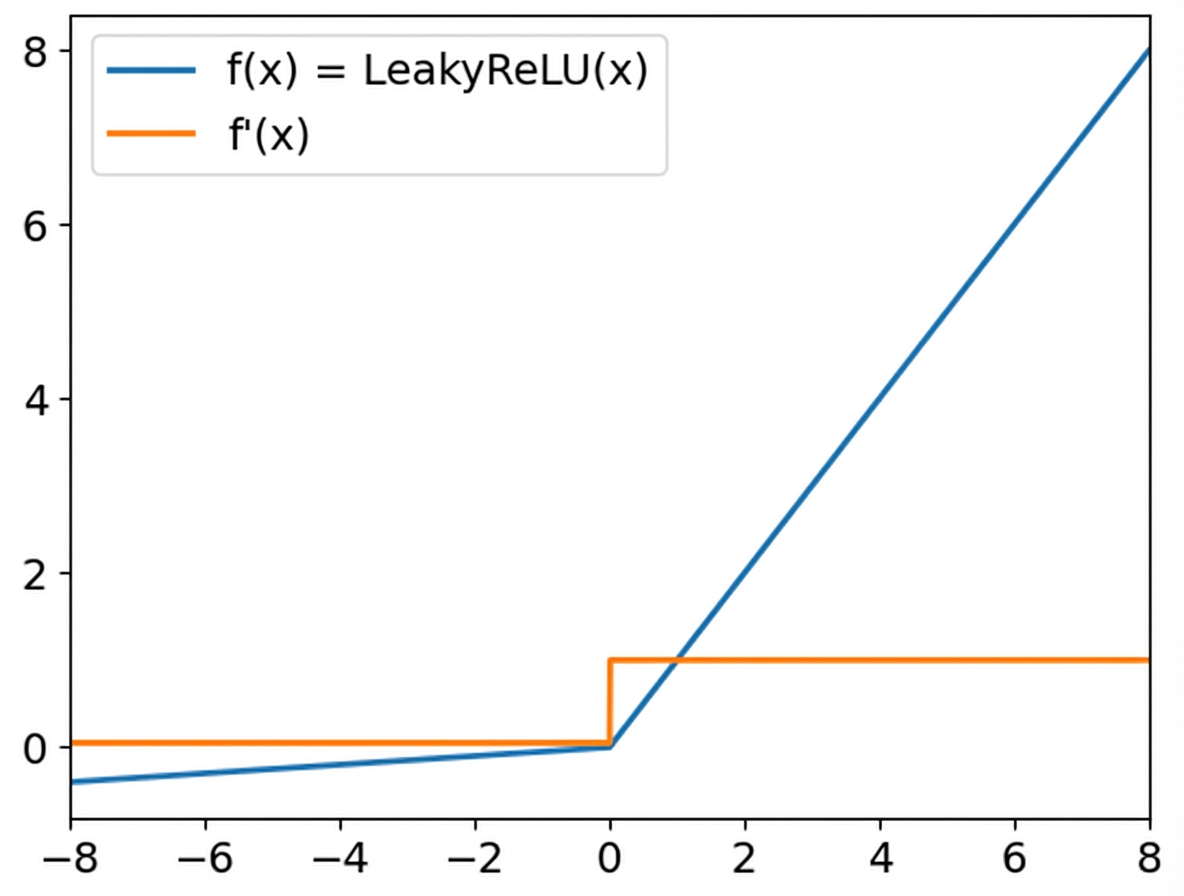
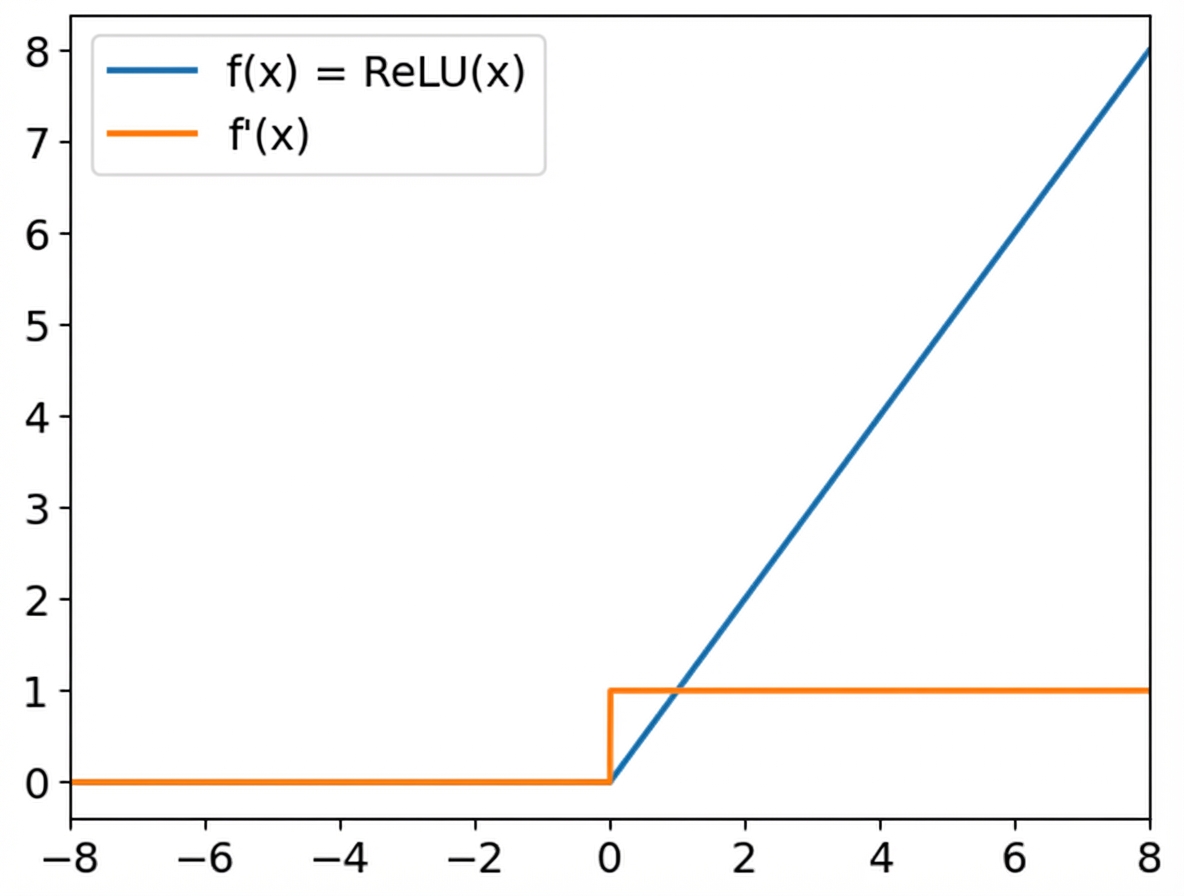
ReLU-Aktivierungsfunktionen
