Optimierung von Hyperparametern
Überwachtes Lernen mit scikit-learn

George Boorman
Core Curriculum Manager
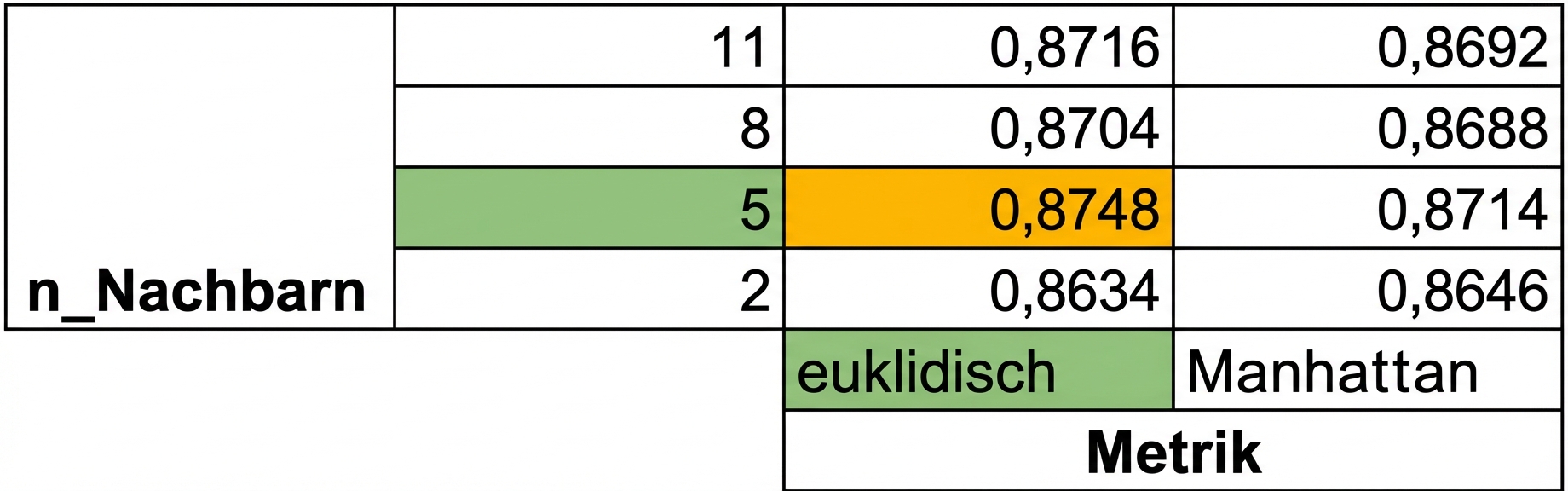
Rastersuche mit Kreuzvalidierung

Rastersuche mit Kreuzvalidierung
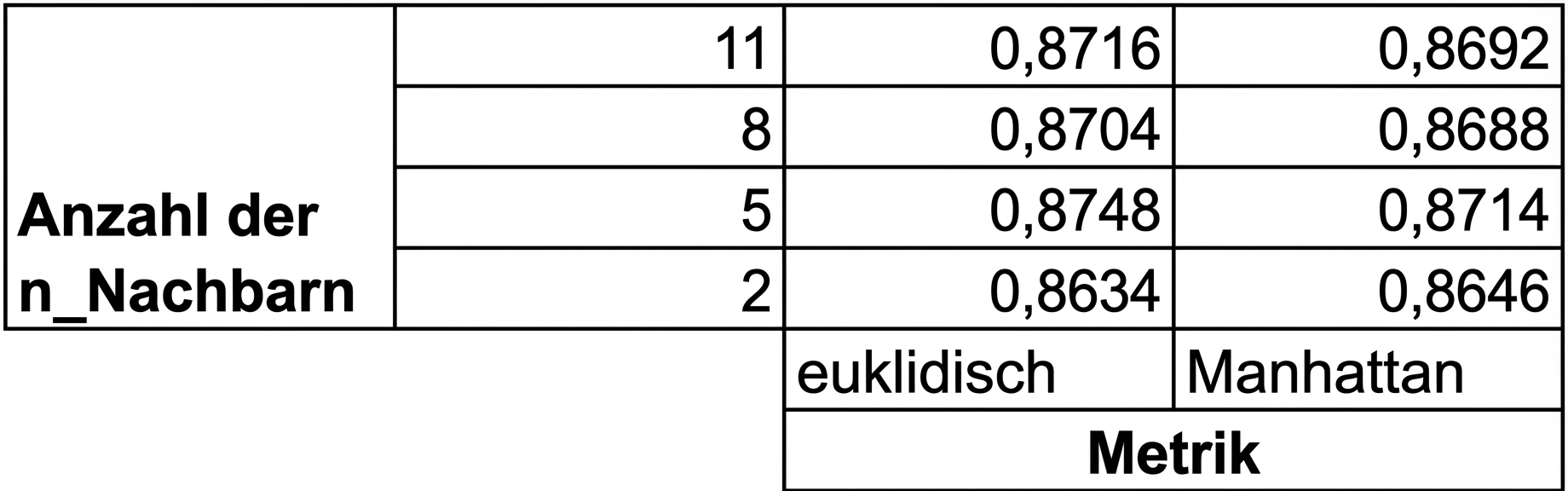
Rastersuche mit Kreuzvalidierung
Überwachtes Lernen mit scikit-learn
George Boorman
Core Curriculum Manager

