Vorverarbeitung von Daten
Überwachtes Lernen mit scikit-learn

George Boorman
Core Curriculum Manager, DataCamp
Dummy-Variablen

Dummy-Variablen
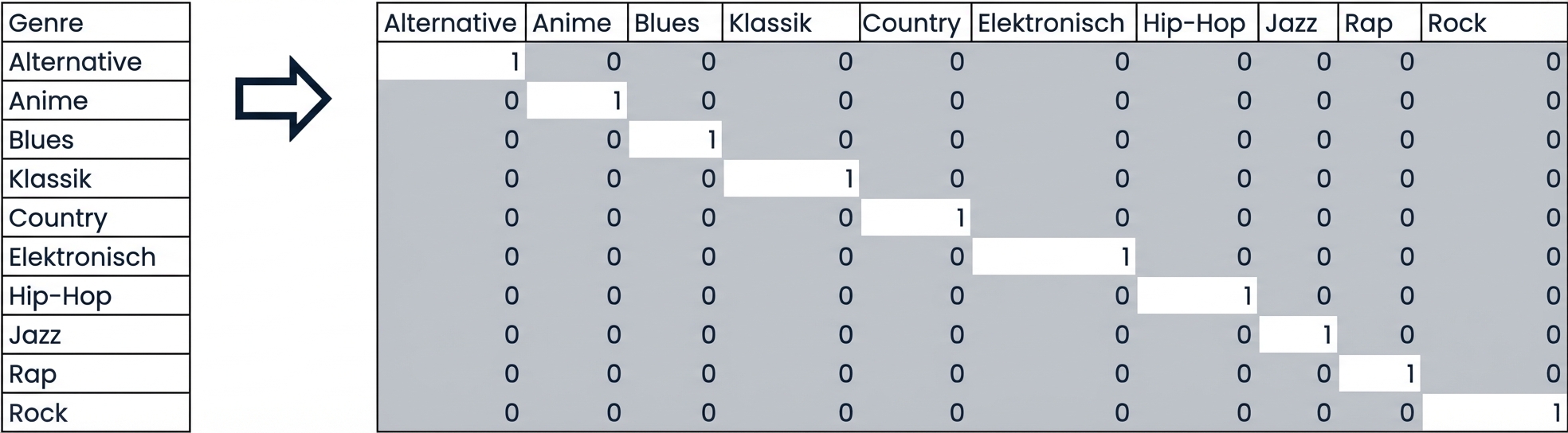
Dummy-Variablen
