Evaluating RLHF models
Reinforcement Learning from Human Feedback (RLHF)

Mina Parham
AI Engineer
Artifact curves

Artifact curves
- Reward increases as the model learns.
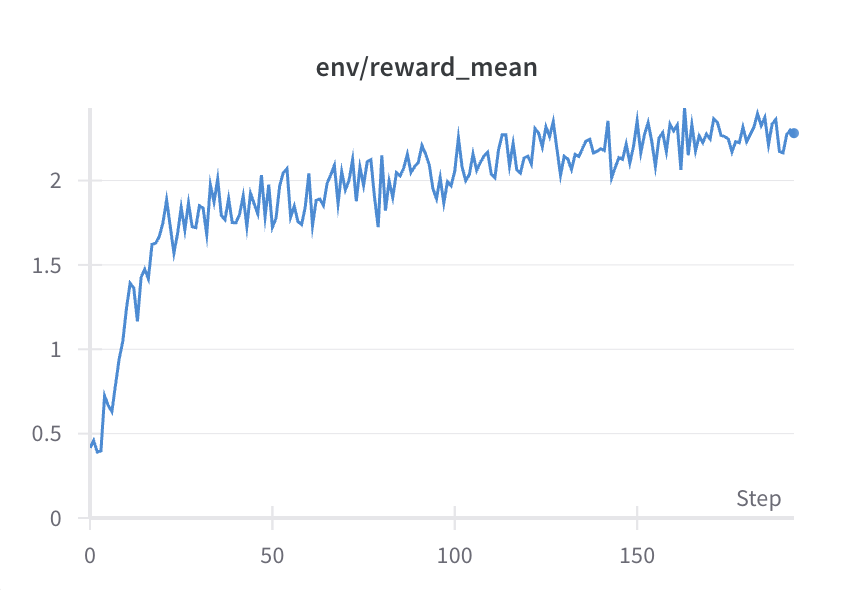
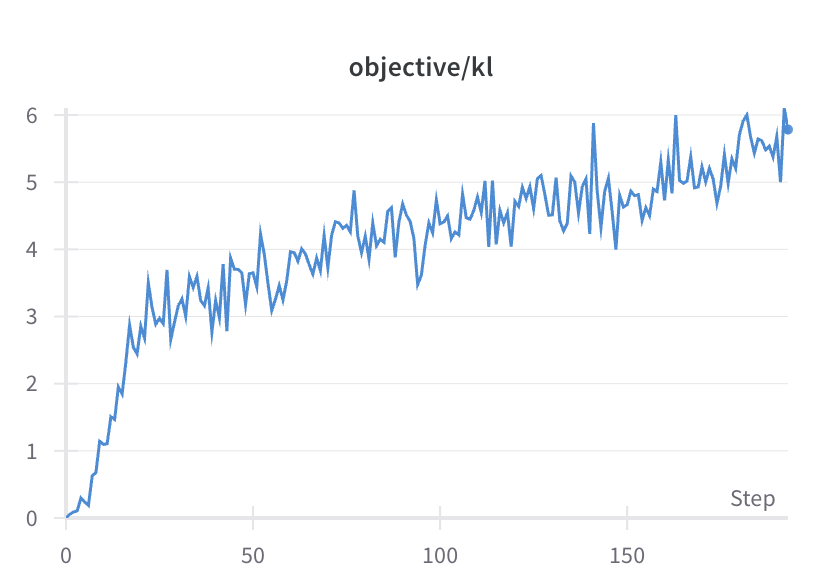
- The KL curve should increase gradually.
Human centered evaluation
- Human evaluation: subjective judgments or a deep understanding of context

- Models evaluation: scalability and consistency


