Lernrate und Momentum
Einführung in Deep Learning mit PyTorch

Jasmin Ludolf
Senior Data Science Content Developer, DataCamp
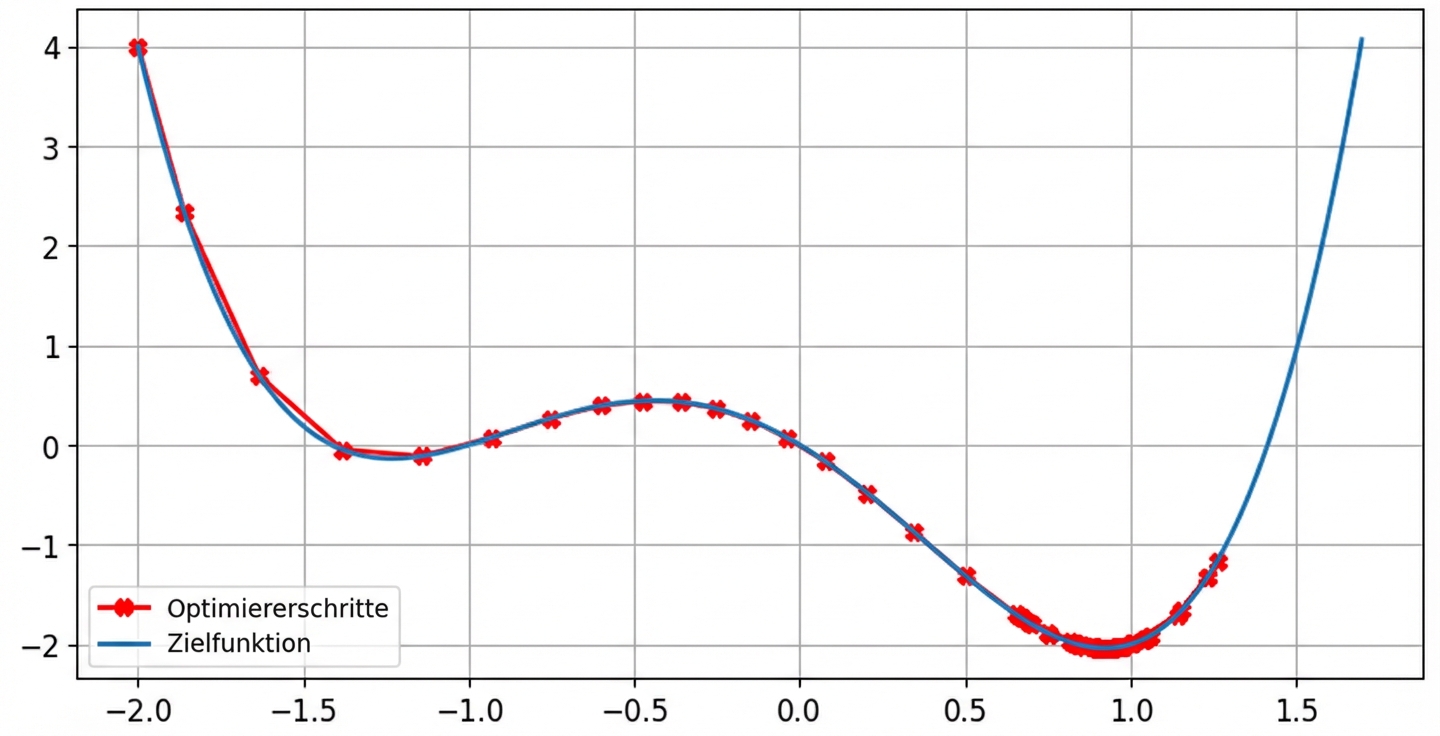