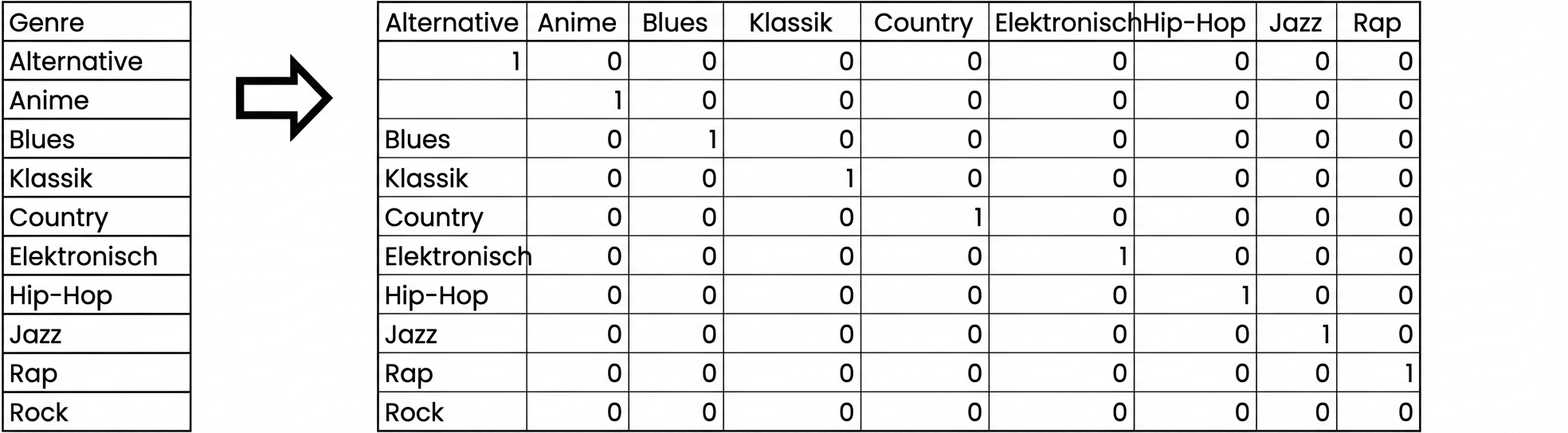
EDA mit kategorialem Merkmal
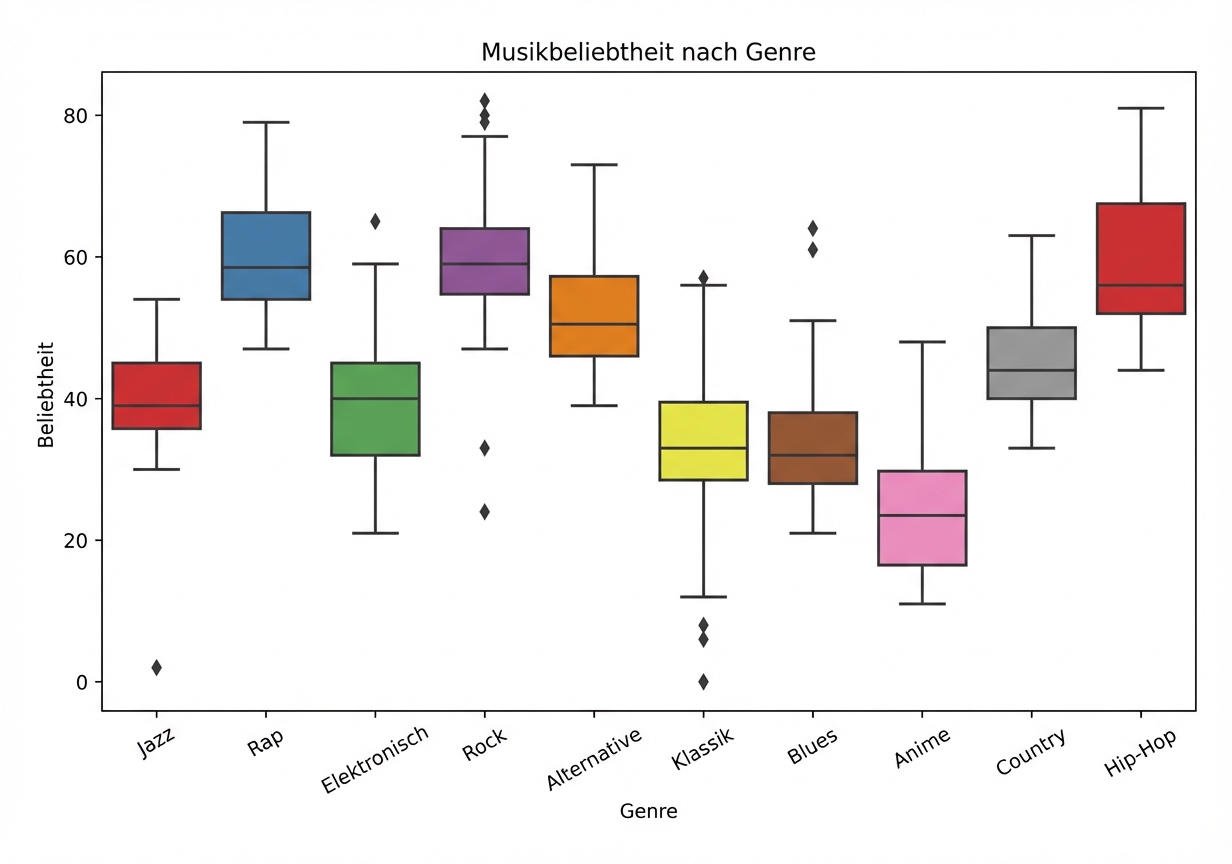
Überwachtes Lernen mit scikit-learn
George Boorman
Core Curriculum Manager, DataCamp

