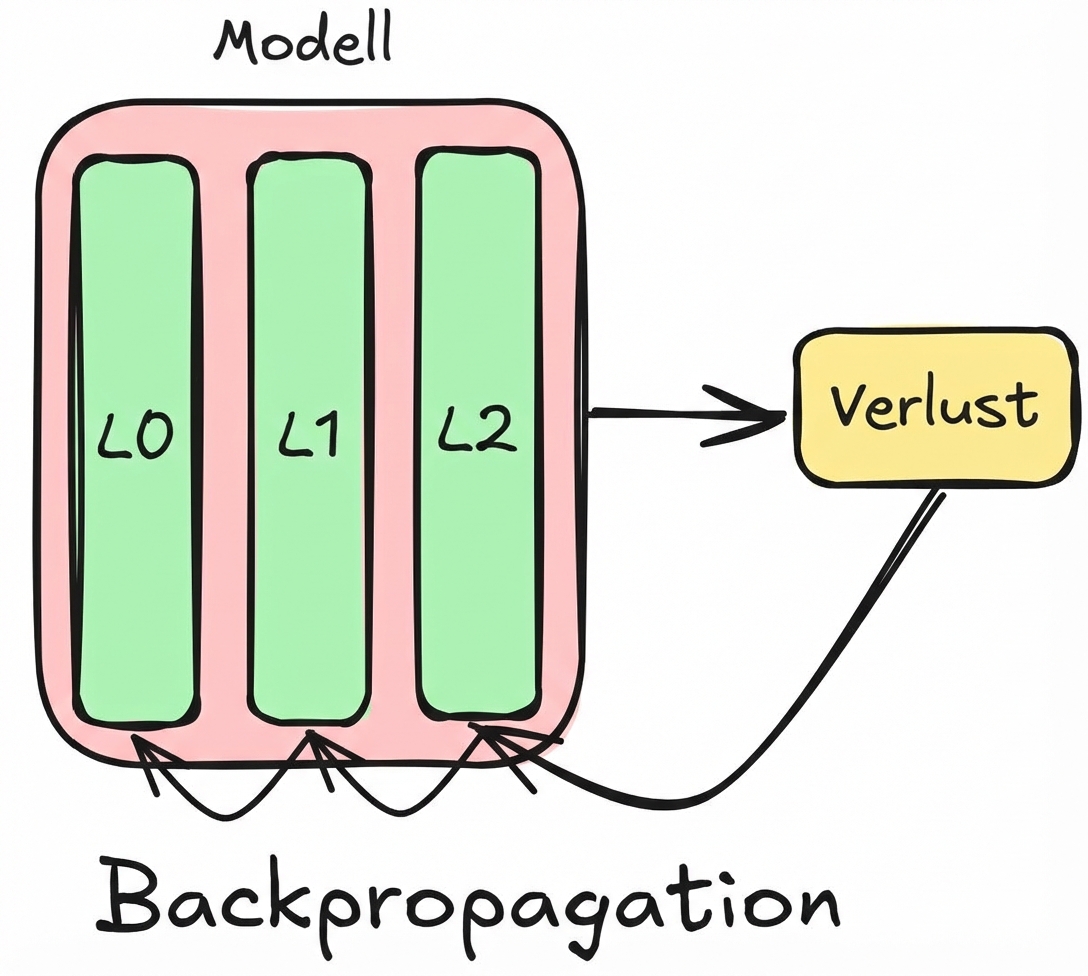
Ableitungen zur Aktualisierung der Modellparameter verwenden
Einführung in Deep Learning mit PyTorch

Jasmin Ludolf
Senior Data Science Content Developer, DataCamp
