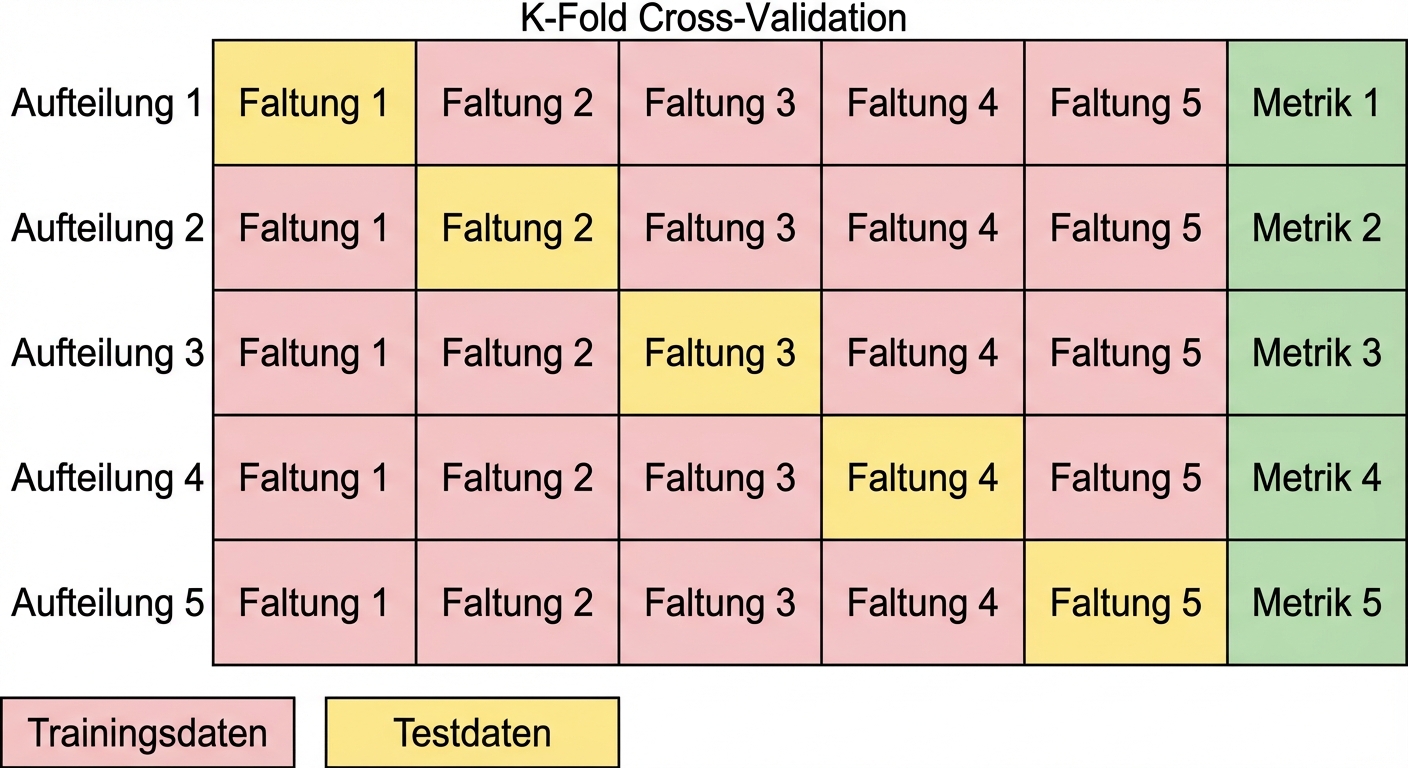
Kreuzvalidierung
Überwachtes Lernen mit scikit-learn

