Die Leistung des Modells verbessern
Einführung in Deep Learning mit PyTorch

Jasmin Ludolf
Senior Data Science Content Developer, DataCamp
Schritte zur Maximierung der Leistung


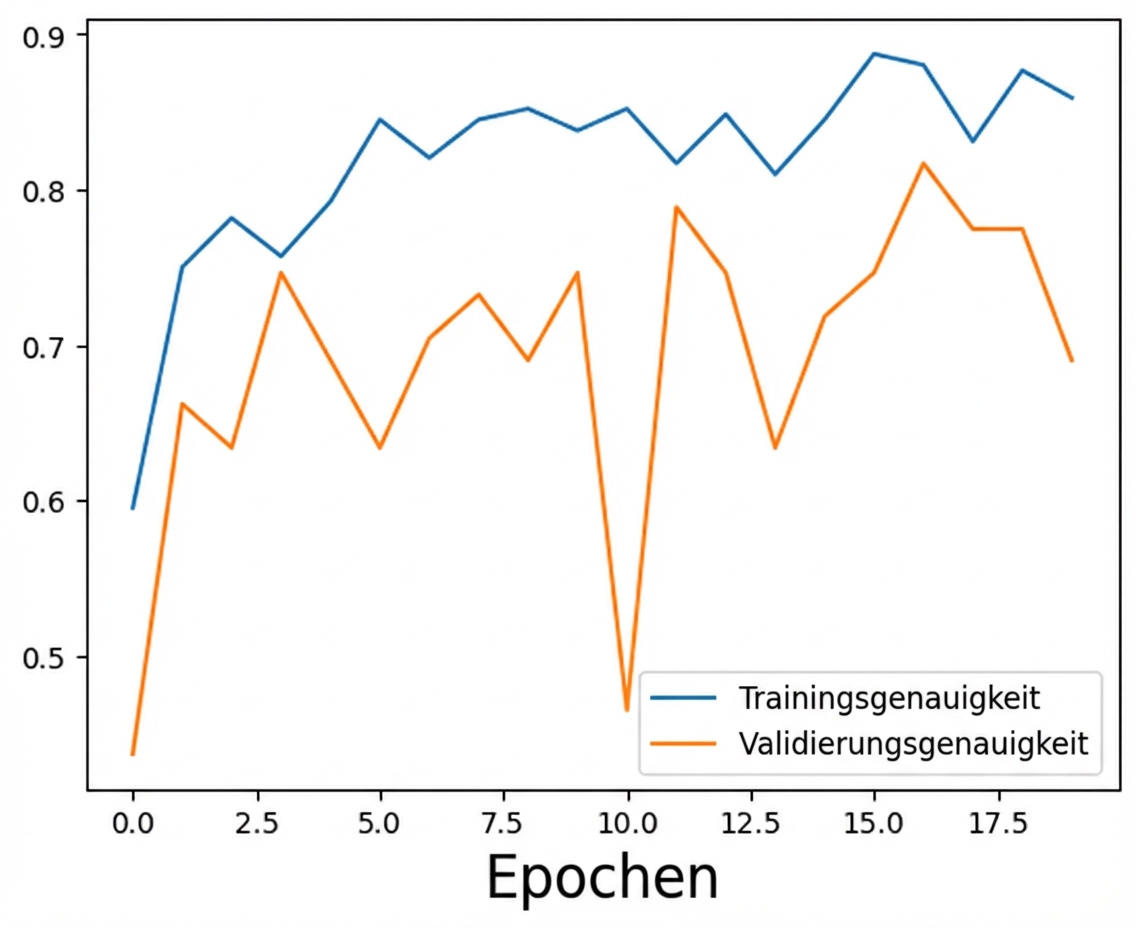
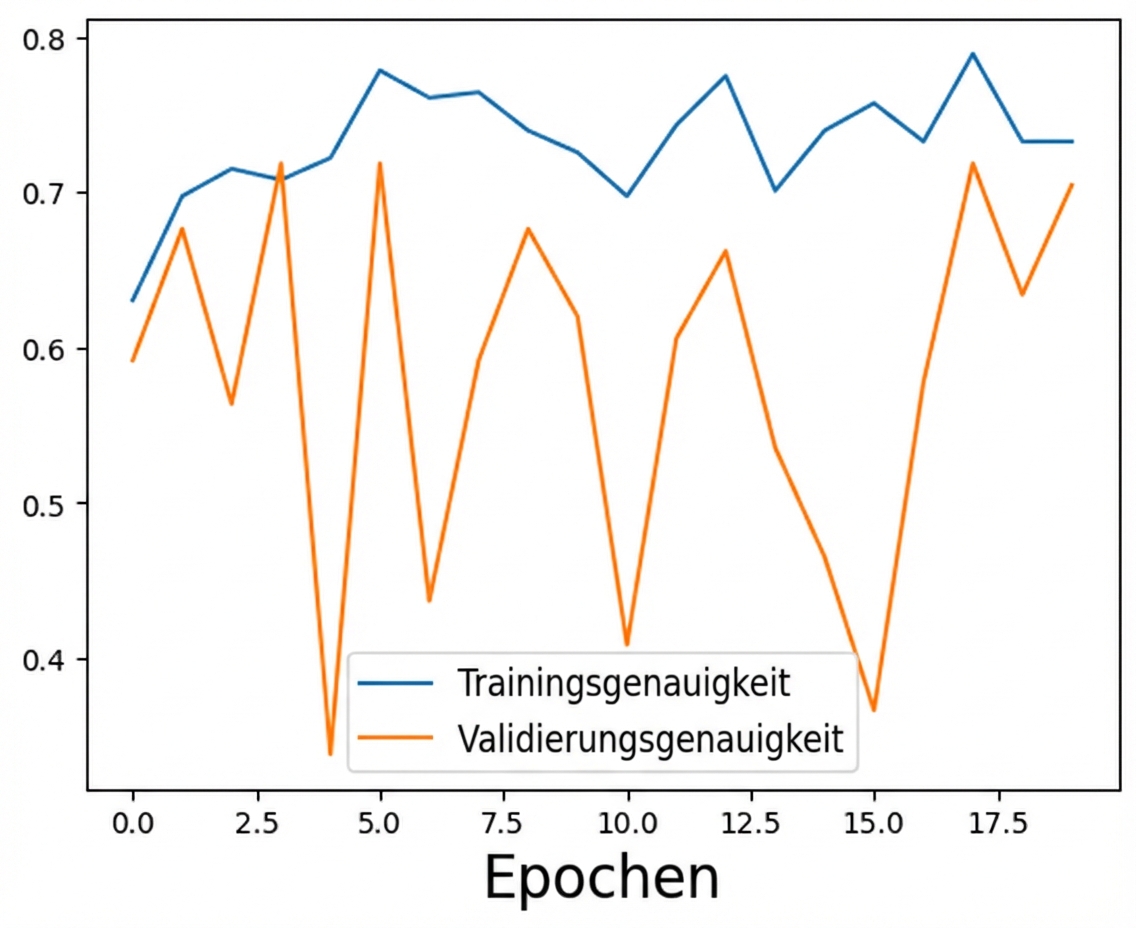
Schritt 2: Überanpassung reduzieren
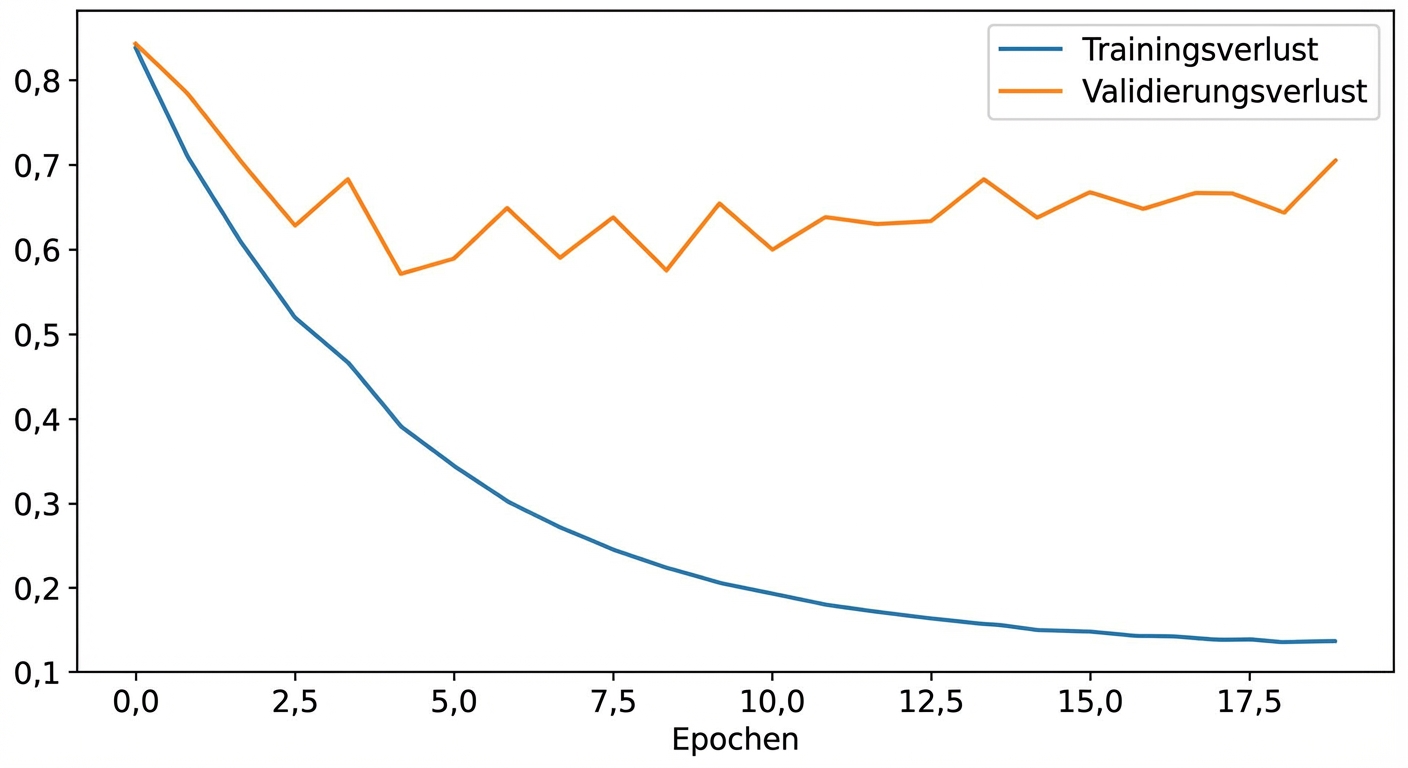
Schritt 2: Überanpassung reduzieren