Auswirkungen der Lernrate: optimale Lernrate
- Die Schrittweite sinkt gegen Null, wenn der Gradient kleiner wird
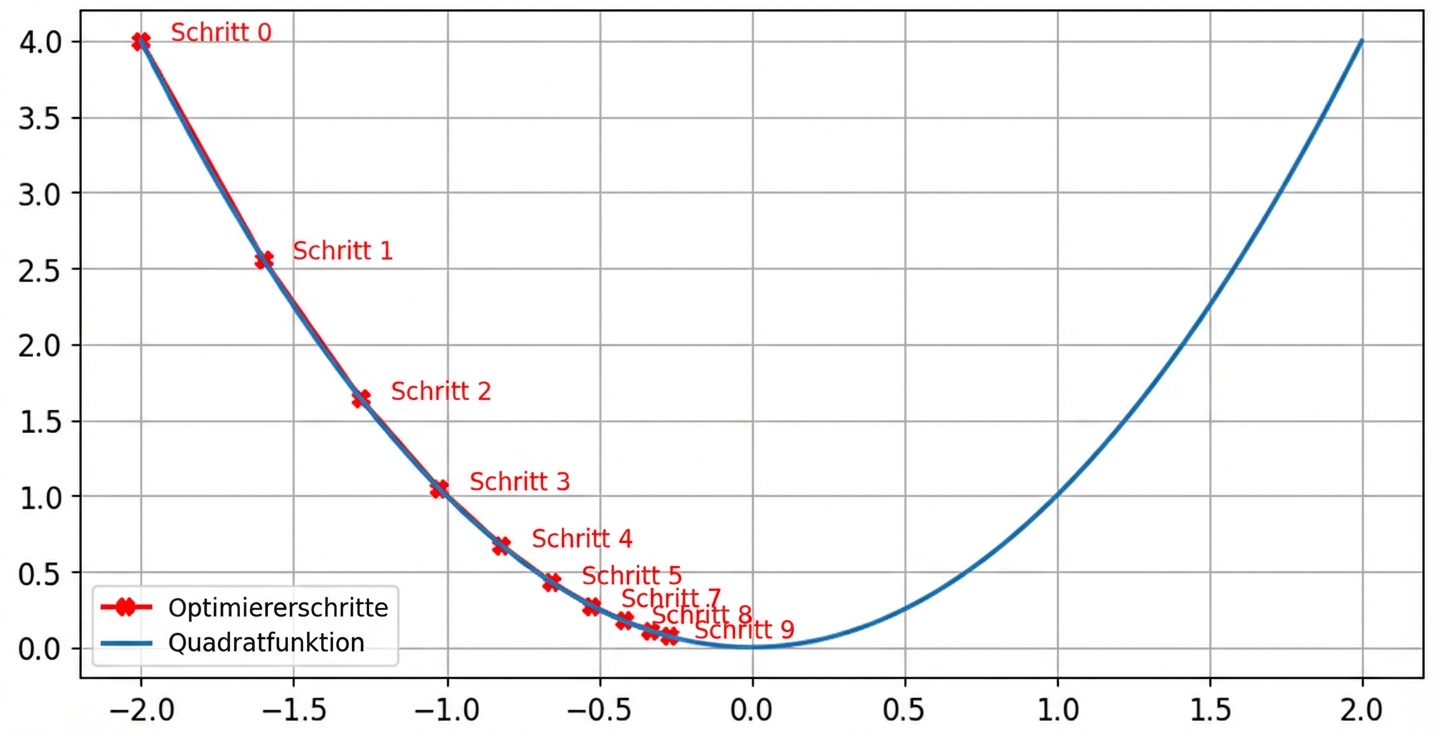
Auswirkungen der Lernrate: kleine Lernrate
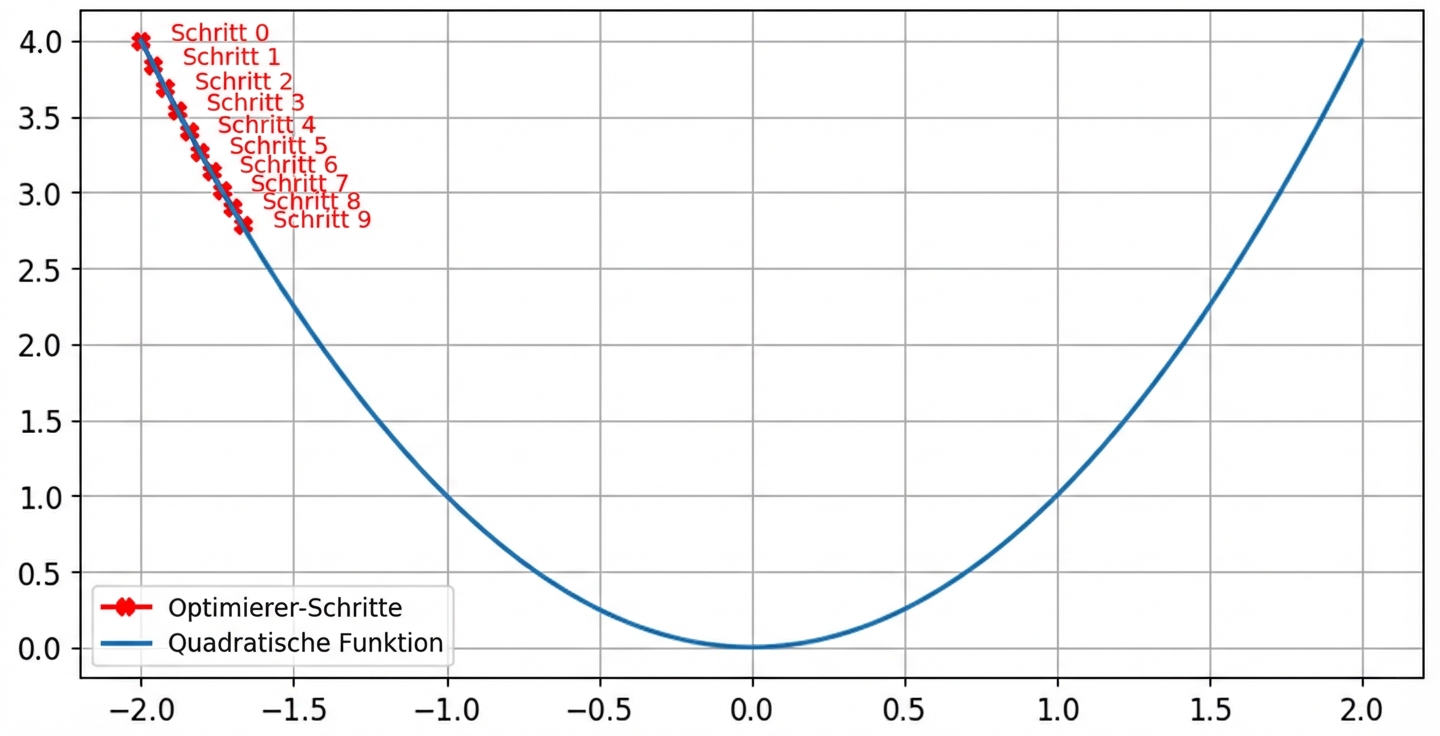
Auswirkungen der Lernrate: hohe Lernrate