George Boorman
Core Curriculum Manager, DataCamp
Grundlagen der Kreuzvalidierung
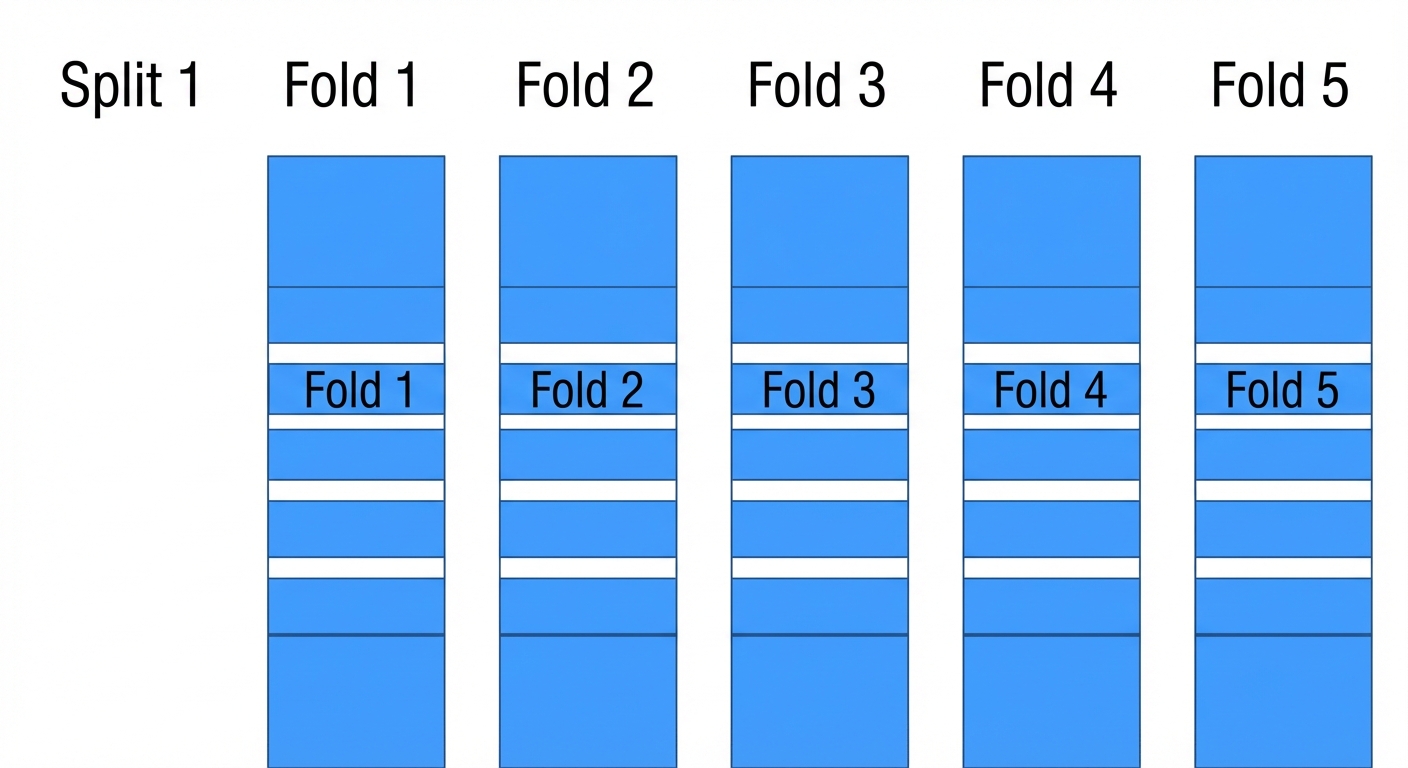