$$
Ursprüngliches Modell passt sich den Trainingsdaten zu sehr an
$$
Aktualisiertes Modell mit zu viel Regularisierung
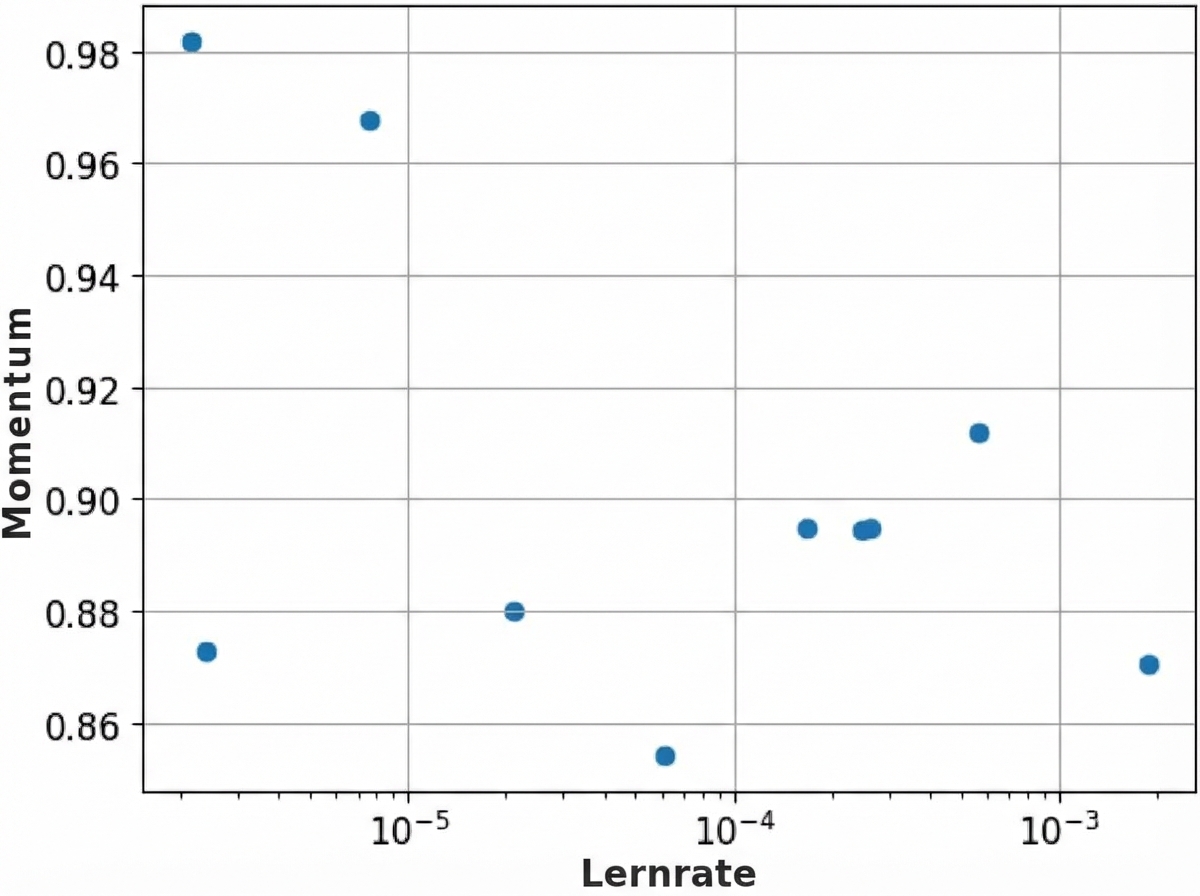
Schritt 3: Feinabstimmung der Hyperparameter
