Umgang mit fehlenden Daten
Explorative Datenanalyse in Python

George Boorman
Curriculum Manager, DataCamp
Warum sind fehlende Daten ein Problem?
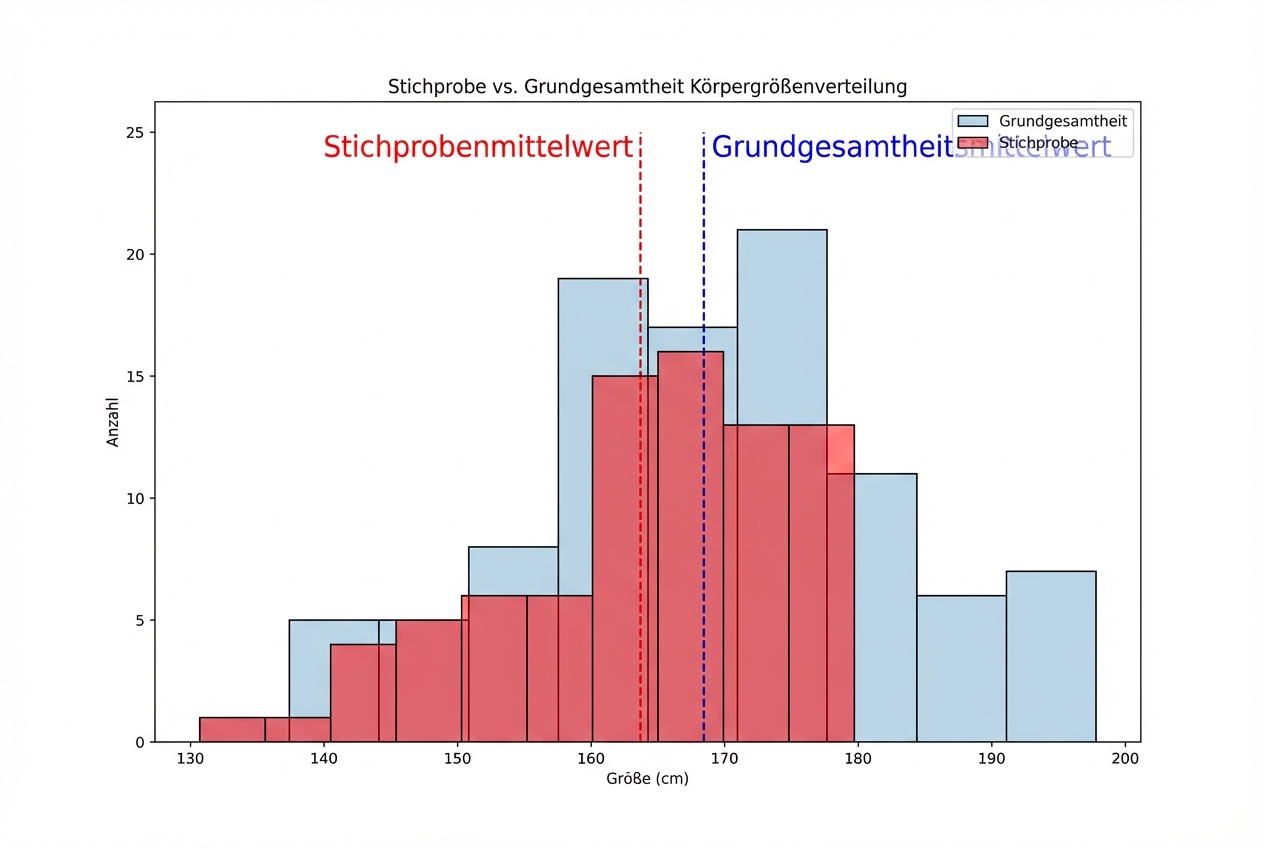