Grundlagen der Kreuzvalidierung
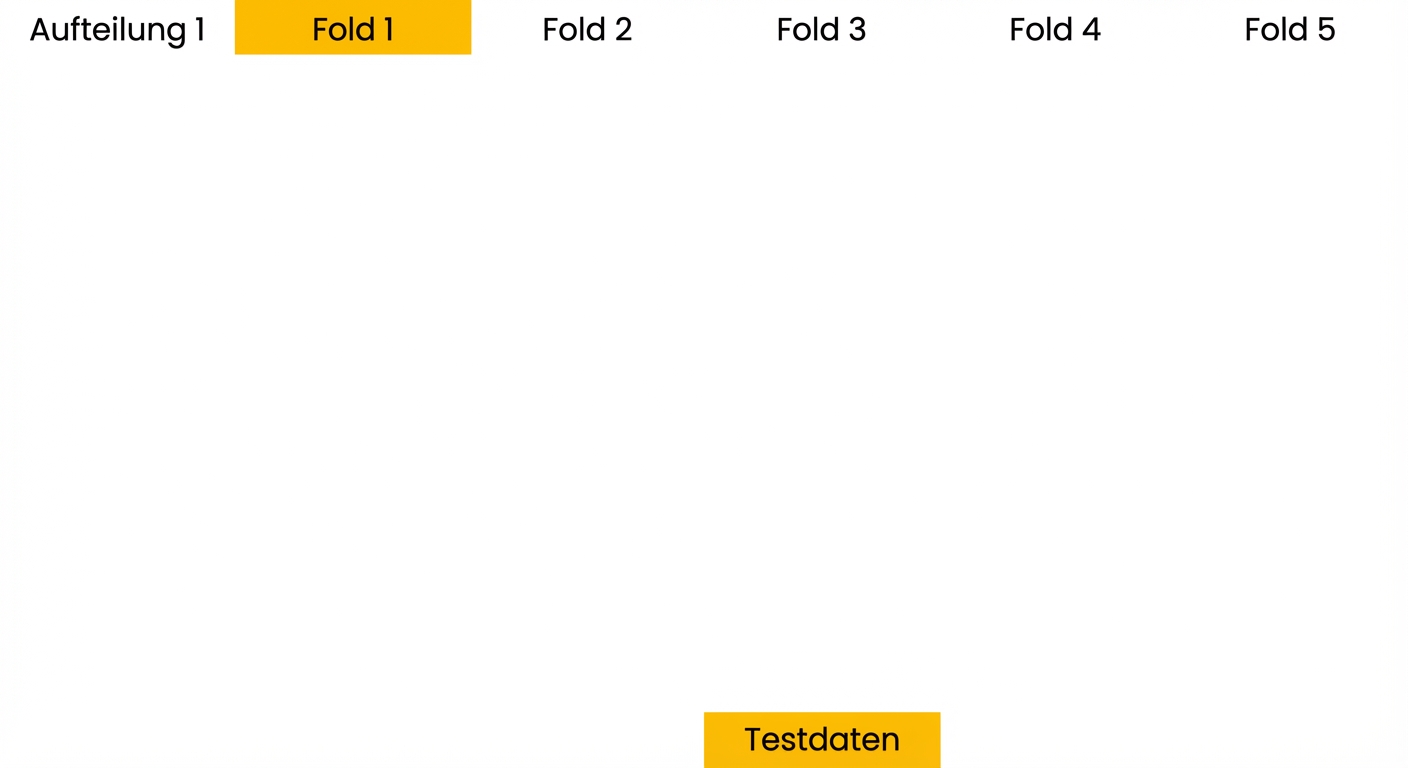