- Rastersuche
for factor in range(2, 6):
lr = 10 ** -factor
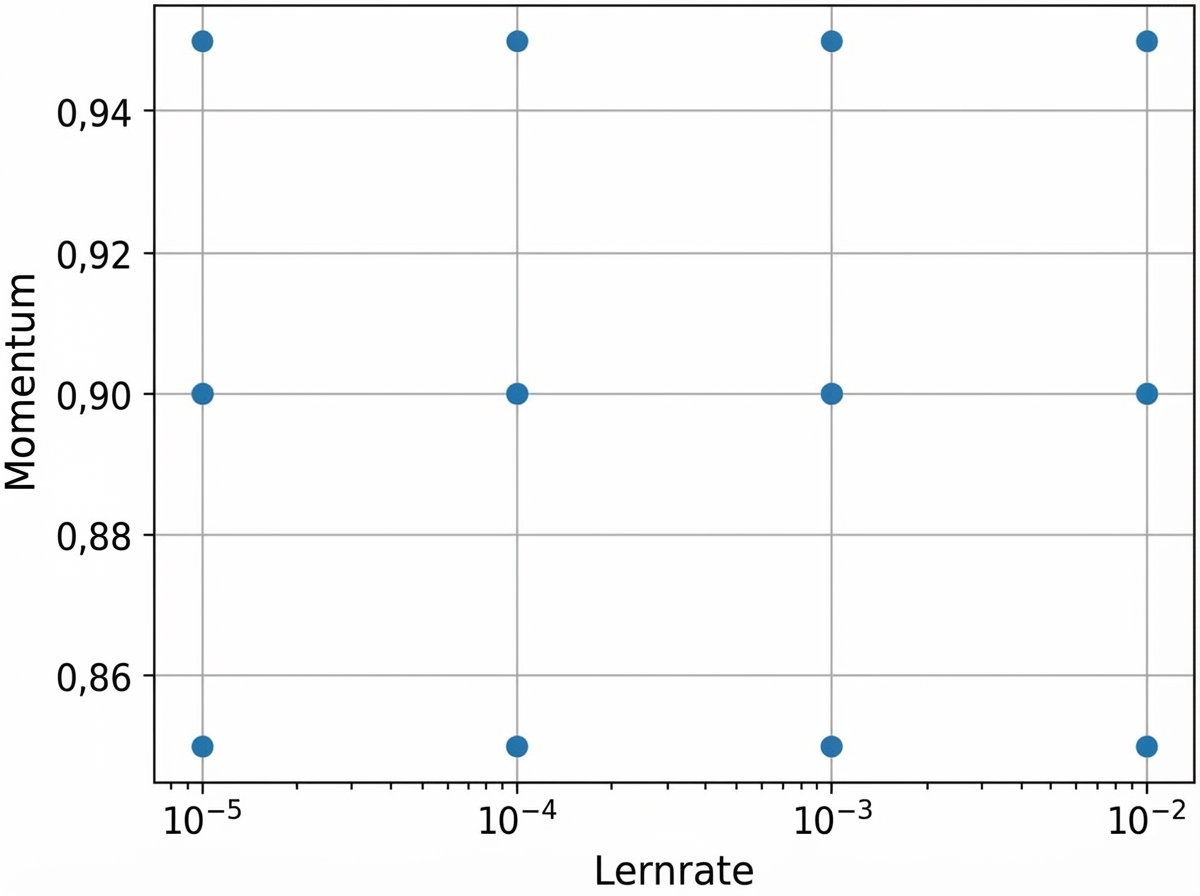
- Zufallssuche
factor = np.random.uniform(2, 6)
lr = 10 ** -factor