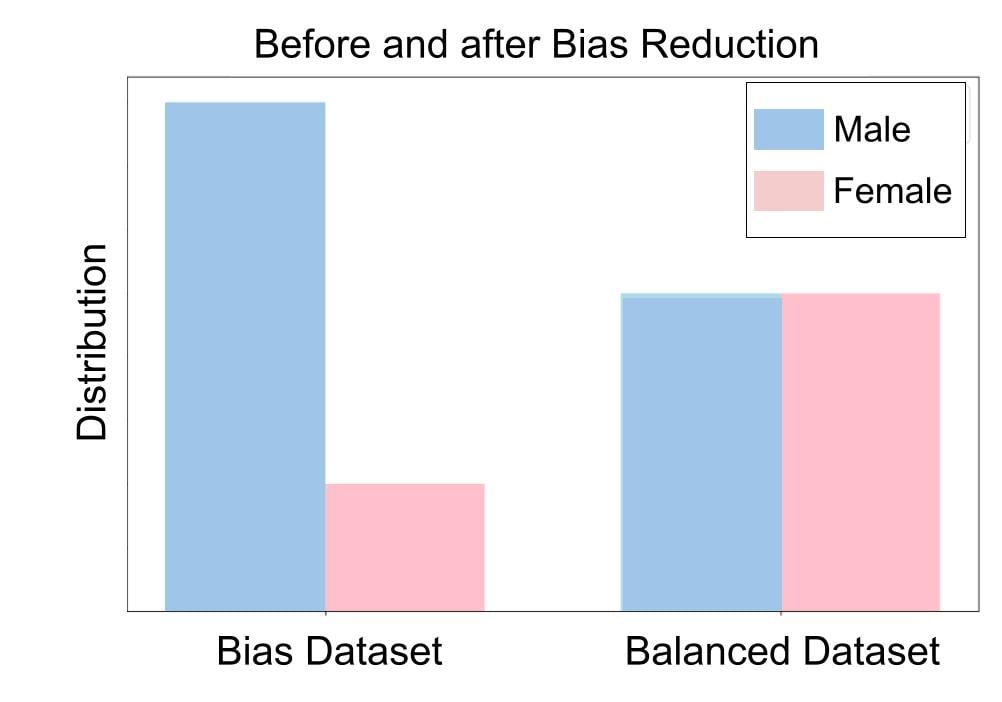
Better alignment with human values

Enhanced adaptability

Increased robustness
Integrating preference data from multiple sources
Preference data preference_df with sources 'Journalist', 'Social Media Influencer', and 'Marketing Professional':

Unreliable preference data sources
Preference data preference_df2 with the same three experts:


