Der zentrale Grenzwertsatz
Einführung in die Statistik in R

Maggie Matsui
Content Developer, DataCamp
5 mal würfeln

Stichprobenverteilungen
Stichprobenverteilung des Stichprobenmittelwerts
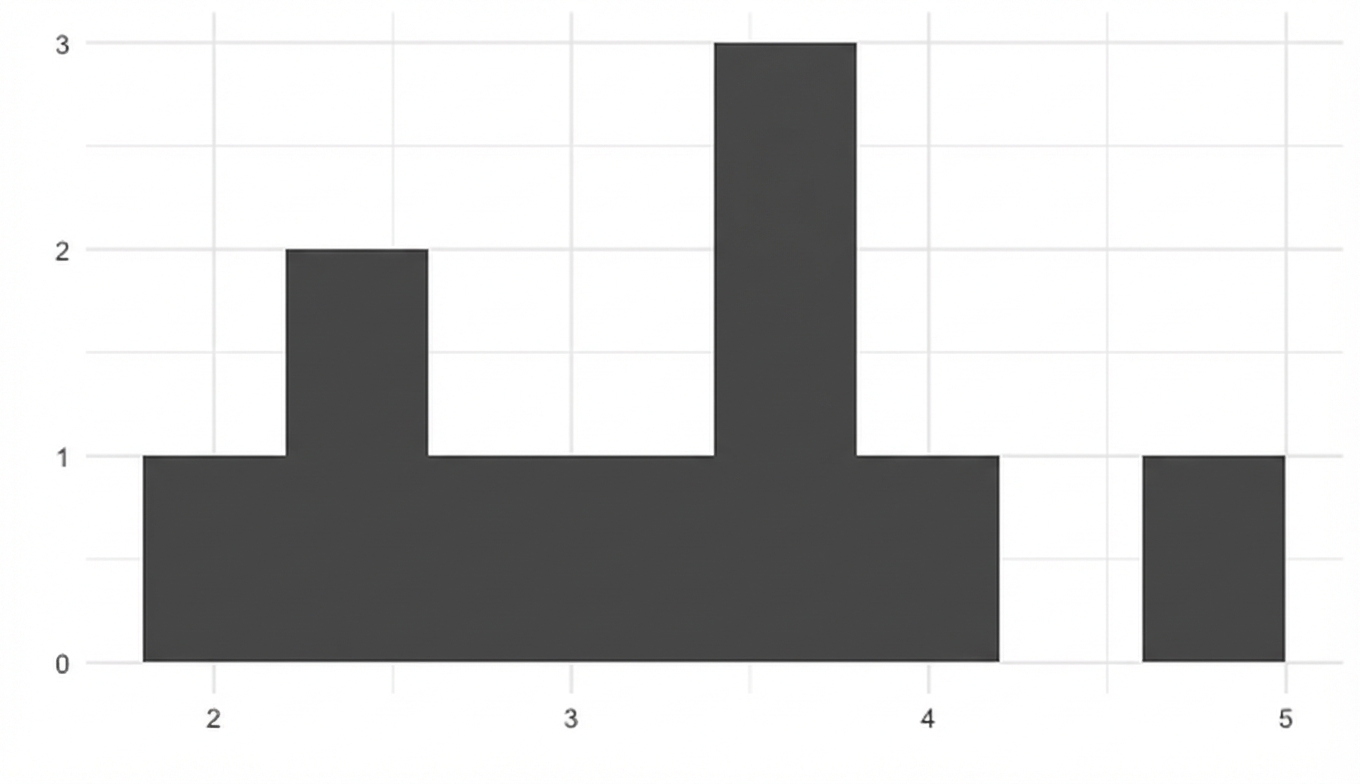
Mittelwerte von 100 Stichproben
replicate(100, sample(die, 5, replace = TRUE) %>% mean())
2.8 3.2 1.8 4.6 4.0 2.8 4.4 2.4 3.4 2.8 4.2 3.4 ... 2.2 3.8 3.6 3.8 4.4 4.8 2.4