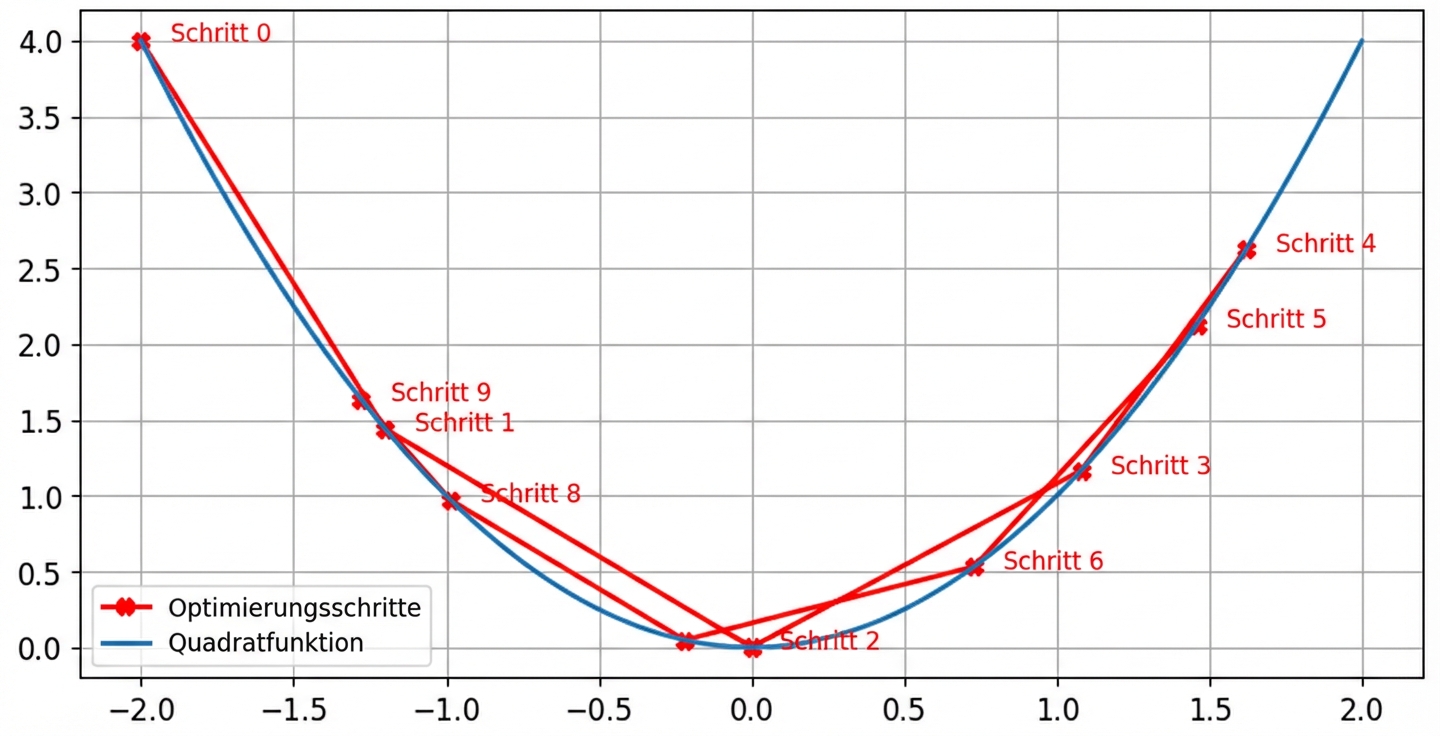
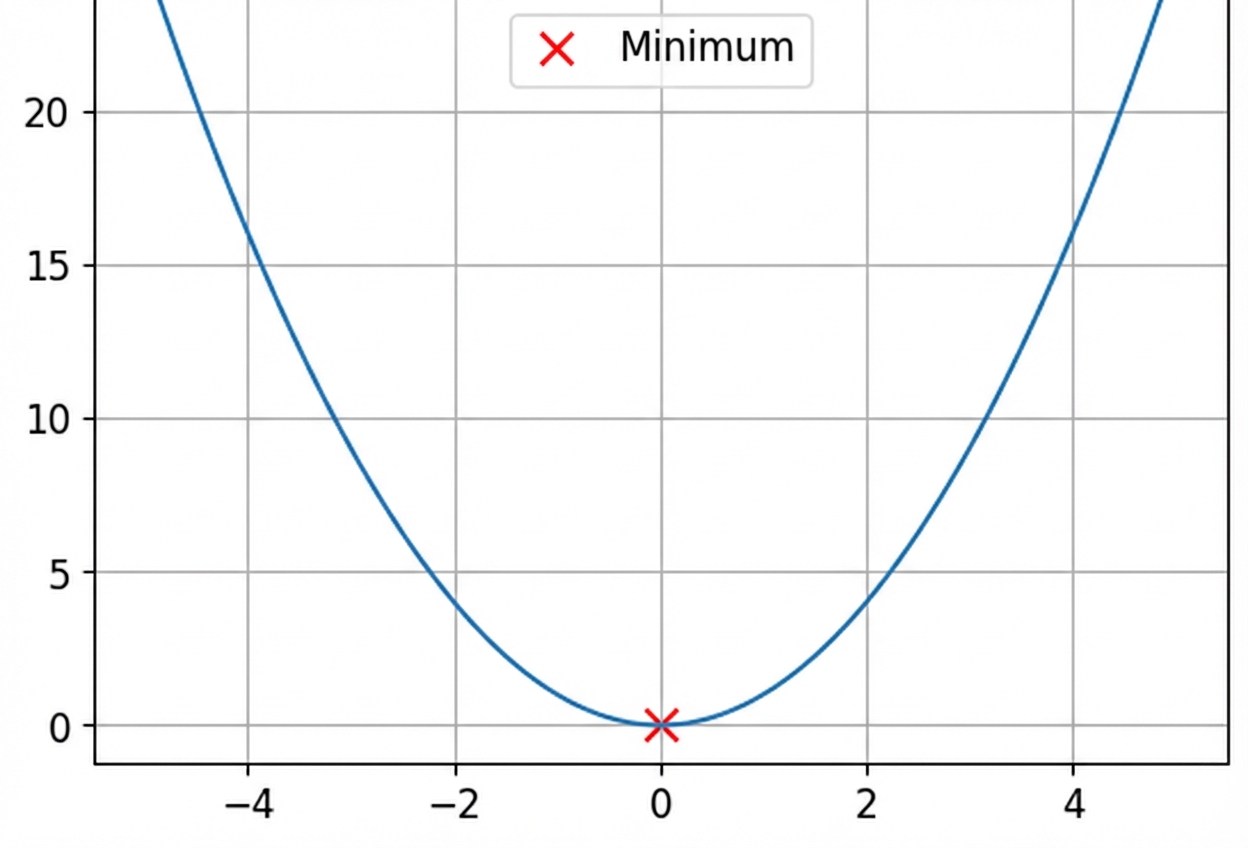
Konvexe und nicht-konvexe Funktionen
Dies ist eine konvexe Funktion.