Grundlagen der Kreuzvalidierung

Grundlagen der Kreuzvalidierung
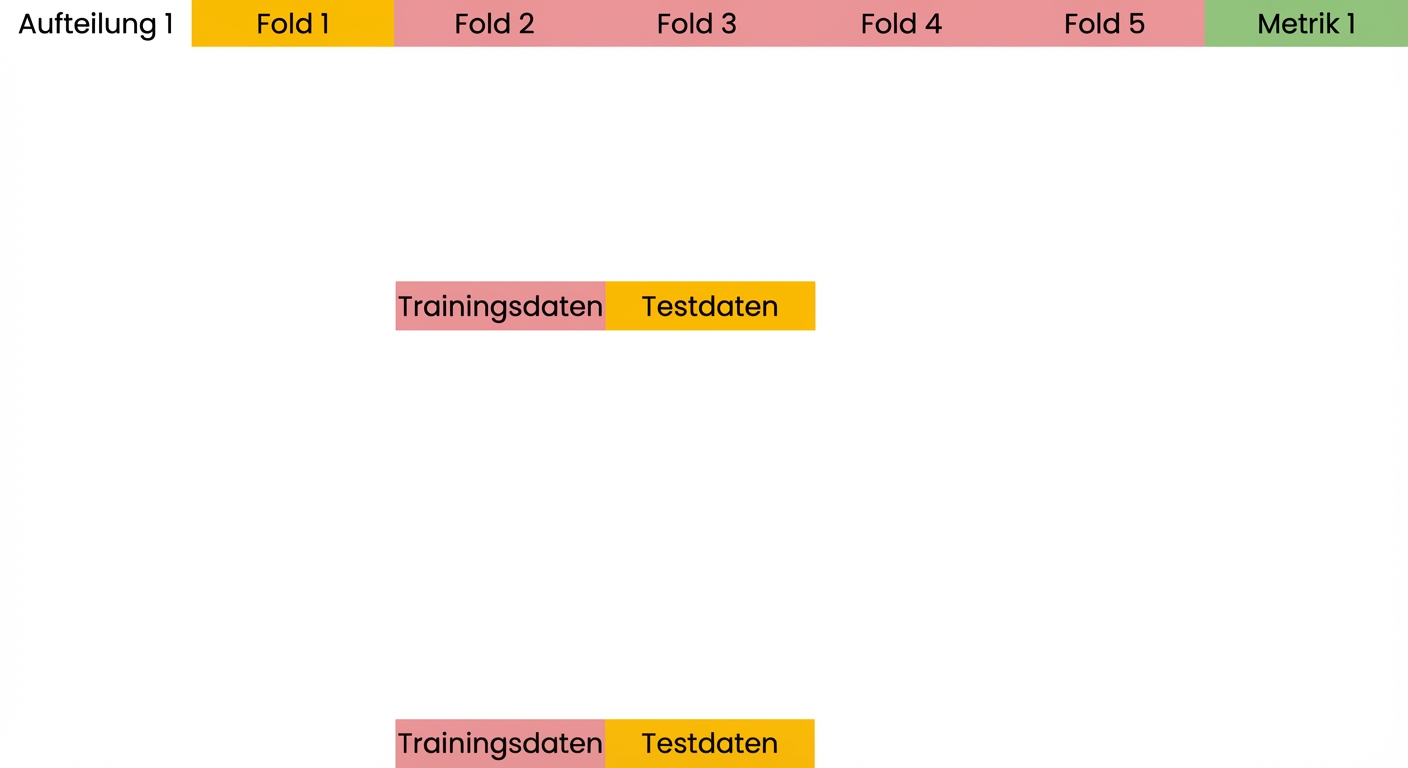
