Wie gut ist dein Modell?
Überwachtes Lernen mit scikit-learn

George Boorman
Core Curriculum Manager, DataCamp
Konfusionsmatrix zur Bewertung der Klassifikationsleistung
- Konfusionsmatrix

Bewertung der Klassifikationsleistung

Bewertung der Klassifikationsleistung

Bewertung der Klassifikationsleistung
Bewertung der Klassifikationsleistung
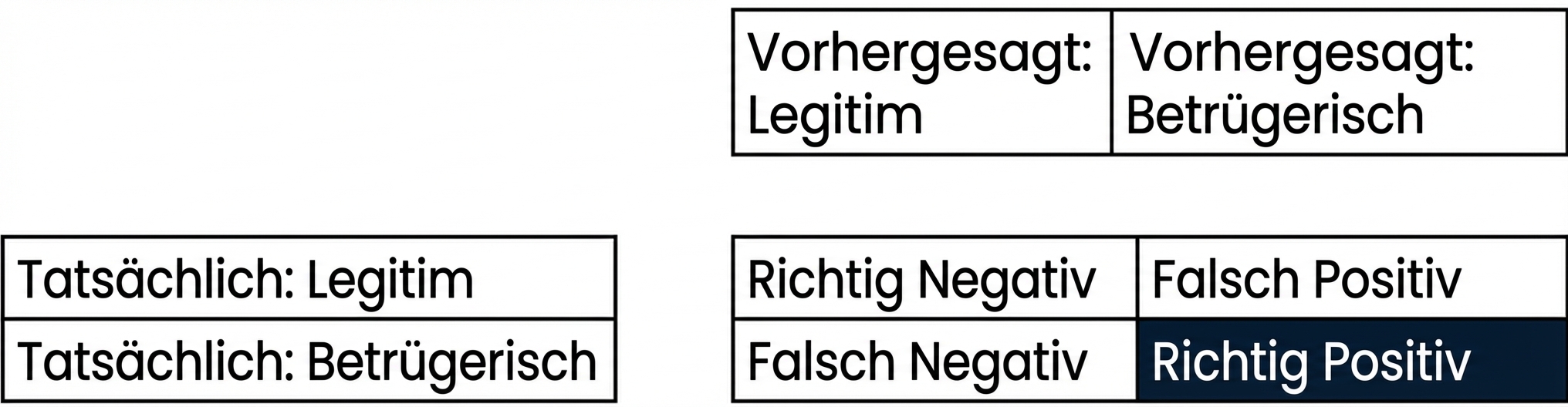
Bewertung der Klassifikationsleistung
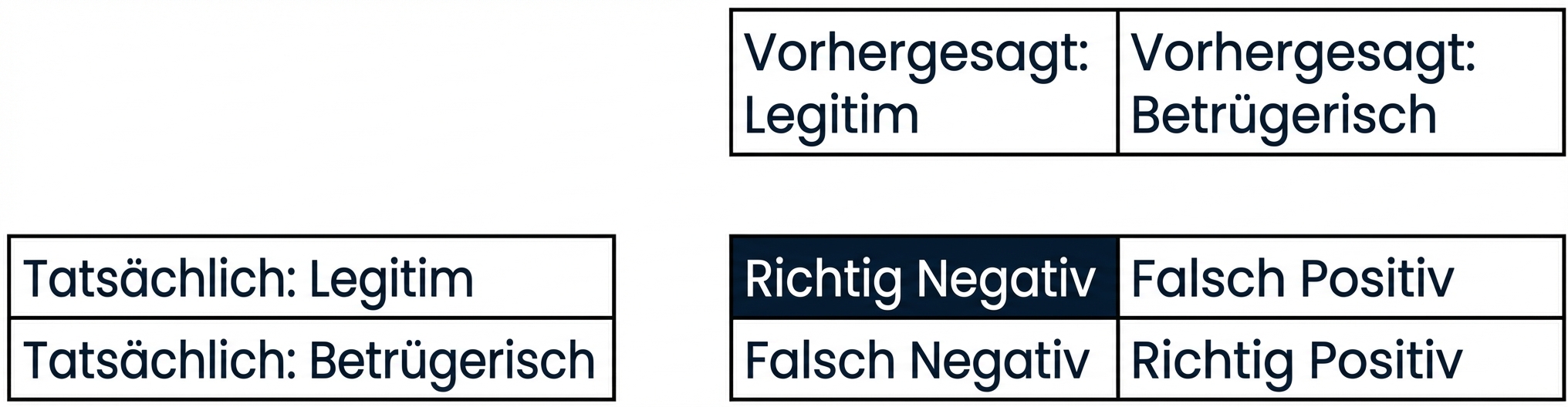
Bewertung der Klassifikationsleistung
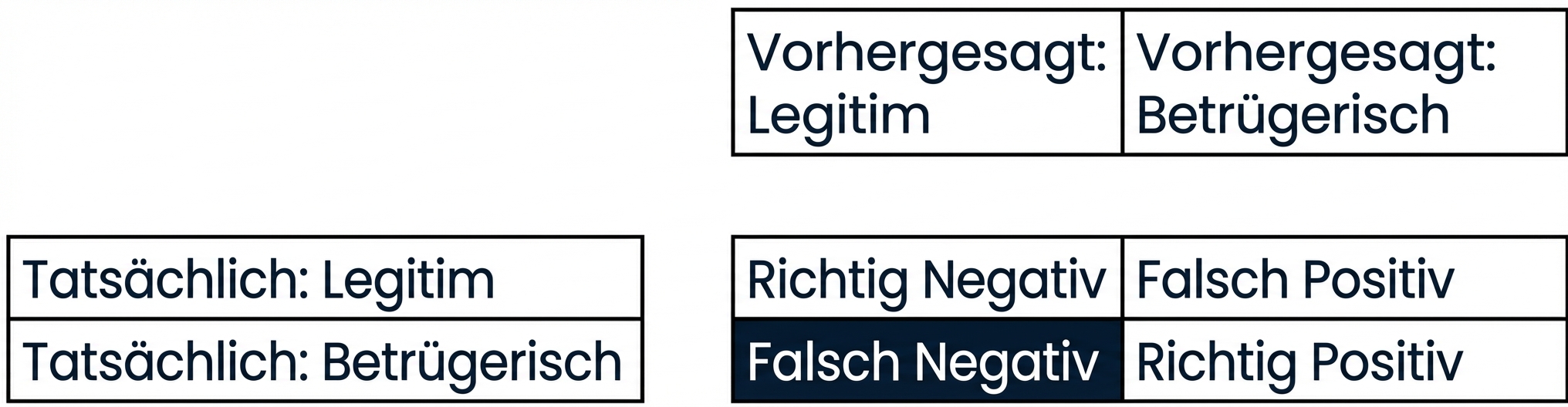
Bewertung der Klassifikationsleistung

