Der zentrale Grenzwertsatz
Einführung in die Statistik in Python

Maggie Matsui
Content Developer, DataCamp
5 Mal würfeln

Stichprobenverteilungen
Stichprobenverteilung des Stichprobenmittelwerts
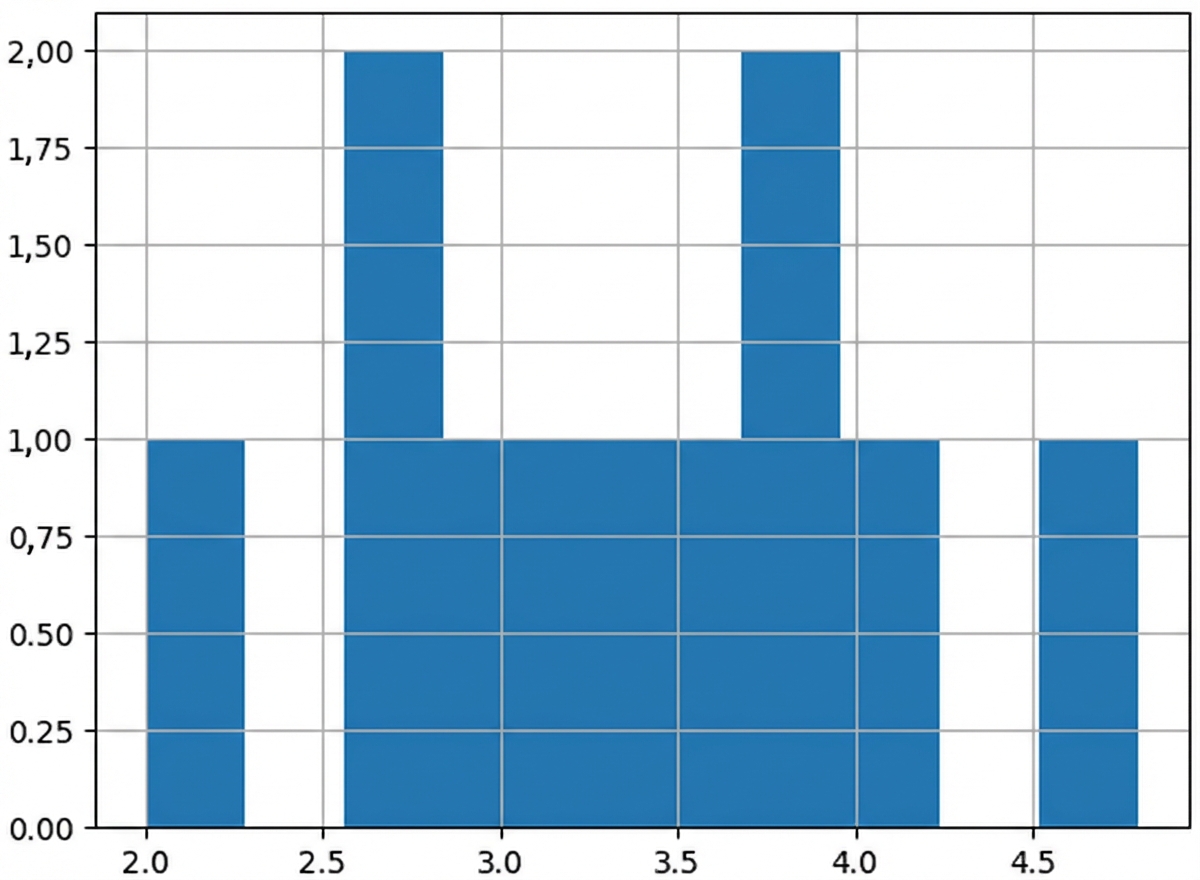