Eine Analogie für Derivate
$$

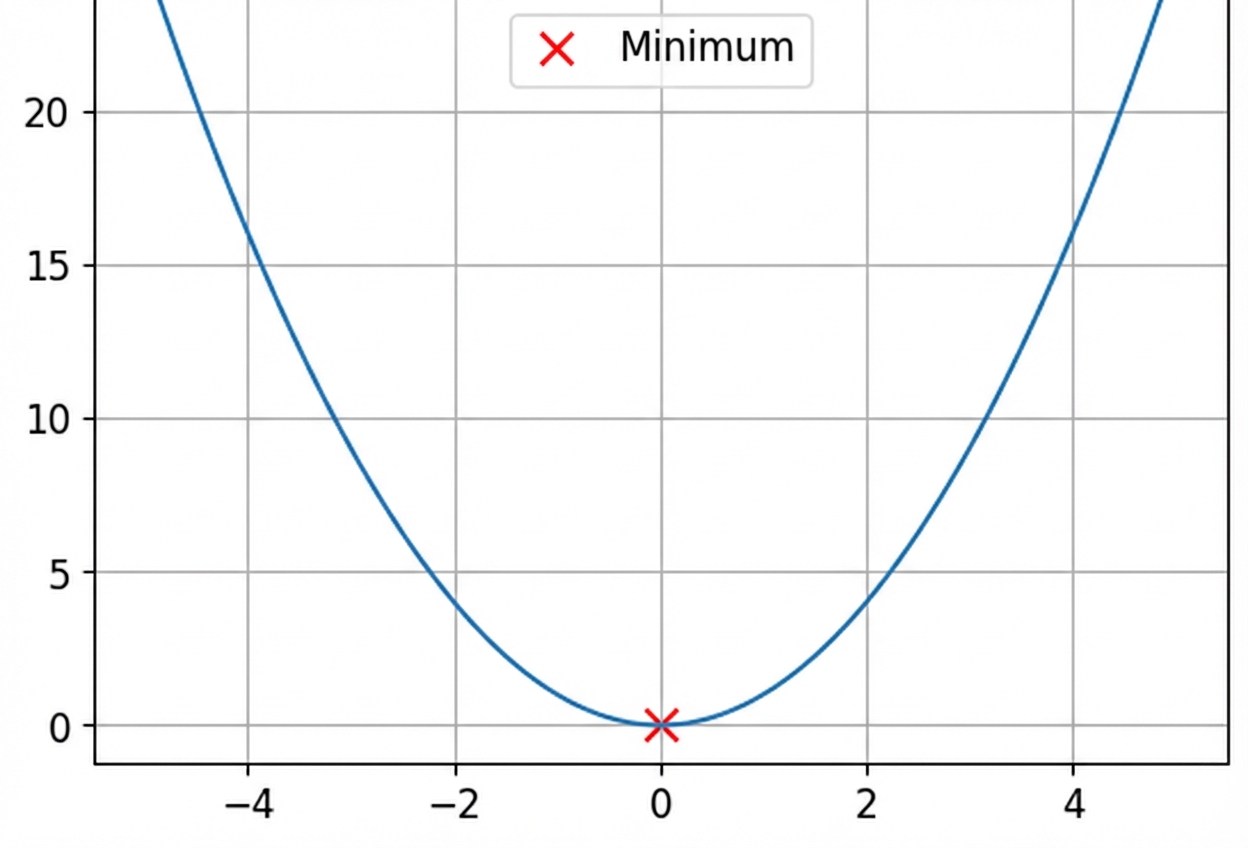
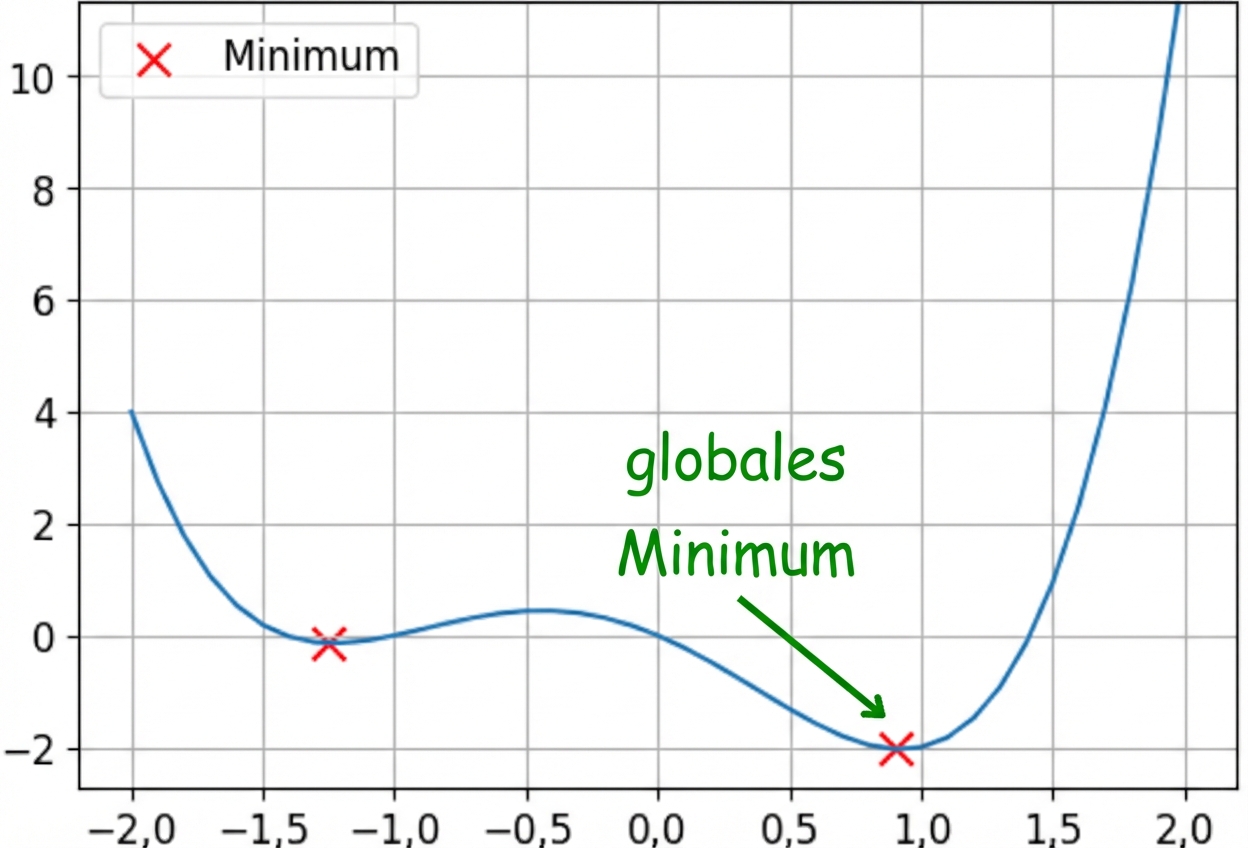
Konvexe und nicht-konvexe Funktionen
Dies ist eine konvexe Funktion
Dies ist eine nicht-konvexe Funktion