Bewertung der Klassifikationsleistung
- Korrektklassifikationsrate („Accuracy“):
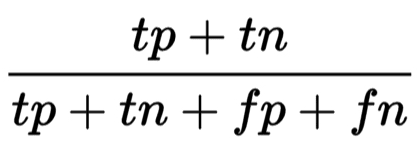
Genauigkeit
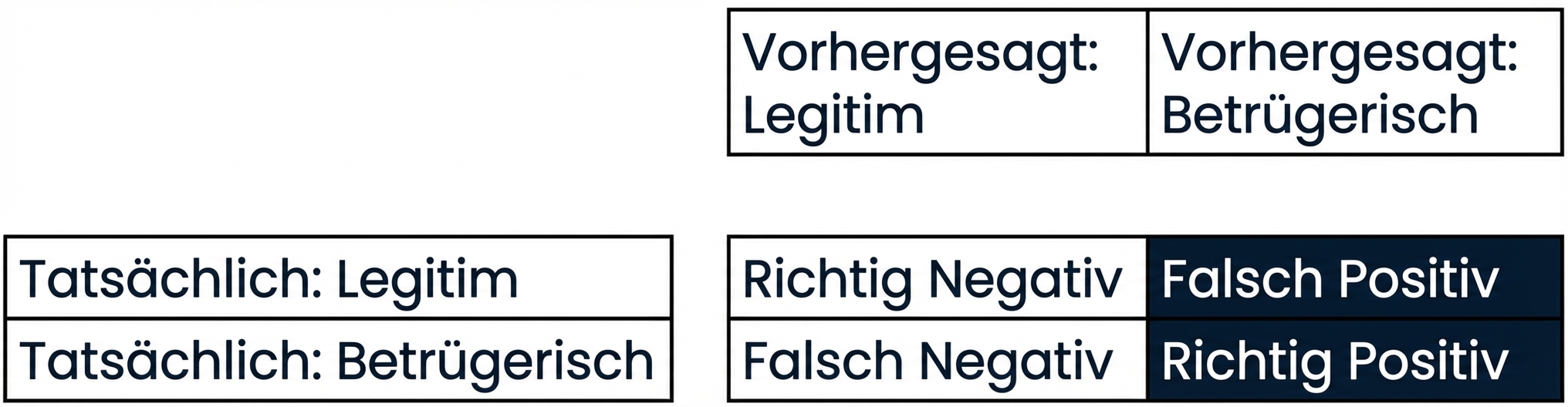
- Genauigkeit („Precision“):

- Hohe Genauigkeit = weniger falsche Positive
- Im Beispiel: nur wenige legitime Transaktionen werden als betrügerisch klassifiziert