Einführung in Deep Learning mit PyTorch

Jasmin Ludolf
Senior Data Science Content Developer, DataCamp
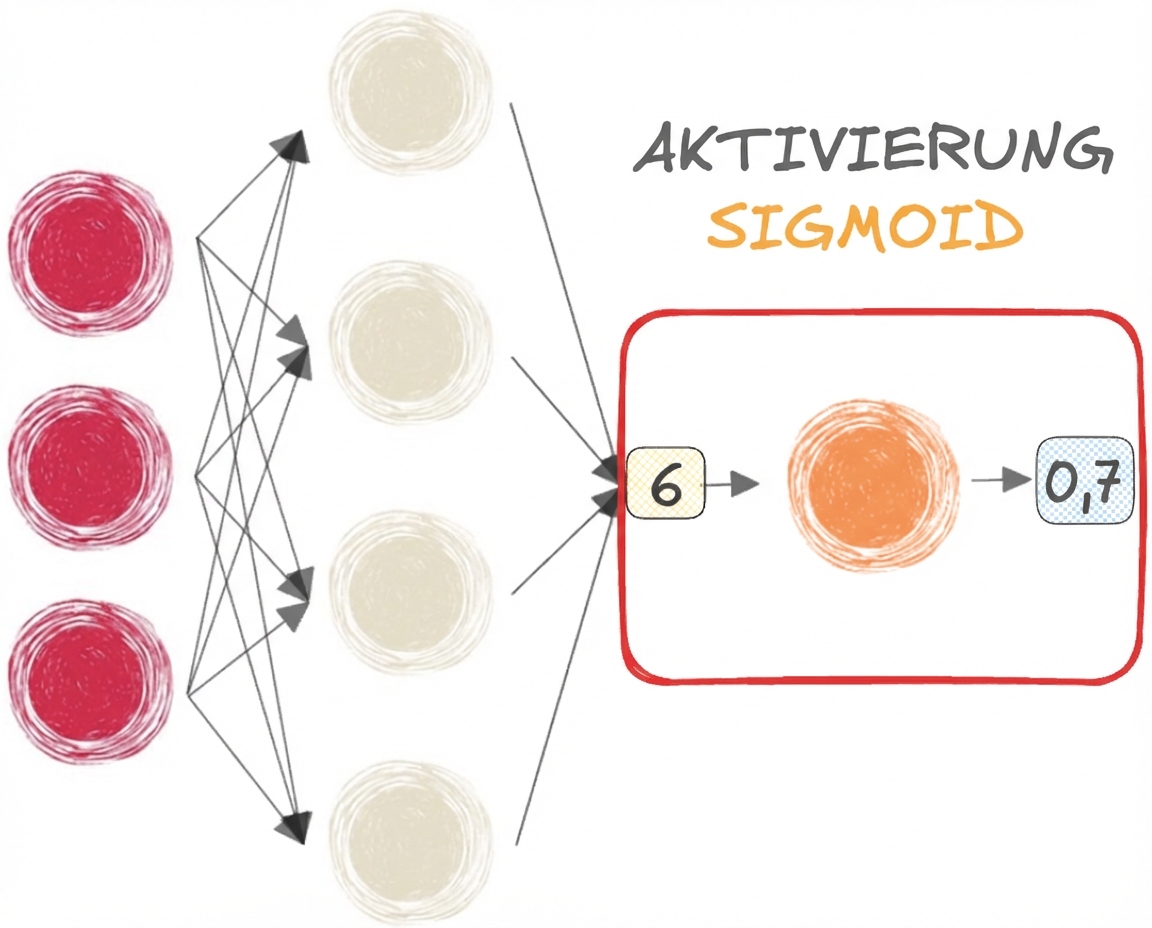