Gehalt nach Erfahrungsniveau
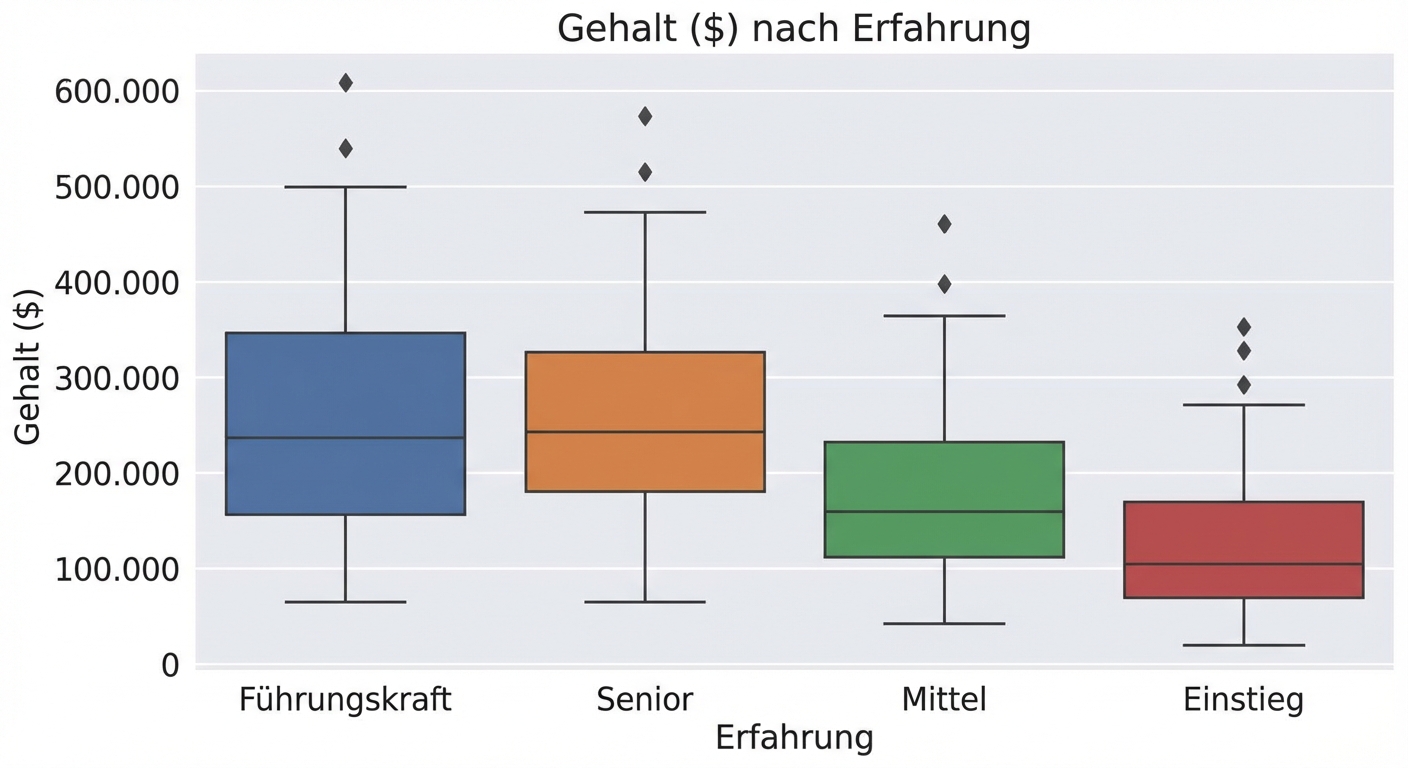
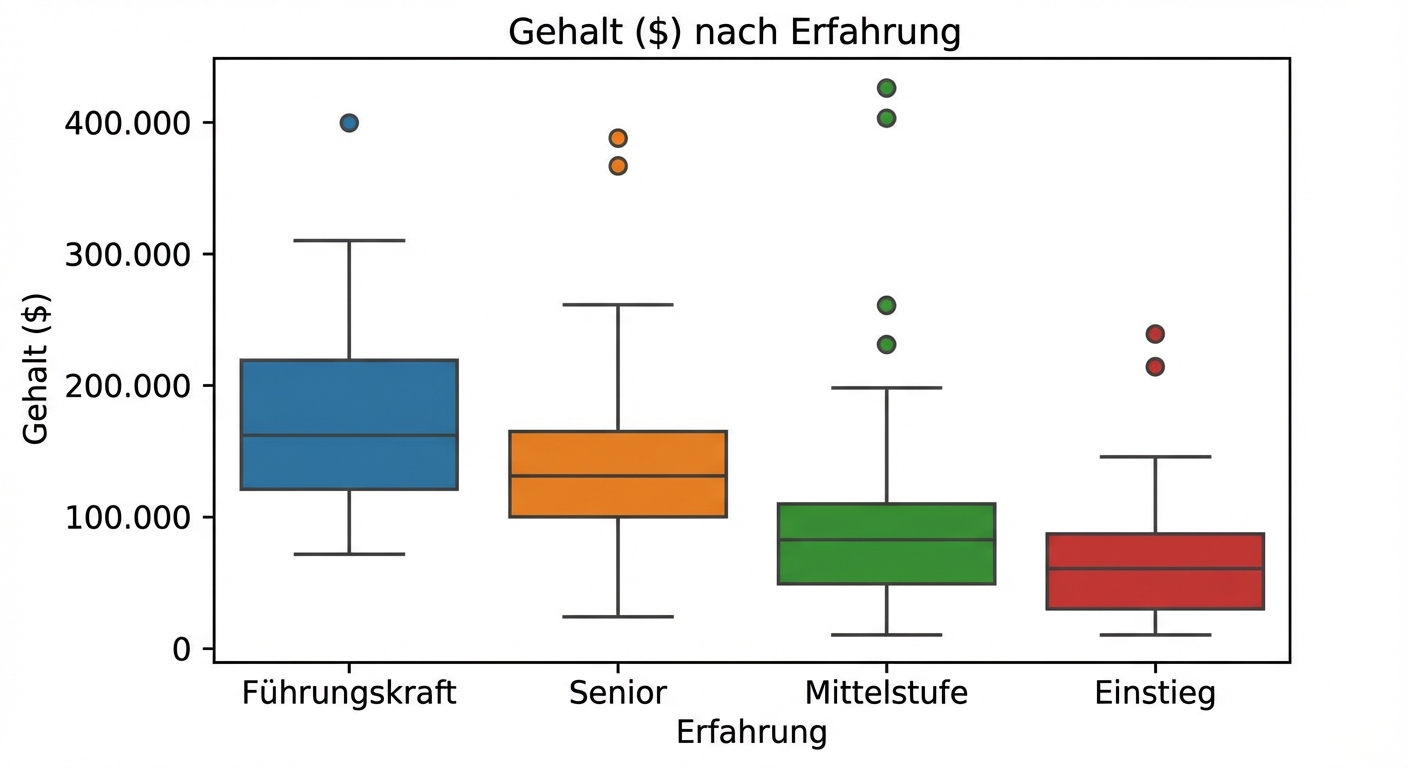
Explorative Datenanalyse in Python
George Boorman
Curriculum Manager, DataCamp