Grundlagen der Kreuzvalidierung
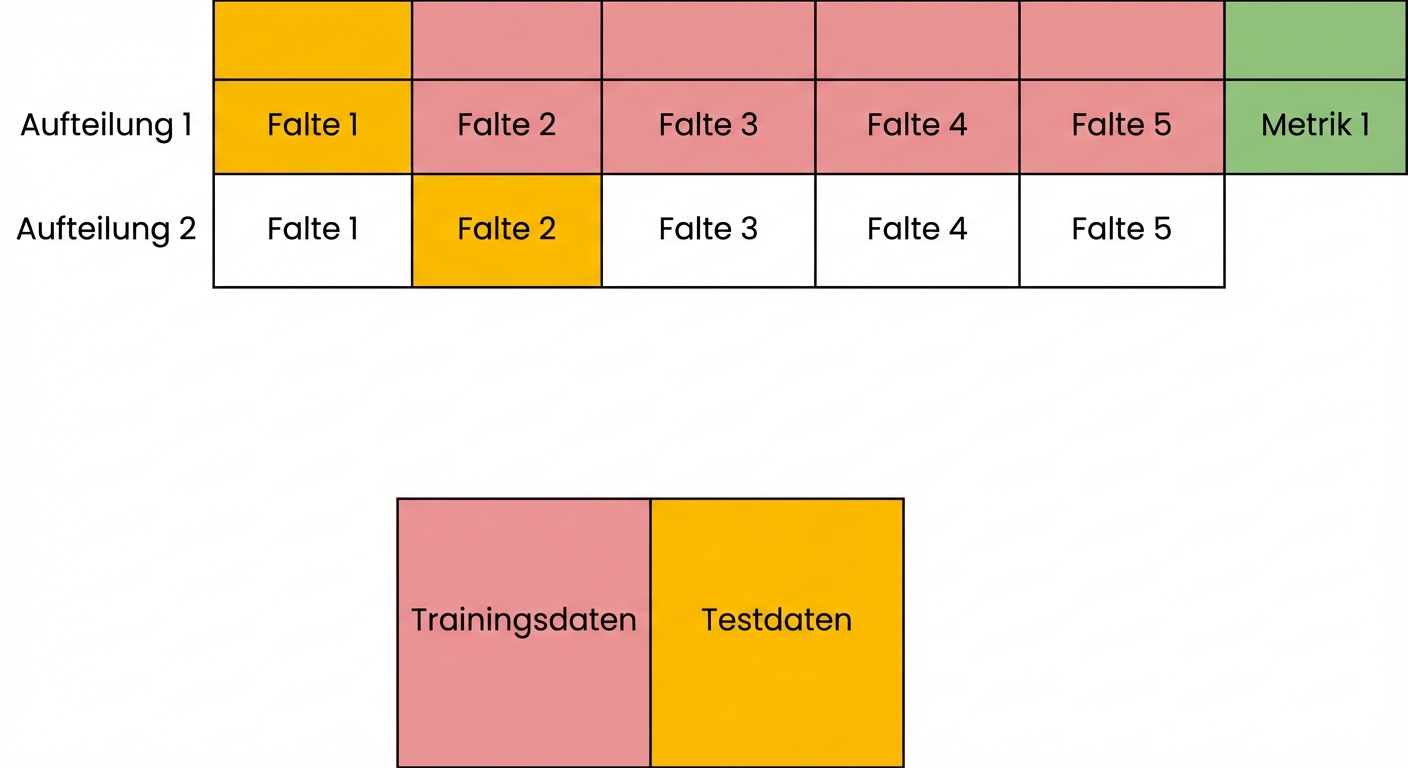
Grundlagen der Kreuzvalidierung