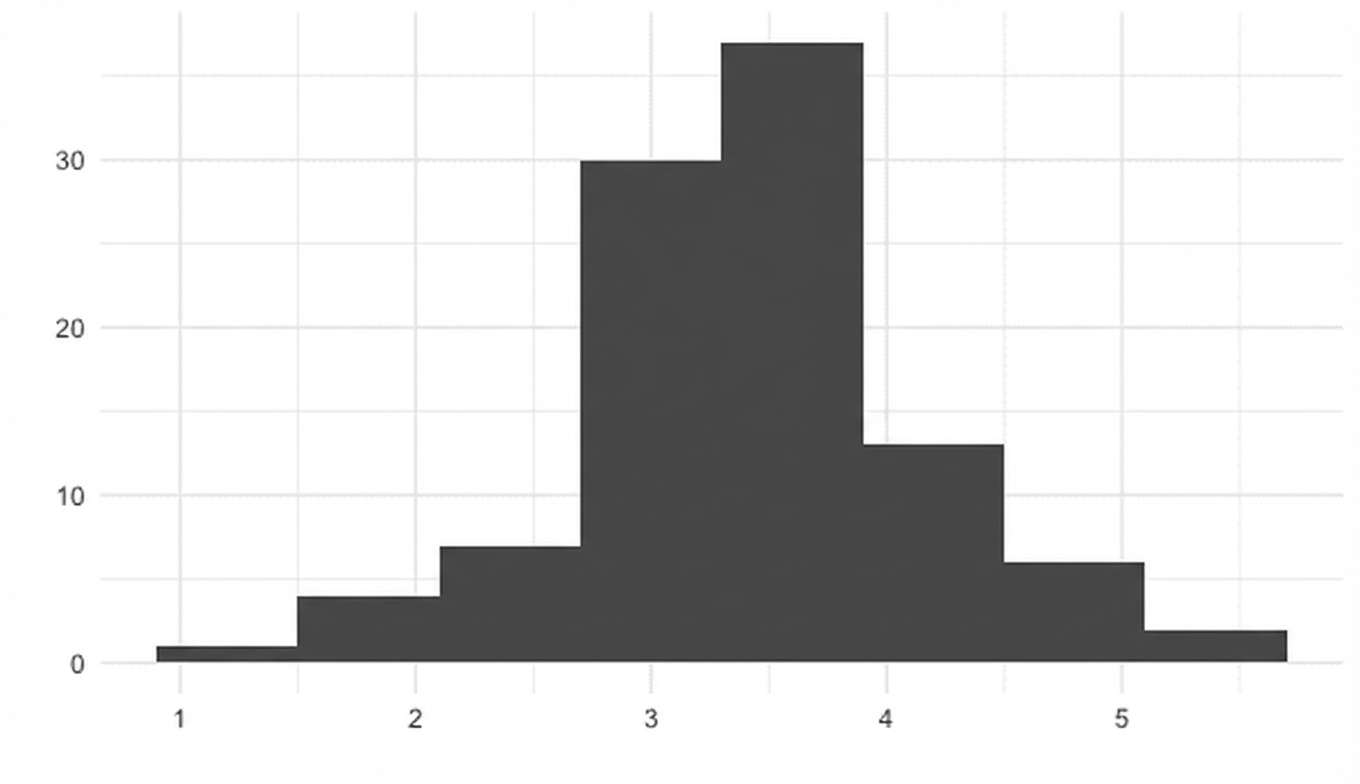
Mittelwerte von 1000 Stichproben
sample_means <- replicate(1000, sample(die, 5, replace = TRUE) %>% mean())
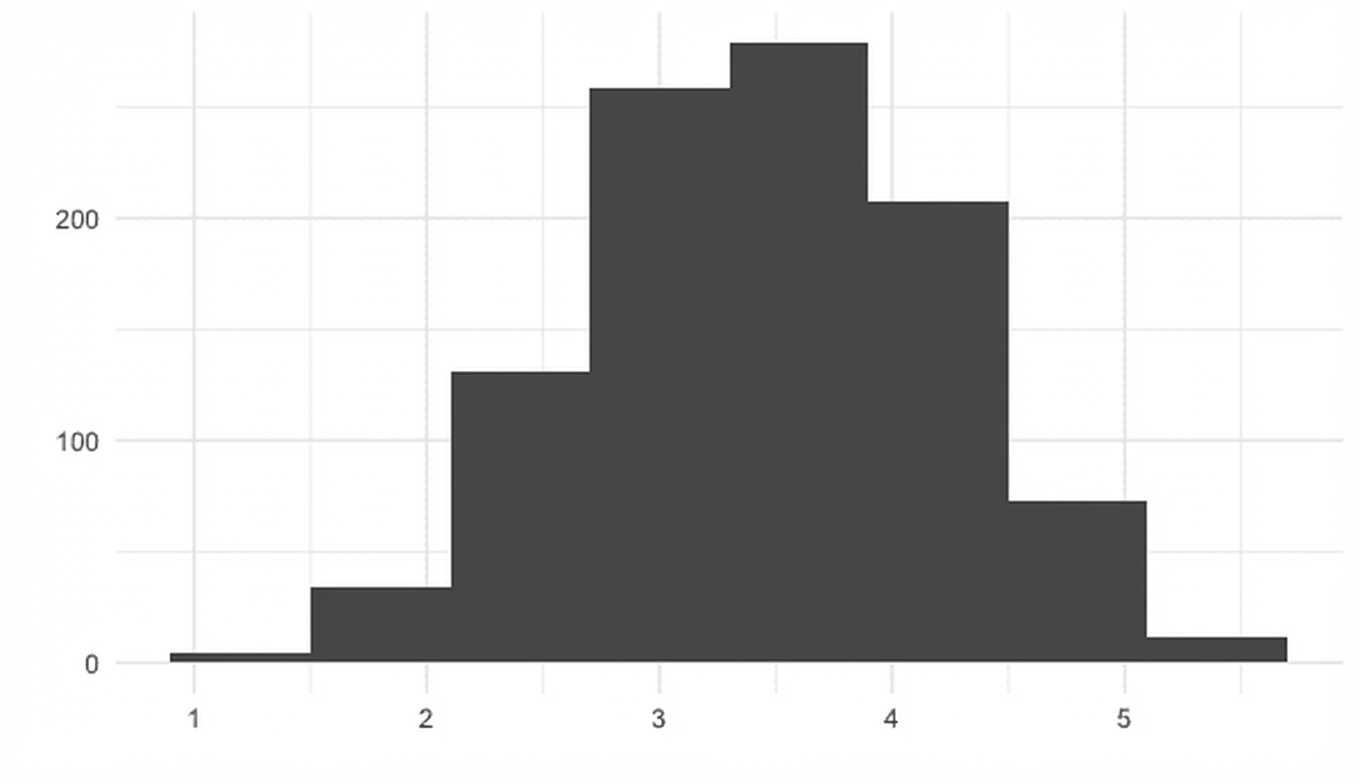