Dies ist eine nicht-konvexe Funktion.
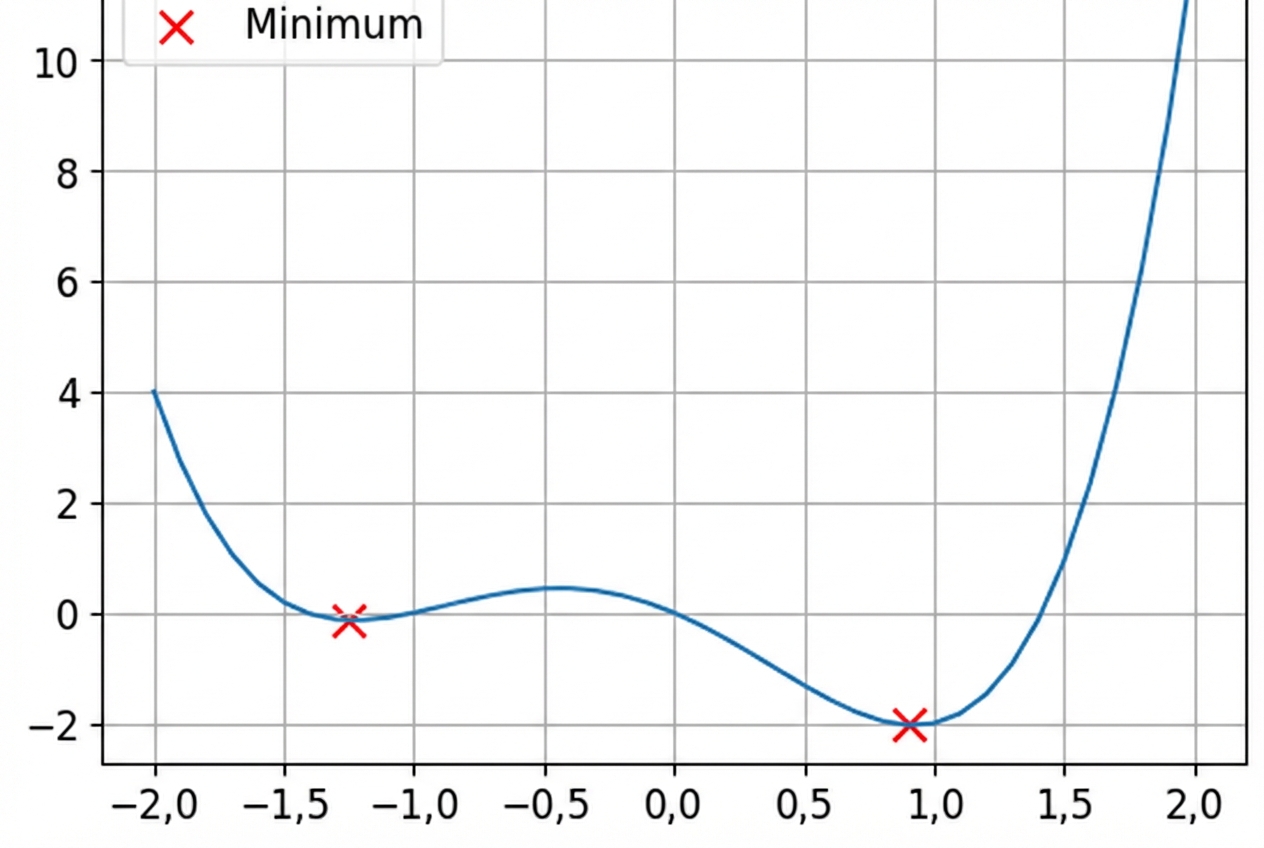
- Verlustfunktionen sind nicht konvex
Ohne Momentum
lr = 0.01momentum = 0nach 100 Schritten das