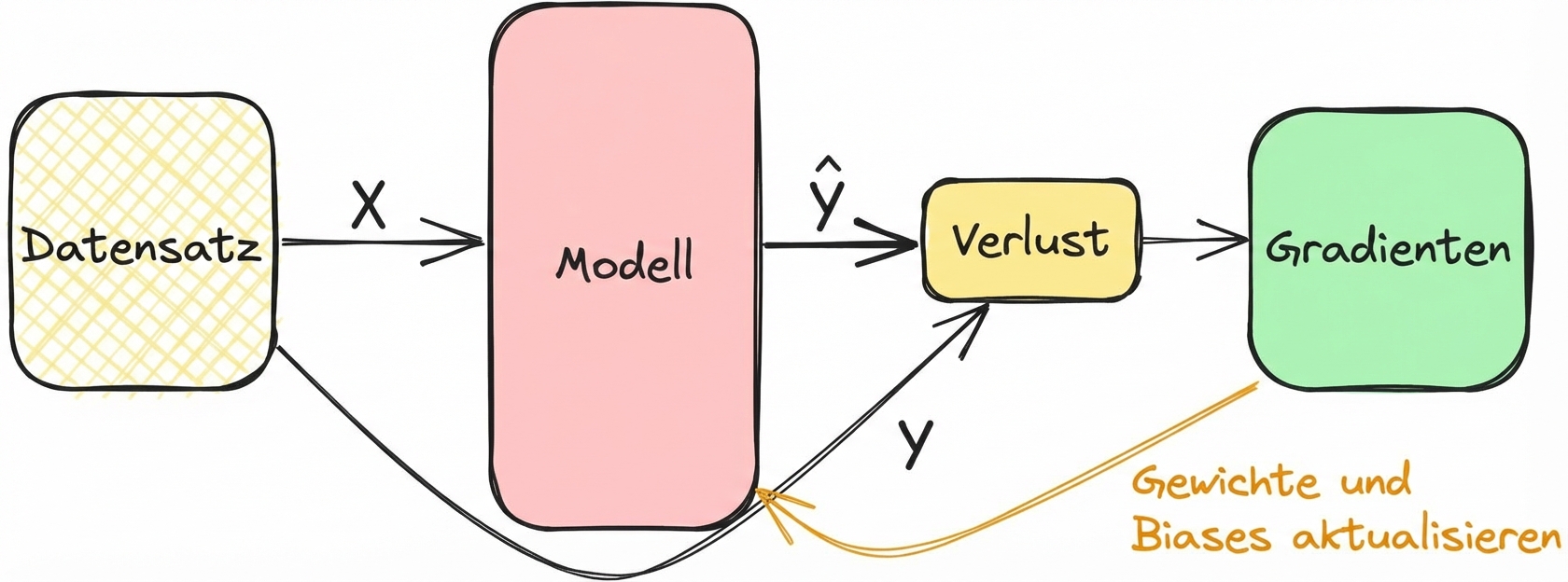
Derivate und Training von Modellen verbinden
- Berechne den Verlust im Vorwärtsdurchlauf während des Trainings
$$
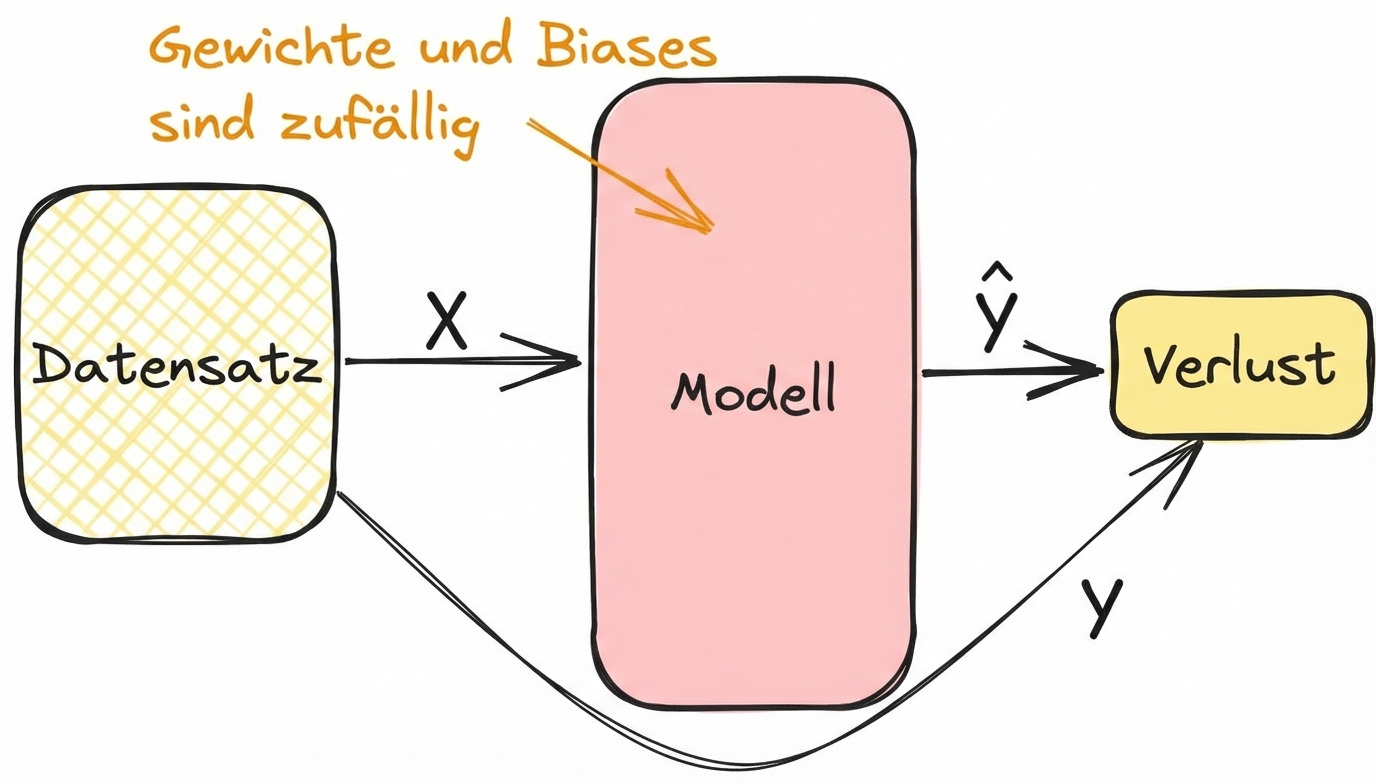
Derivate und Training von Modellen verbinden
- Gradienten helfen, Verluste zu minimieren, Schichtgewichte und Verzerrungen abzustimmen
- Wiederhole den Vorgang, bis die Schichten aufeinander abgestimmt sind
$$
Backpropagation-Konzepte