Mittelwerte von 100 Stichproben
sample_means = []
for i in range(100):
sample_means.append(np.mean(die.sample(5, replace=True)))
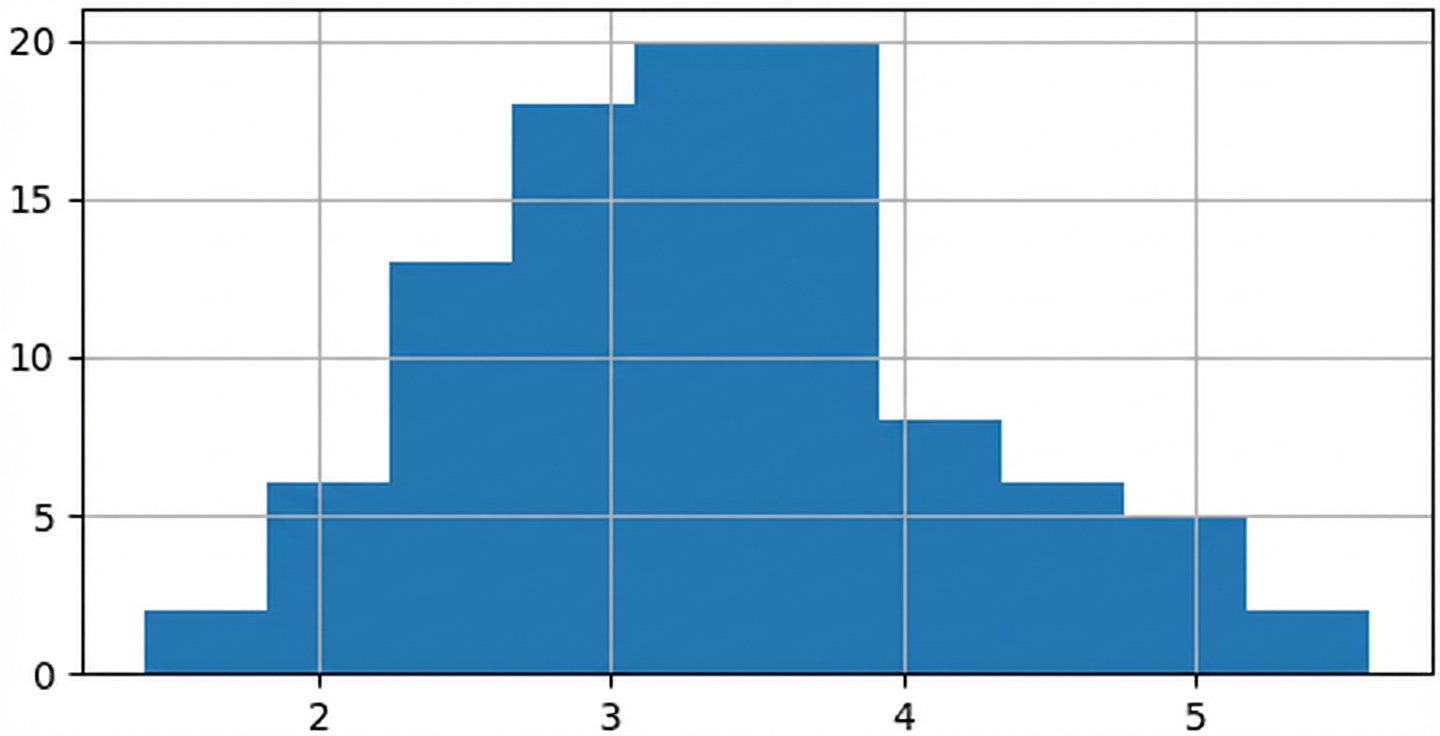
Mittelwerte von 1.000 Stichproben
sample_means = []
for i in range(1000):