Sensitivität
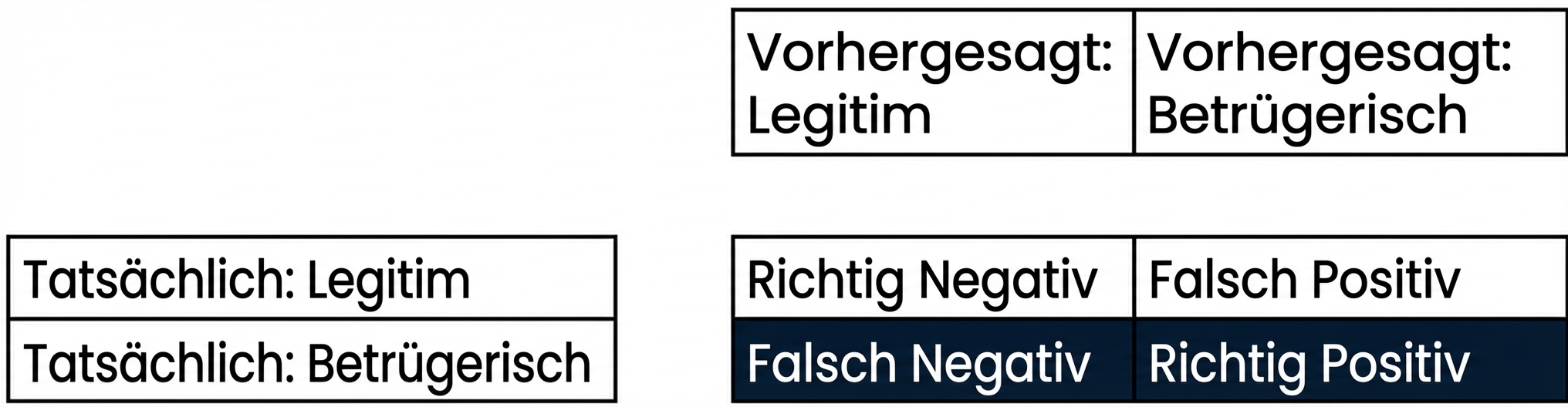
- Sensitivität („Recall“):
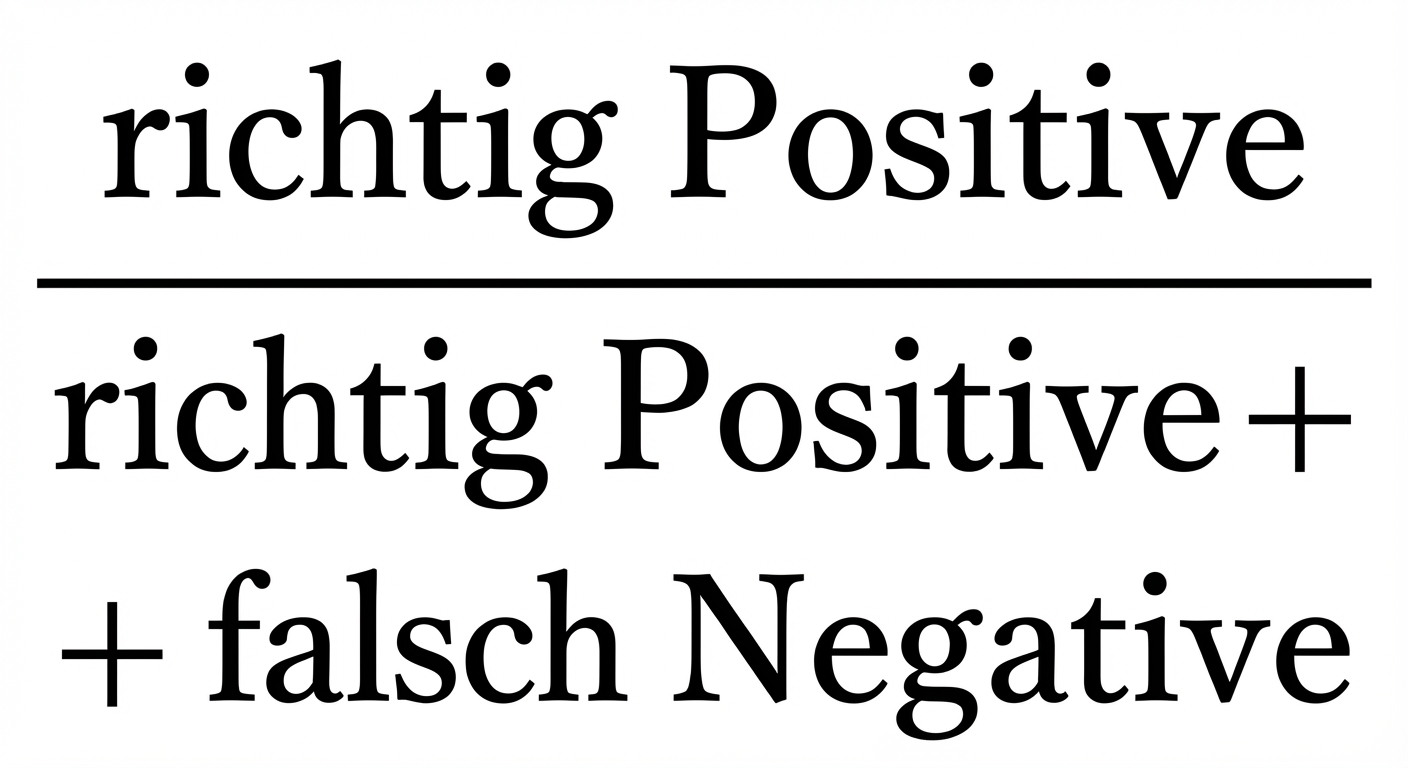
- Hohe Sensitivität = weniger falsche Negative
- Im Beispiel: die meisten betrügerischen Transaktionen werden korrekt klassifiziert

