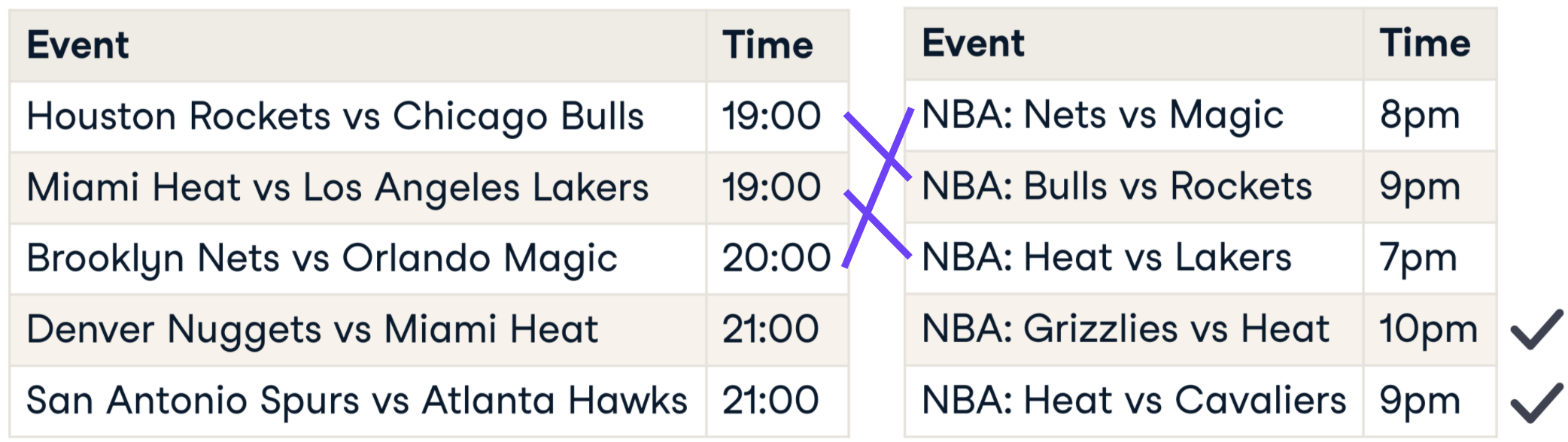
Zeichenketten vergleichen
Datenbereinigung in Python

Adel Nehme
VP of AI Curriculum, DataCamp
Minimale Editierdistanz
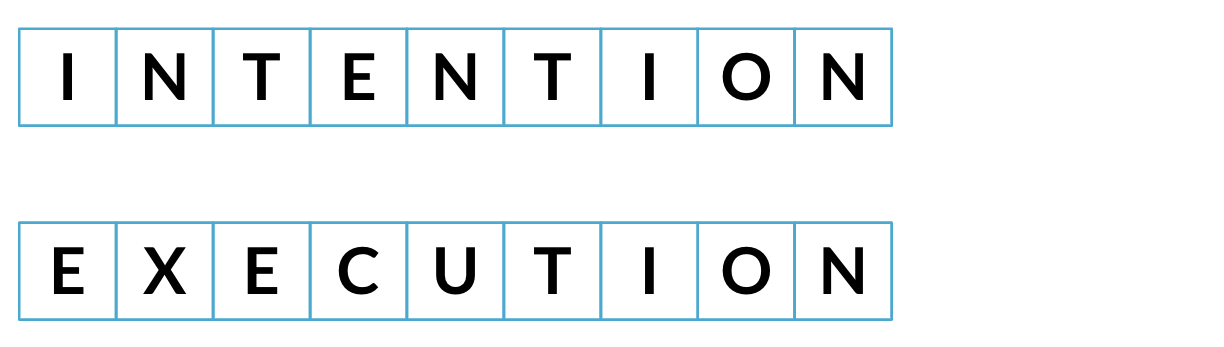
Geringste Anzahl Schritte, um von einer Zeichenfolge zur anderen zu gelangen
Minimale Editierdistanz
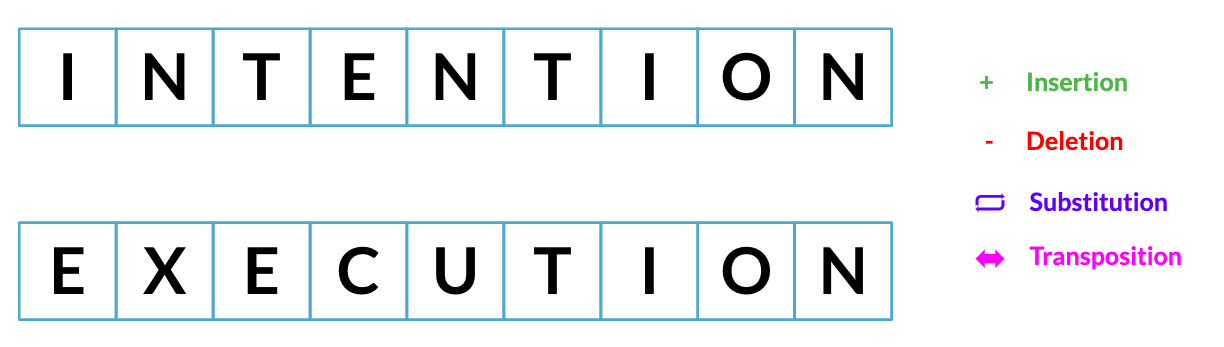
Geringste Anzahl Schritte, um von einer Zeichenfolge zur anderen zu gelangen
Minimale Editierdistanz