sample_means.append(np.mean(die.sample(5, replace=True)))
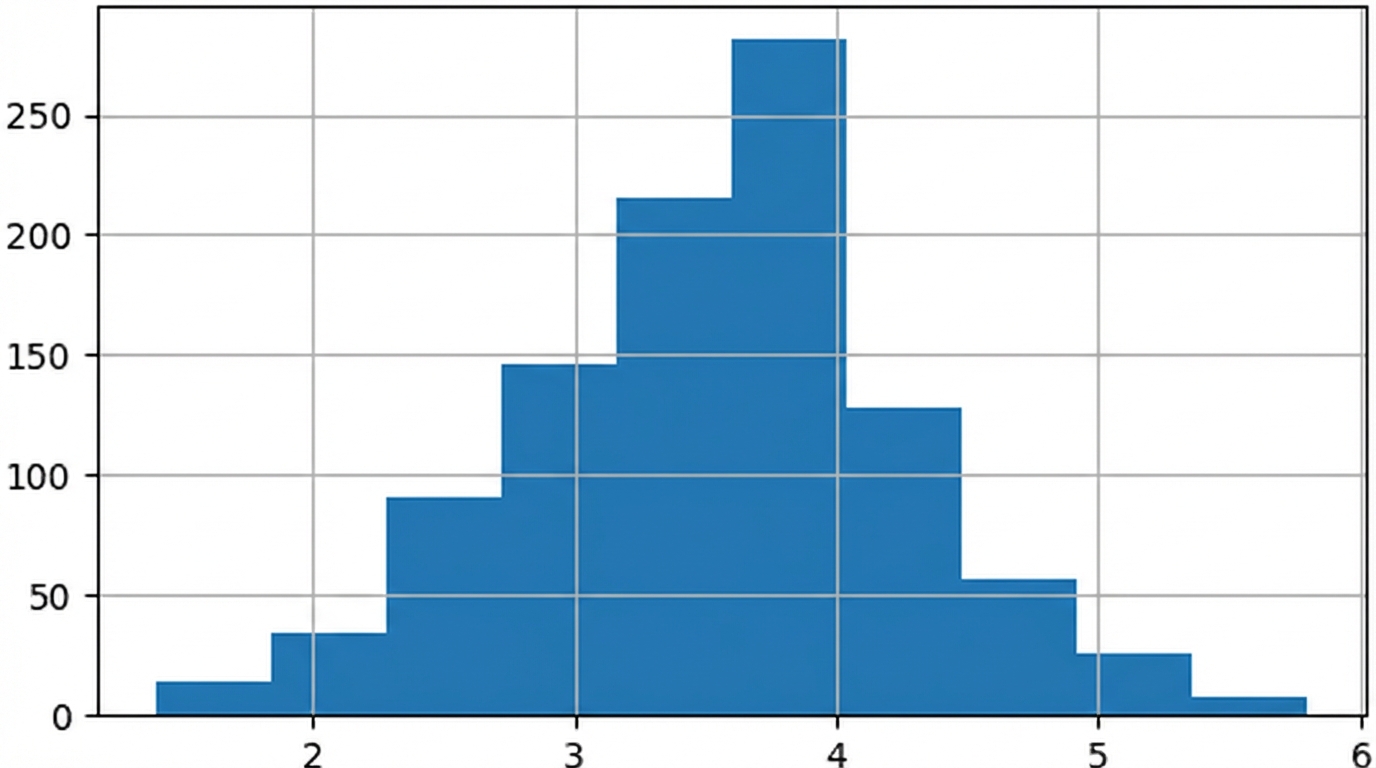
Zentraler Grenzwertsatz
Die Stichprobenverteilung einer Statistik nähert sich mit zunehmender Anzahl von Versuchen immer mehr der Normalverteilung an.