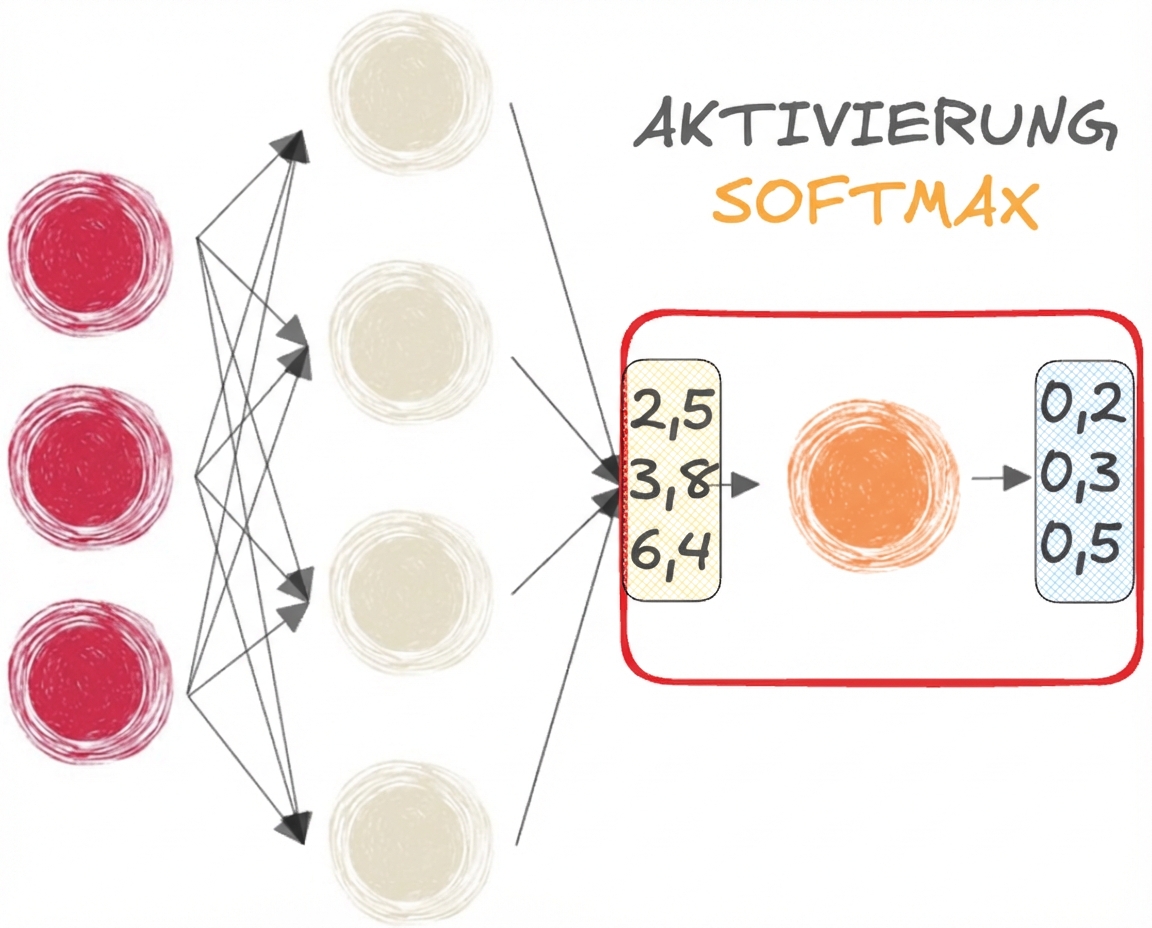
Sigmoid- und Softmax-Funktionen
$$
- SIGMOID für BINARY Klassifizierung
$$