Minimale Editierdistanz
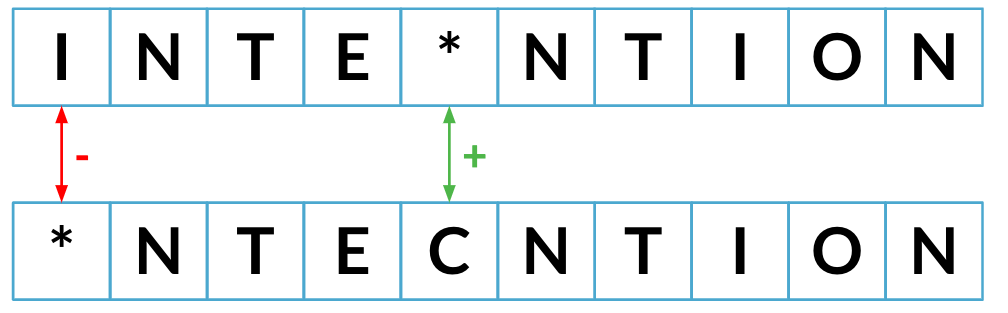
Bisher geringste Editierdistanz: 2
Minimale Editierdistanz
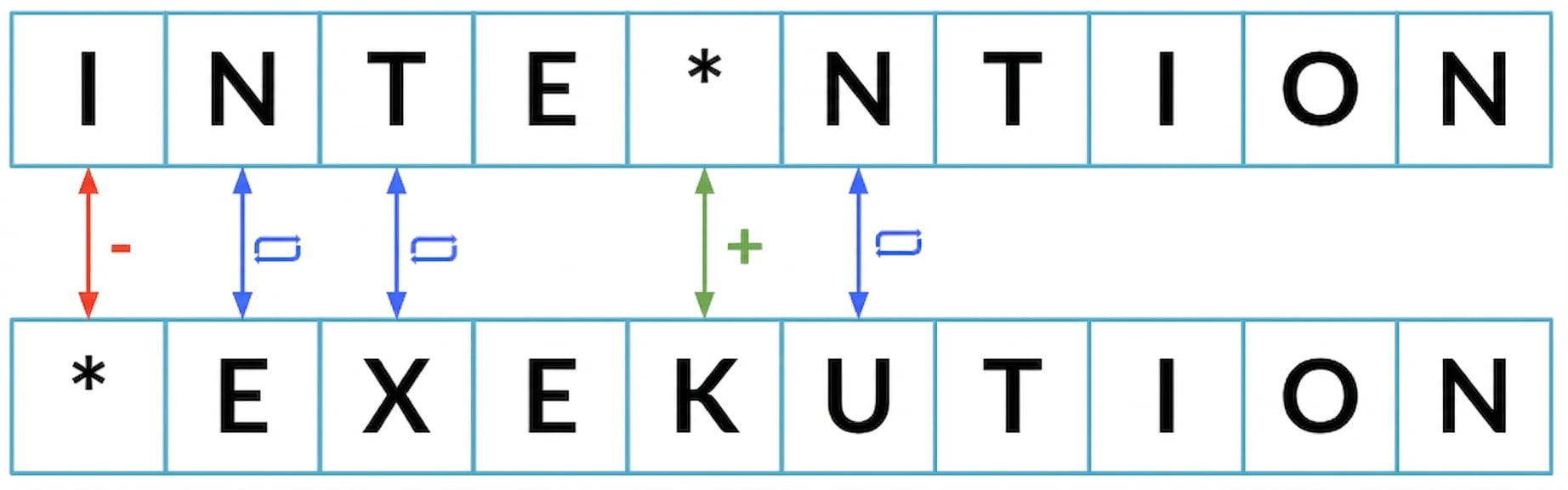
Levenshtein-Distanz (auch minimale Editierdistanz): 5
Minimale Editierdistanz

Record linkage – Datensatzverknüpfung