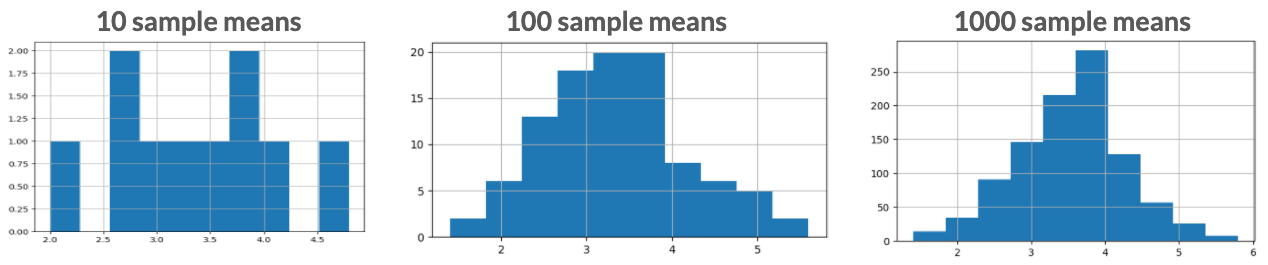Histogramme von 10, 100 und 1000 Stichprobenmittelwerten, wobei eine höhere Anzahl von Stichprobenmittelwerten eine glockenförmigere Verteilung aufweist](https://assets.datacamp.com/img/translations/de-DE/production/repositories/5786/datasets/68c668ba8e7538