Messung der Modellleistung
Überwachtes Lernen mit scikit-learn

George Boorman
Core Curriculum Manager, DataCamp
Messung der Modellleistung
Genauigkeit ist eine häufig verwendete Kennzahl bei der Klassifikation
Genauigkeit:

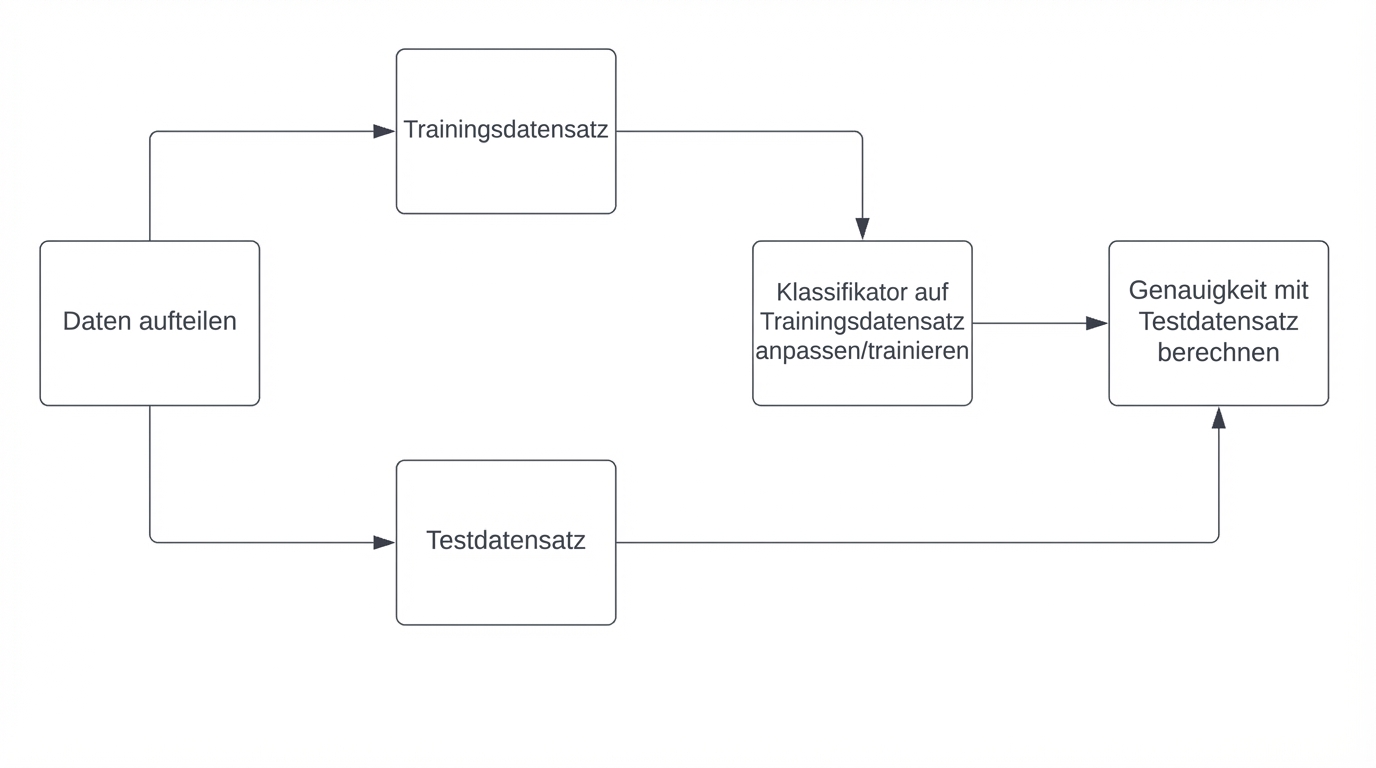
Berechnung der Genauigkeit
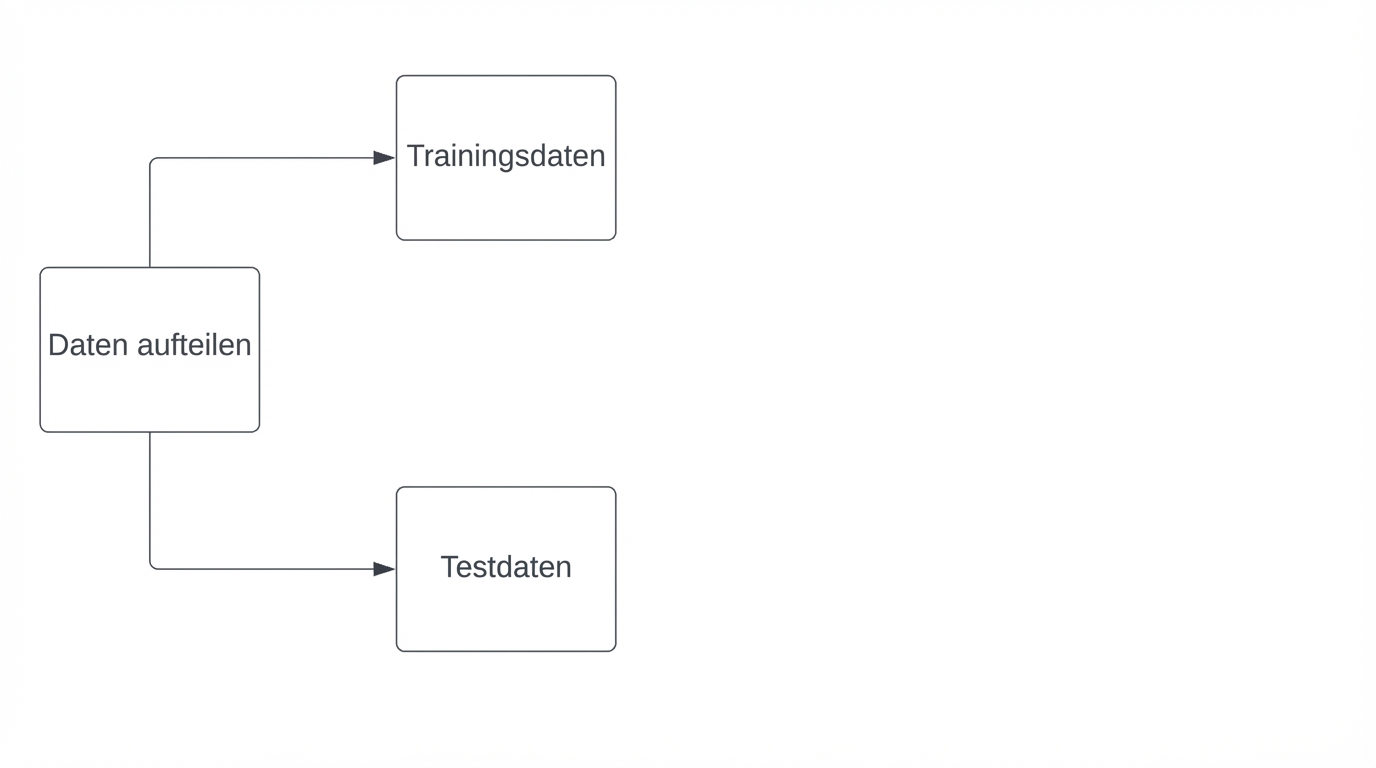
Berechnung der Genauigkeit