Zentraler Grenzwertsatz
Die Stichprobenverteilung einer Statistik nähert sich mit zunehmender Anzahl von Versuchen immer mehr der Normalverteilung an.
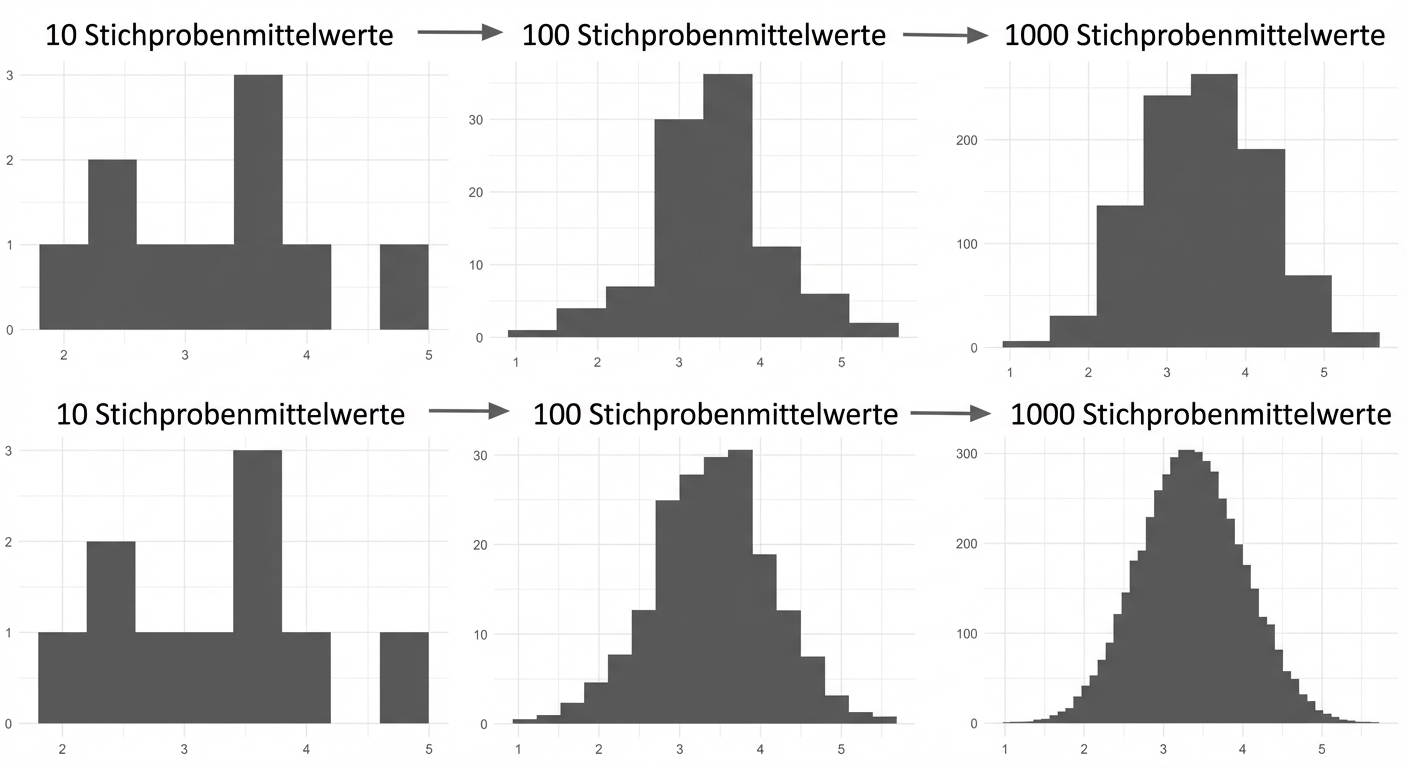