984edc15be7f82f1855ad2dc41/Screen%20Shot%202020-07-16%20at%204.48.14%20PM.png)
- Stichproben sollten zufällig und unabhängig sein
Standardabweichung und der Grenzwertsatz
sample_sds = []
for i in range(1000):
sample_sds.append(np.std(die.sample(5, replace=True)))
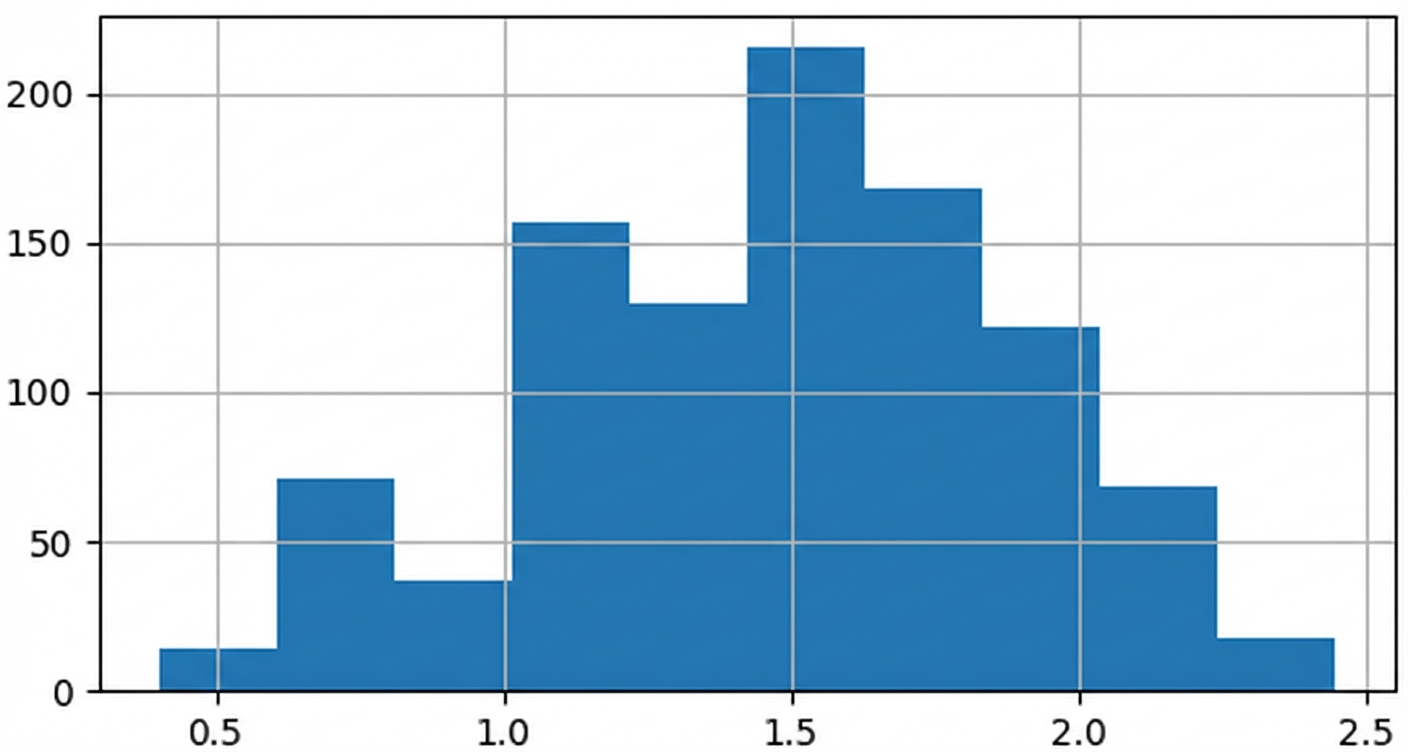