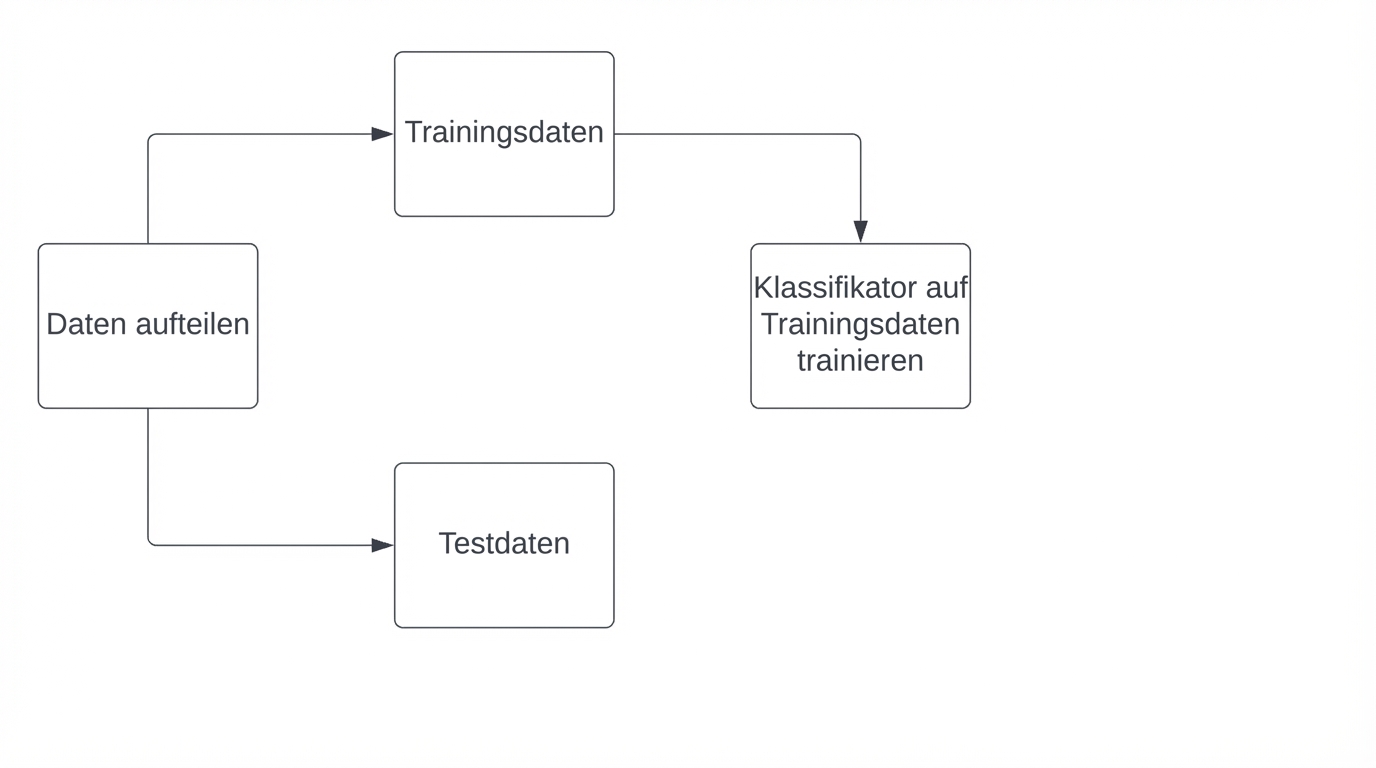
Berechnung der Genauigkeit
Modellkomplexität
Größeres k = einfacheres Modell = mögliche Unteranpassung