- Stichproben sollten zufällig und unabhängig sein
Standardabweichung und der Grenzwertsatz
replicate(1000, sample(die, 5, replace = TRUE) %>% sd())
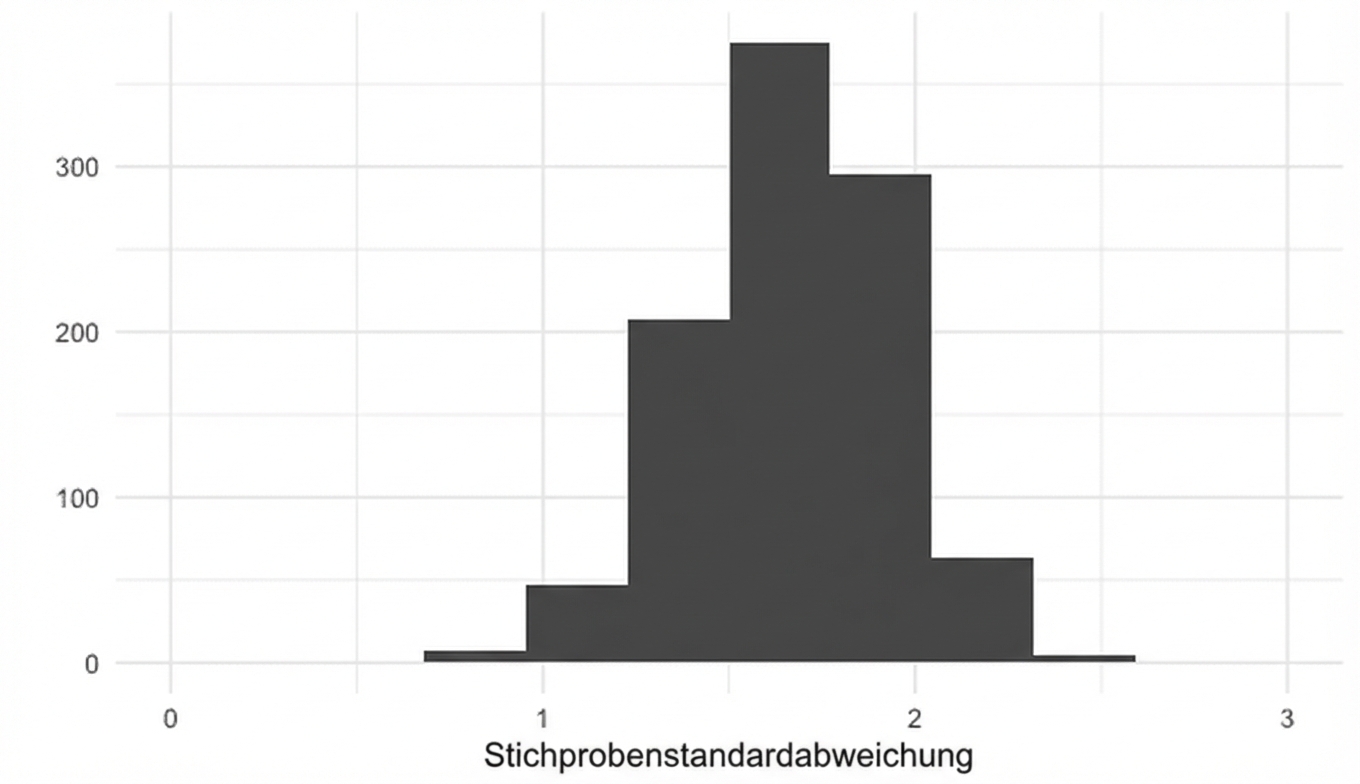