Stichprobenverteilung der Mengenanteile
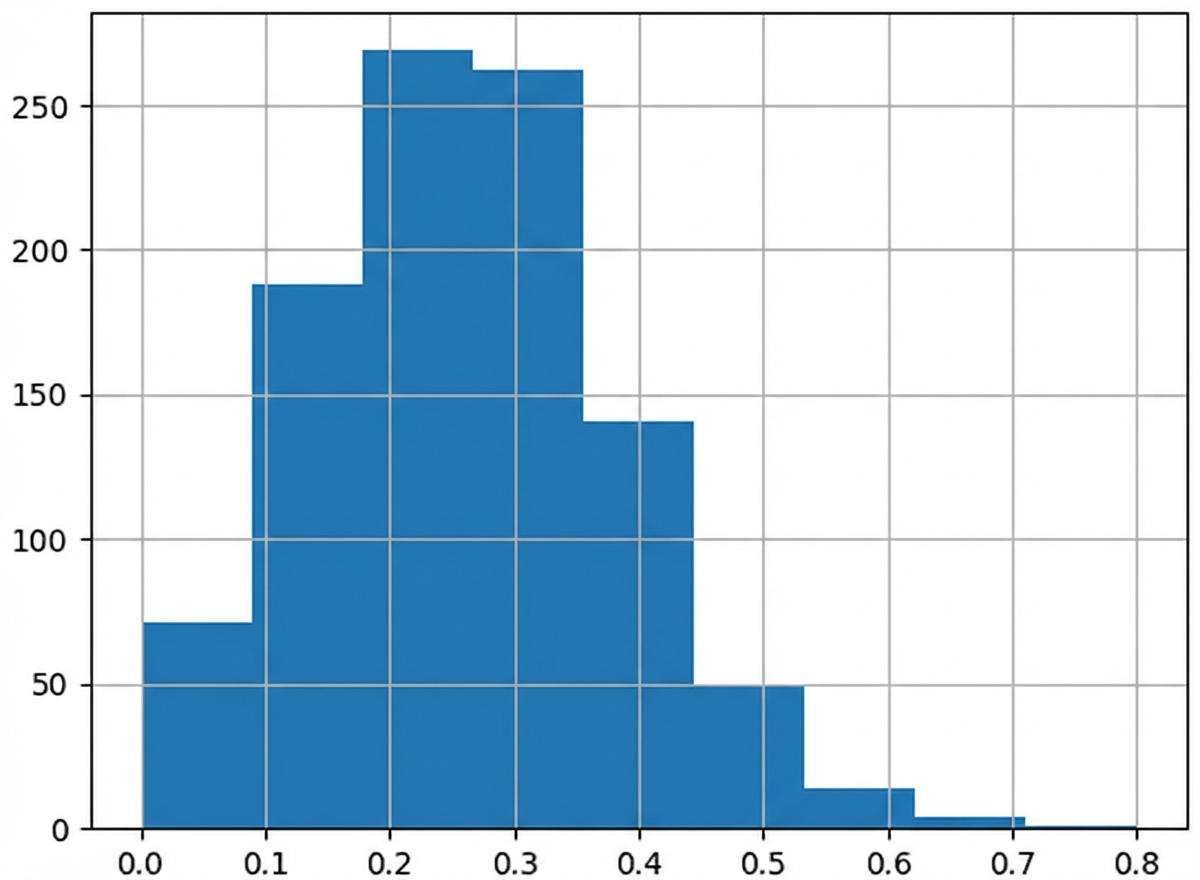
Mittelwert der Stichprobenverteilung
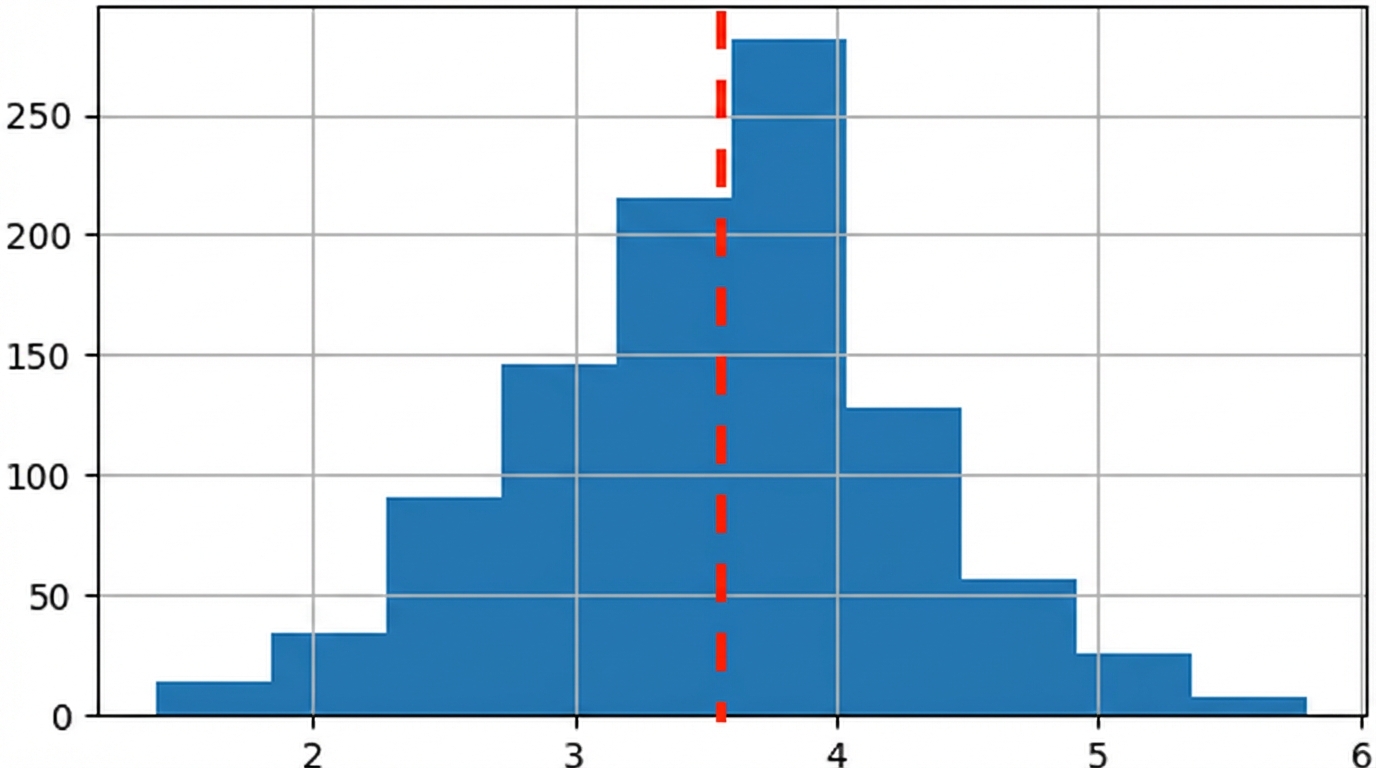
- Merkmale der unbekannten zugrunde liegenden Verteilung schätzen
- Einfachere Schätzung von Merkmalen großer Populationen