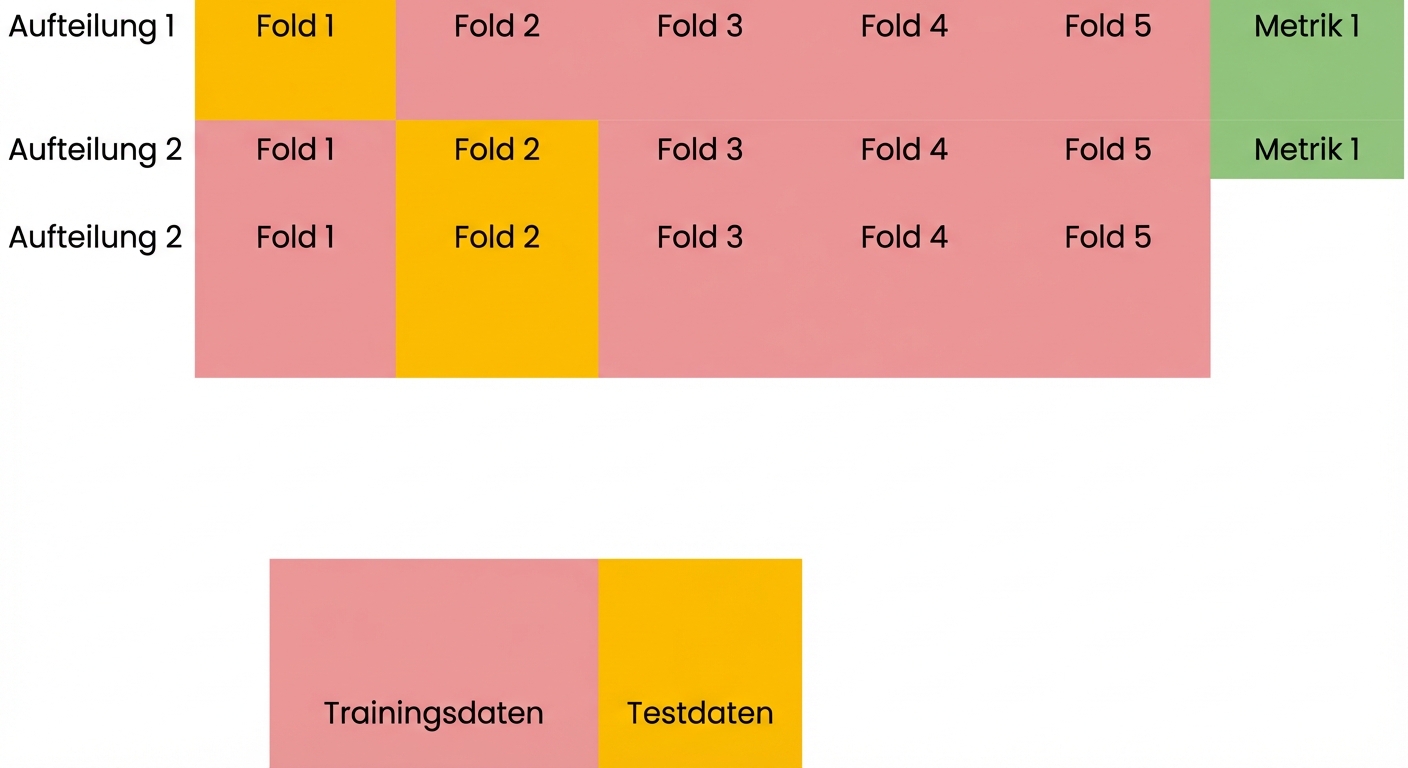
Grundlagen der Kreuzvalidierung