Kleineres k = komplexeres Modell = mögliche Überanpassung
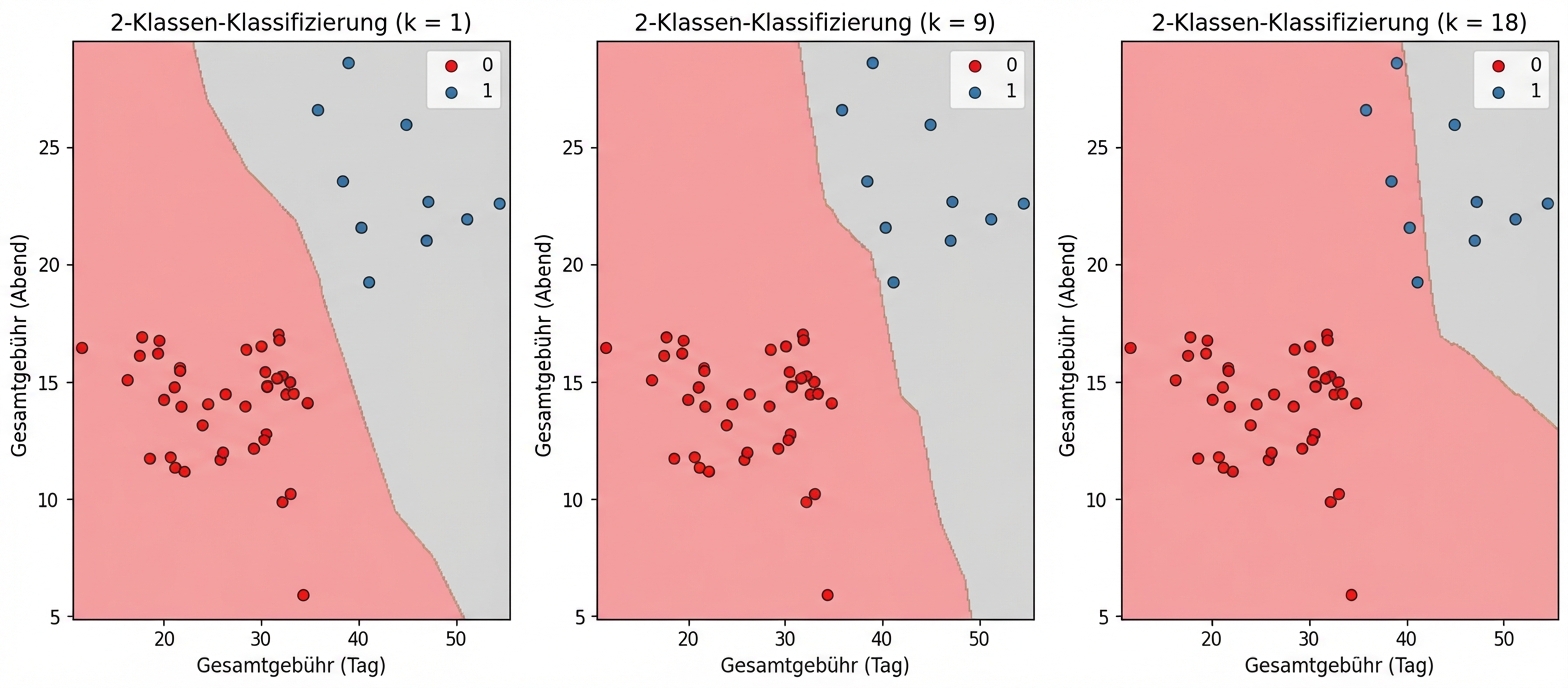
Modellkomplexitätskurve
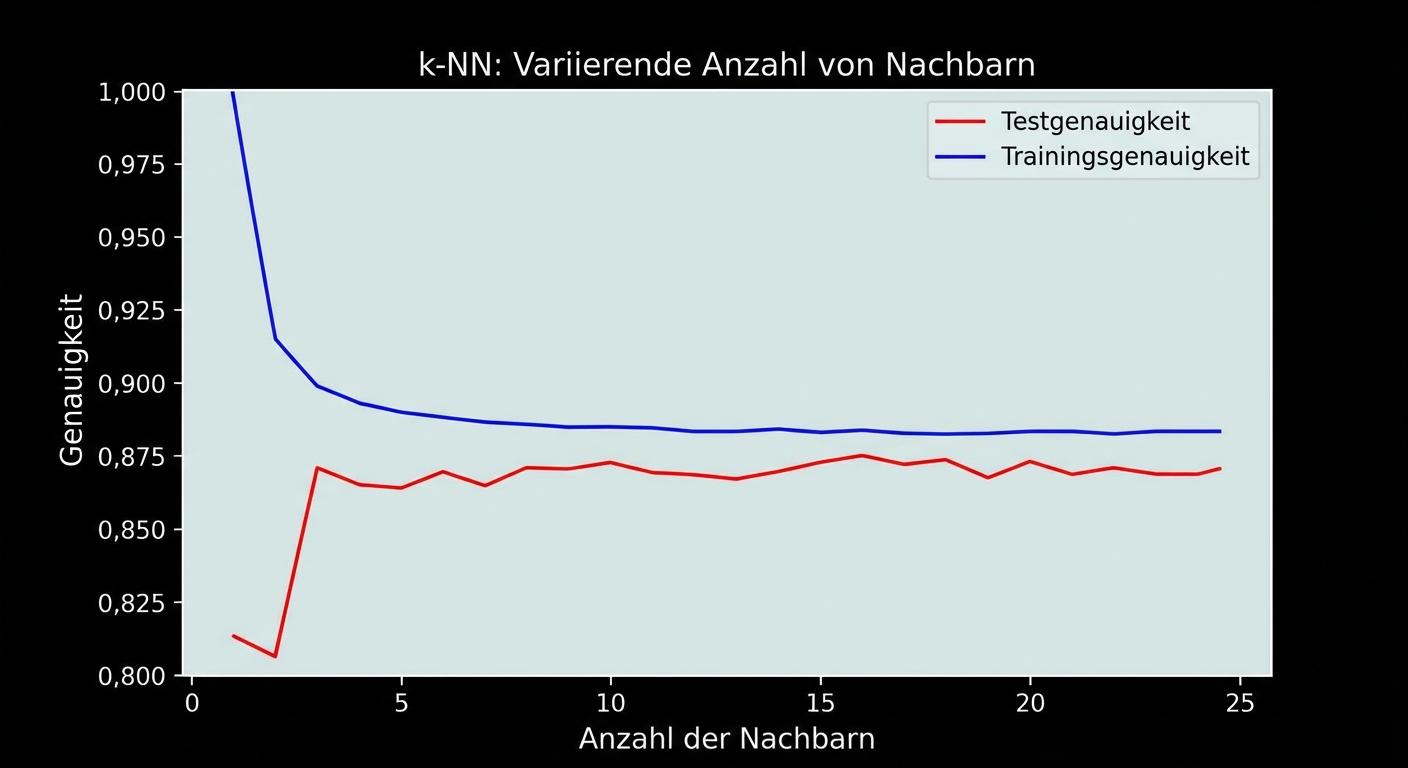
Modellkomplexitätskurve
![]()