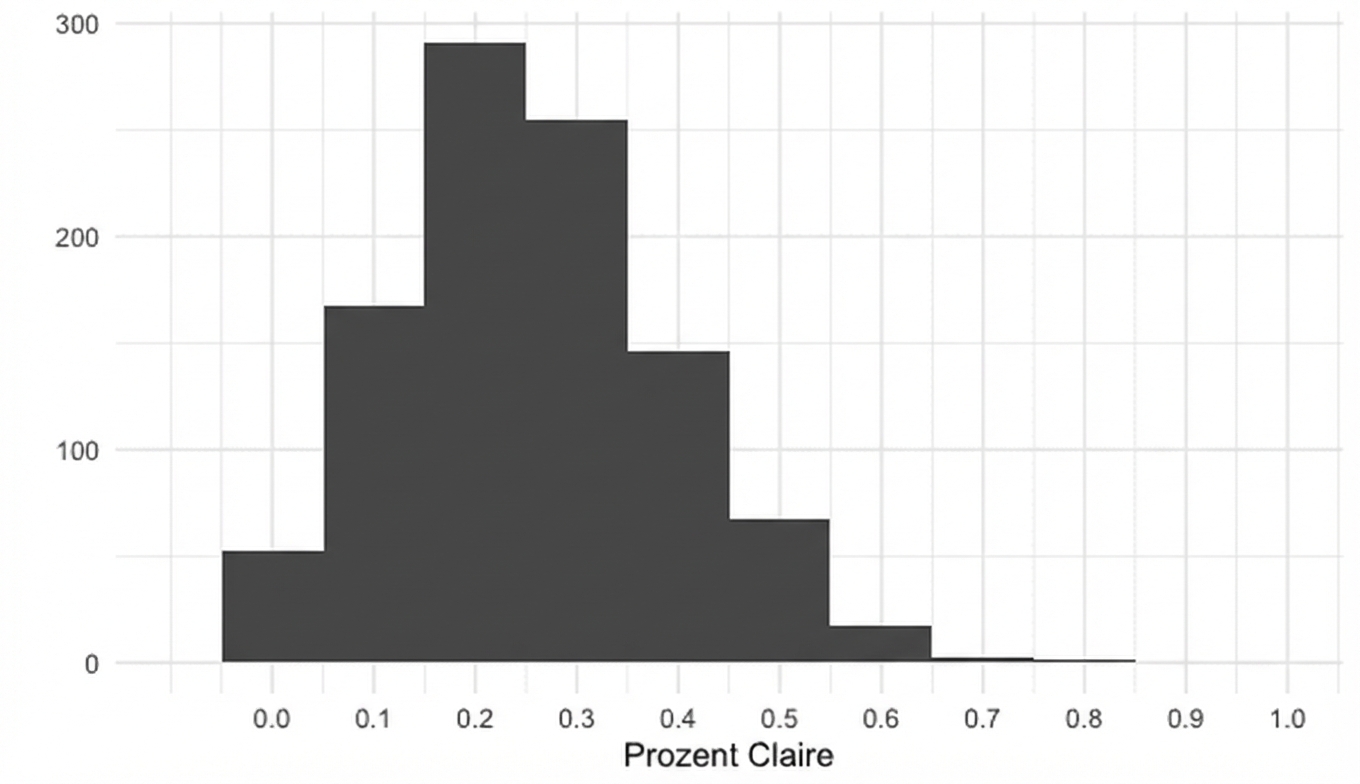
Stichprobenverteilung der Mengenanteile
Mittelwert der Stichprobenverteilung
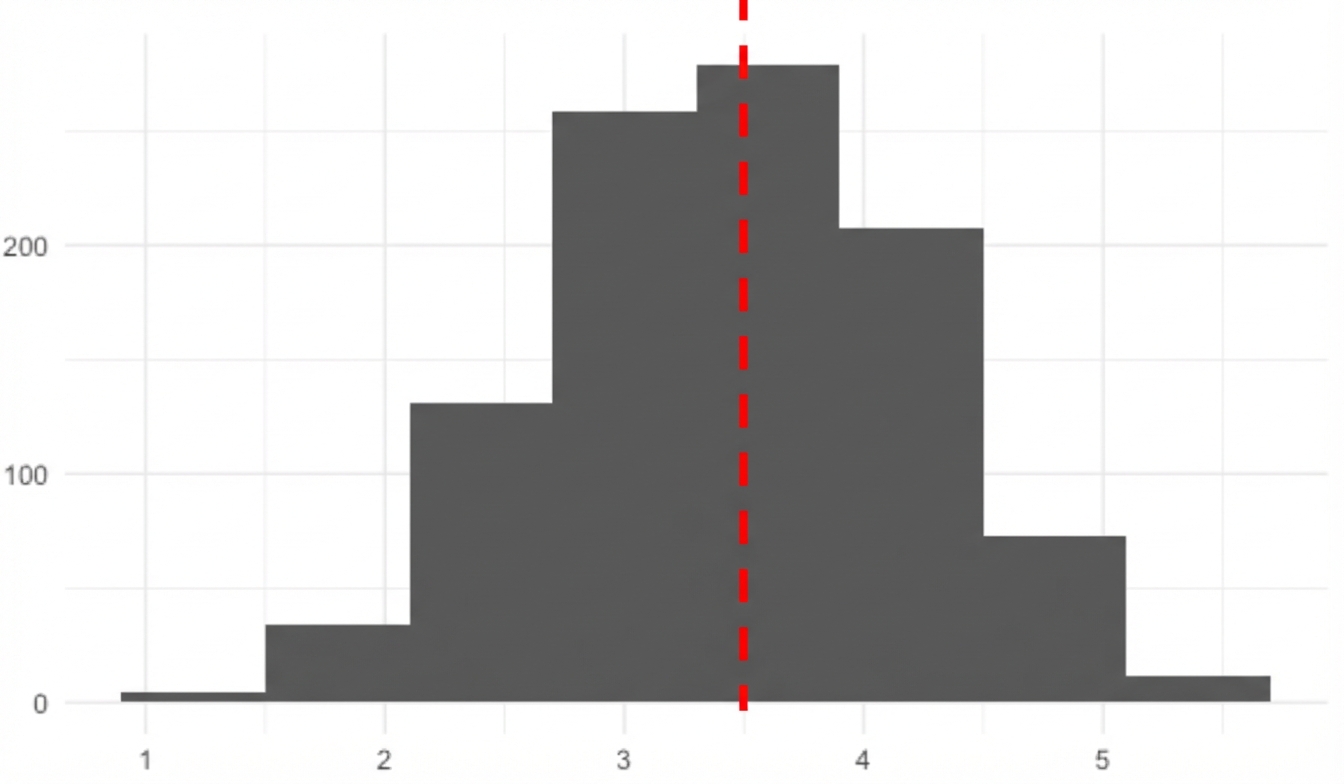
- Einfachere Schätzung von Merkmalen großer Datenmengen

