Bewertung verschiedener Modelle
Überwachtes Lernen mit scikit-learn

George Boorman
Core Curriculum Manager, DataCamp
Verschiedene Modelle für verschiedene Aufgaben
Beachtung einiger Grundprinzipien
- Größe des Datensatzes
- Weniger Merkmale = einfacheres Modell, kürzere Trainingszeit
- Einige Modelle brauchen sehr große Datenmengen, um eine gute Leistung zu erzielen
- Interpretierbarkeit
- Einige Modelle sind leichter zu erklären (kann für Stakeholder wichtig sein)
- Lineare Regression hat hohe Interpretierbarkeit, da die Koeffizienten verständlich sind
- Flexibilität
- Kann Genauigkeit verbessern, da weniger Vermutungen über die Daten nötig sind
- KNN ist flexibleres Modell und setzt keine linearen Beziehungen voraus
Wichtige Kennzahlen
Leistung von Regressionsmodellen:
- RMSE
- Bestimmtheitsmaß ($R^2$)
Leistung von Klassifikationsmodellen:
- Korrektklassifikationsrate
- Konfusionsmatrix
- Genauigkeit, Sensitivität, F-Maß
- ROC-Kurve, AUC-Wert
Training mehrerer Modelle und Bewertung ihrer Leistung ohne Hyperparameter-Optimierung
Hinweis zur Skalierung
- Modelle mit meist besserer Leistung bei Skalierung:
- KNN
- Lineare Regression (plus Ridge, Lasso)
- Logistische Regression
- Künstliches neuronales Netz
- Daher am besten Skalierung der Daten vor der Bewertung der Modelle
Bewertung von Klassifikationsmodellen
import matplotlib.pyplot as plt from sklearn.preprocessing import StandardScaler from sklearn.model_selection import cross_val_score, KFold, train_test_split from sklearn.neighbors import KNeighborsClassifier from sklearn.linear_model import LogisticRegression from sklearn.tree import DecisionTreeClassifierX = music.drop("genre", axis=1).values y = music["genre"].values X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=42)scaler = StandardScaler() X_train_scaled = scaler.fit_transform(X_train)X_test_scaled = scaler.transform(X_test)
Bewertung von Klassifikationsmodellen
models = {"Logistic Regression": LogisticRegression(), "KNN": KNeighborsClassifier(), "Decision Tree": DecisionTreeClassifier()} results = []for model in models.values():kf = KFold(n_splits=6, random_state=42, shuffle=True)cv_results = cross_val_score(model, X_train_scaled, y_train, cv=kf)results.append(cv_results)plt.boxplot(results, labels=models.keys()) plt.show()
Visualisierung der Ergebnisse
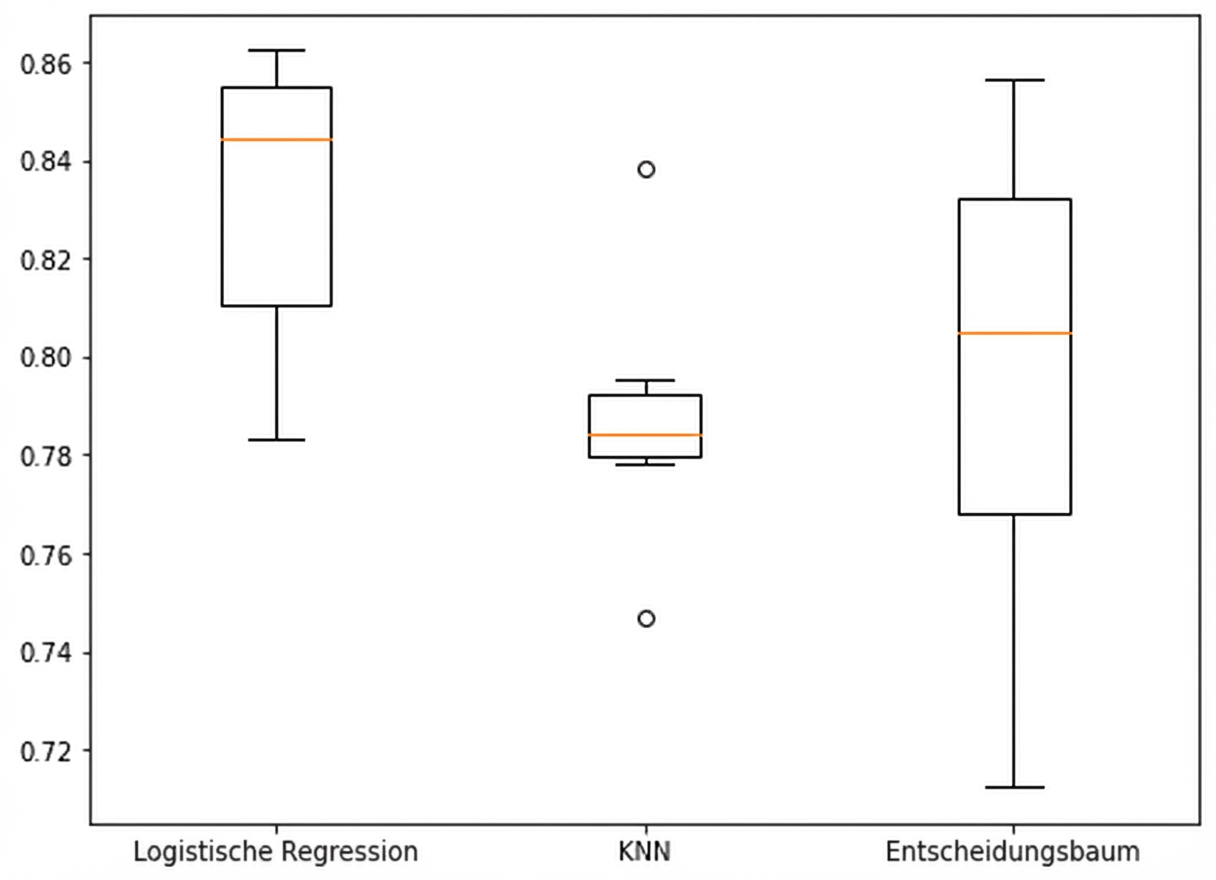
Leistung beim Testdatensatz
for name, model in models.items():model.fit(X_train_scaled, y_train)test_score = model.score(X_test_scaled, y_test)print("{} Test Set Accuracy: {}".format(name, test_score))
Logistic Regression Test Set Accuracy: 0.844
KNN Test Set Accuracy: 0.82
Decision Tree Test Set Accuracy: 0.832
Lass uns üben!
Überwachtes Lernen mit scikit-learn