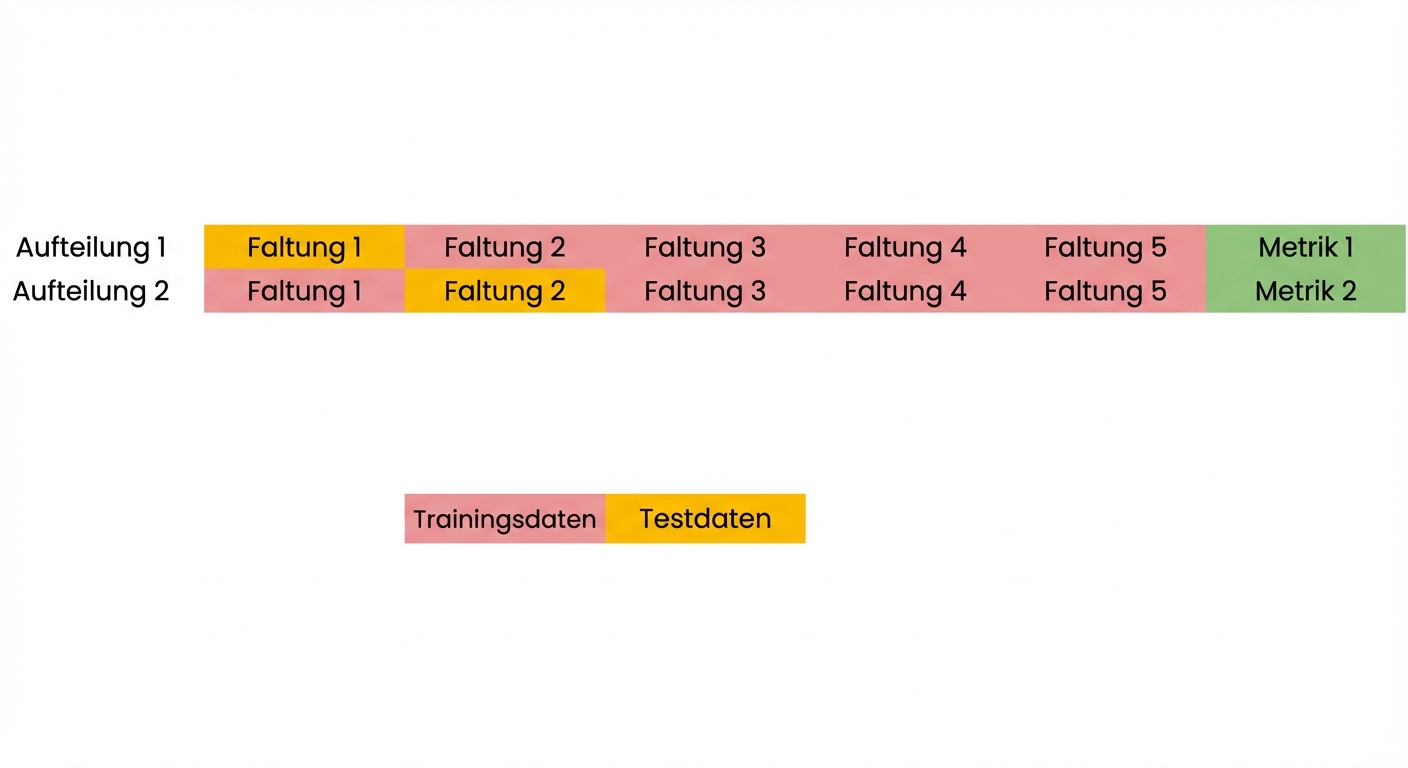
Grundlagen der Kreuzvalidierung
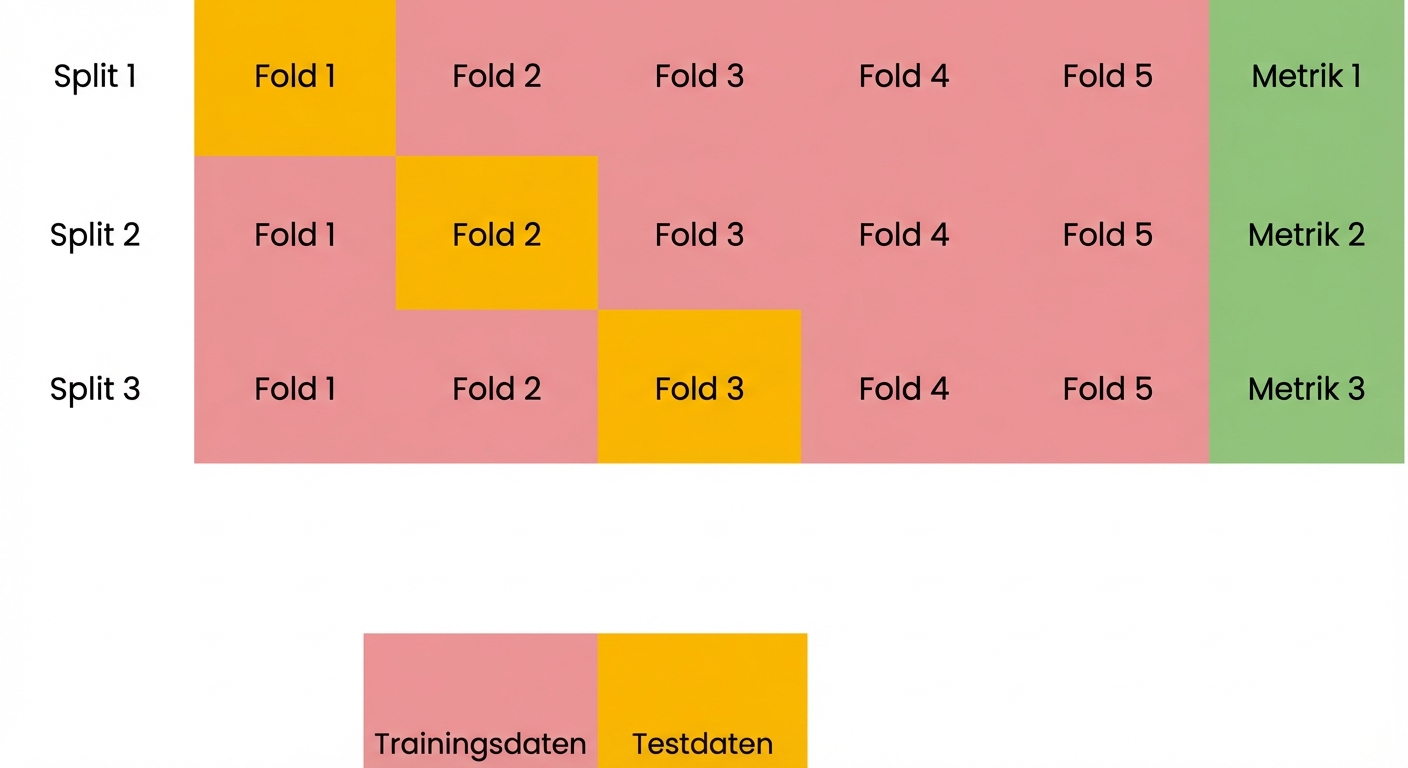