Minimum gefunden fürx = -1.23undy = -0.14
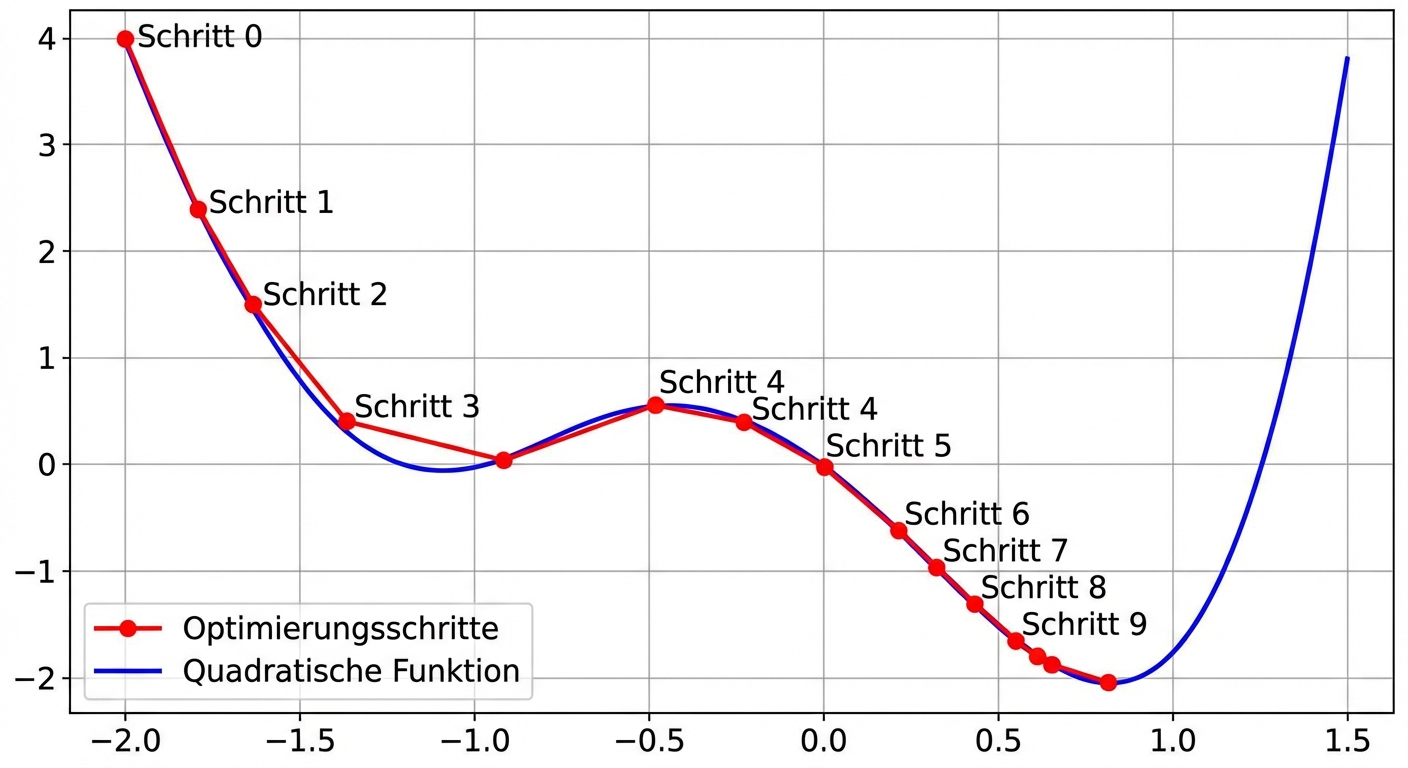
Mit Momentum
lr = 0.01momentum = 0.9nach 100 Schritten das Minimum gefunden fürx = 0.92undy = -2.04