- SOFTMAX für die MULTI-CLASS-Klassifizierung
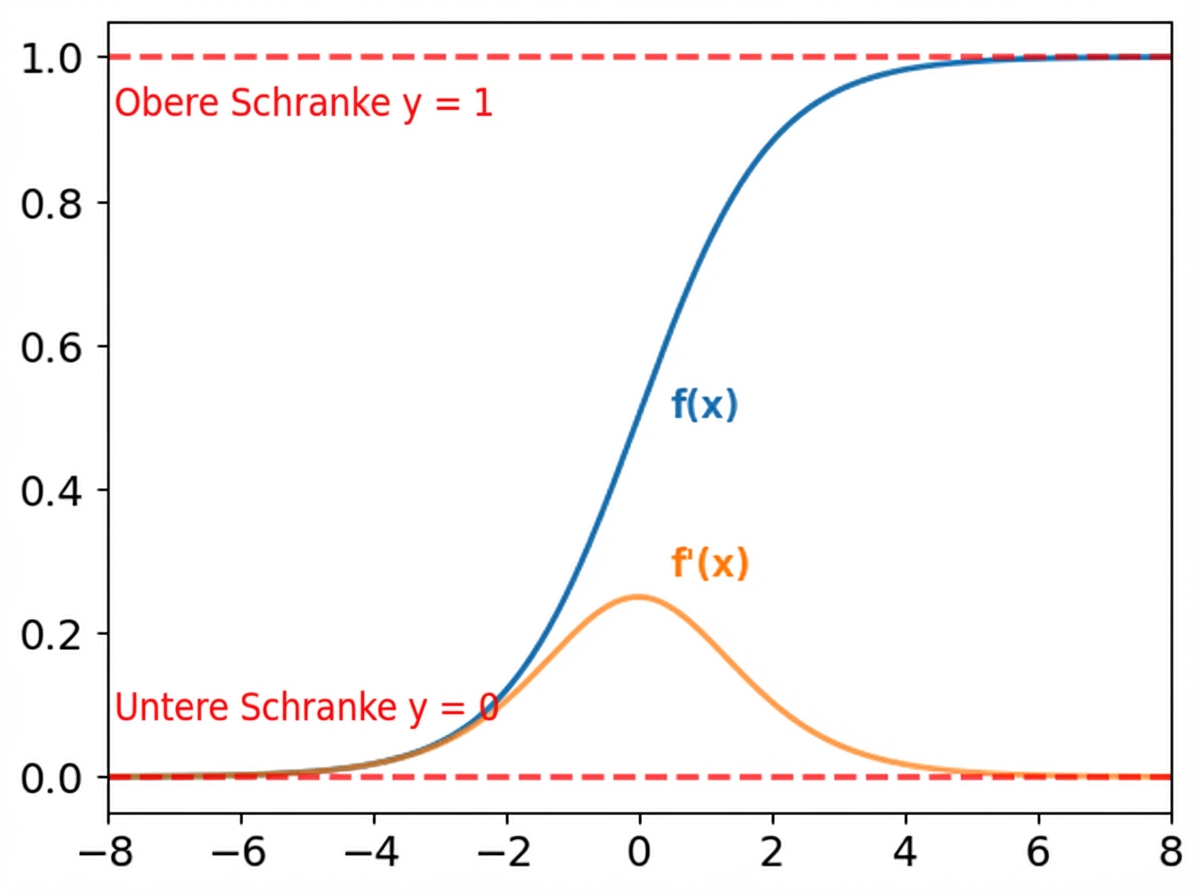
Grenzen der Sigmoid- und Softmax-Funktion
ReLU
Leaky ReLU