Grundlagen der Kreuzvalidierung
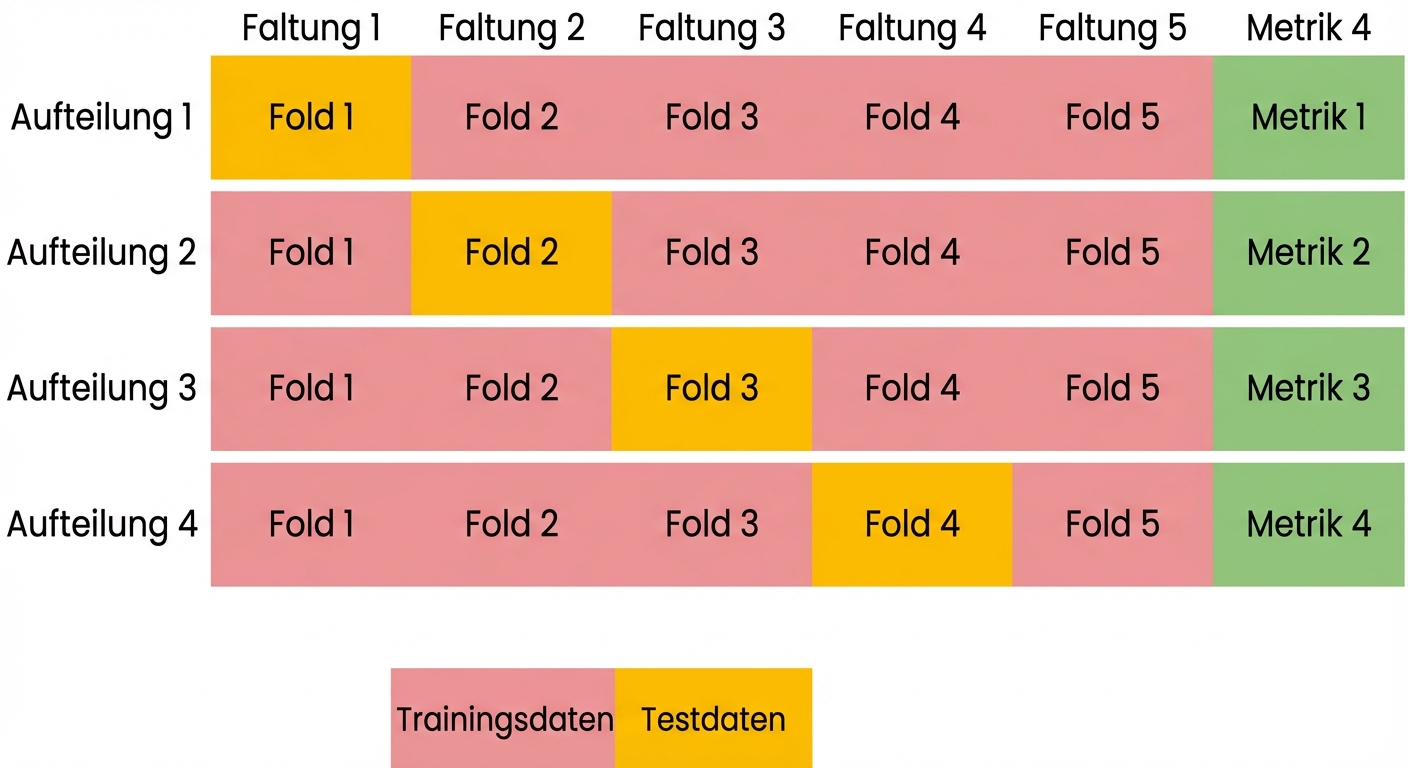
Grundlagen der Kreuzvalidierung