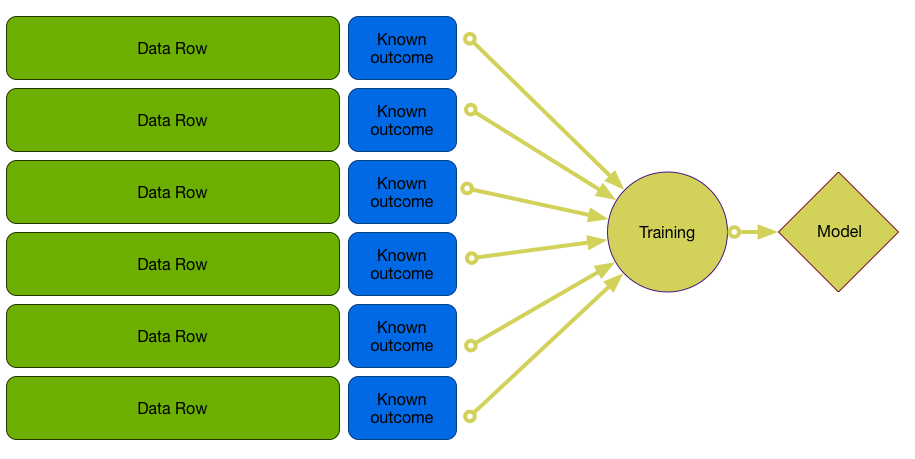
Properly Training a Model
Supervised Learning in R: Regression

Nina Zumel and John Mount
Win-Vector, LLC
Models can perform much better on training than they do on future data.
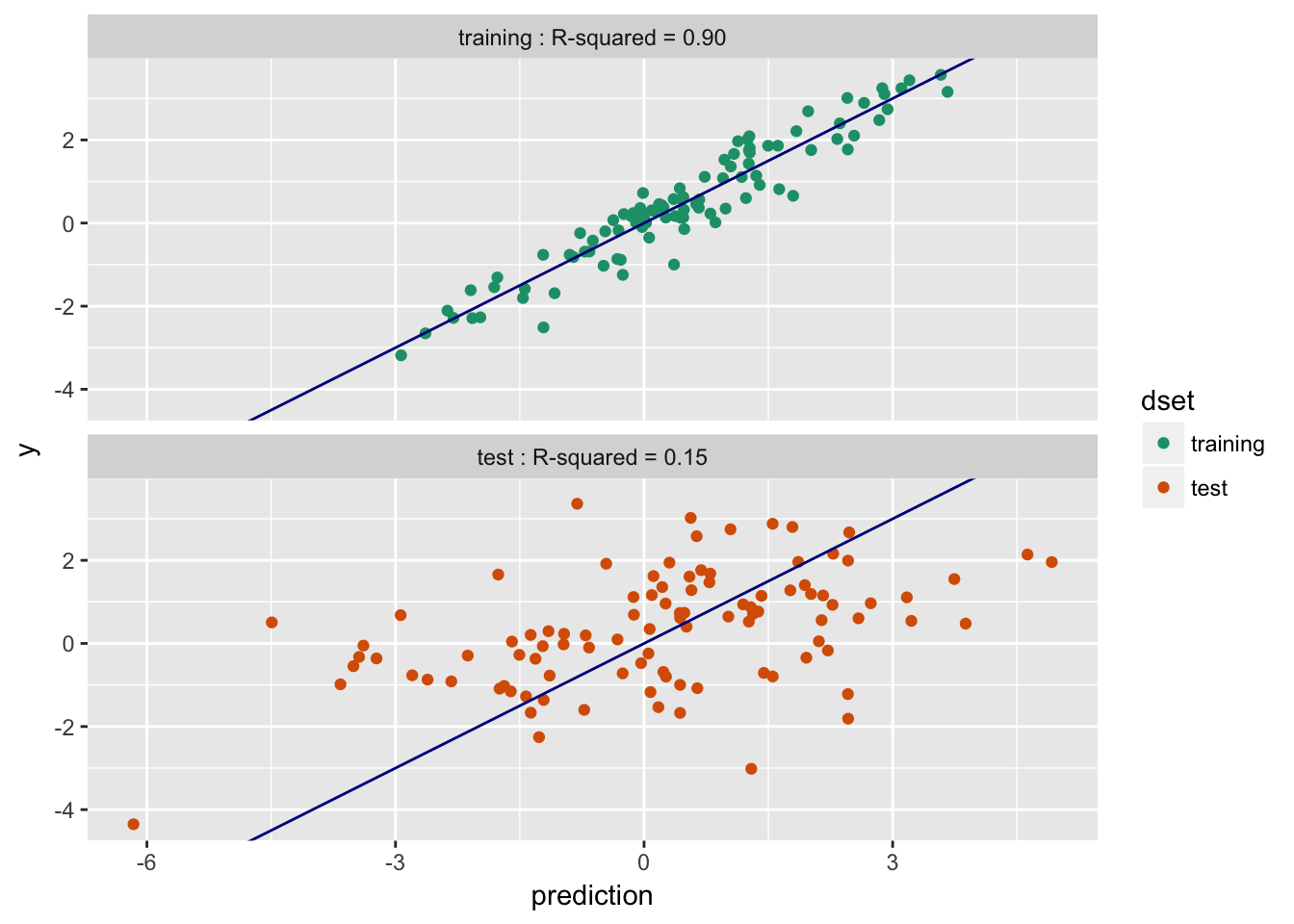
- Training $R^2$: 0.9; Test $R^2$: 0.15 -- Overfit
Test/Train Split
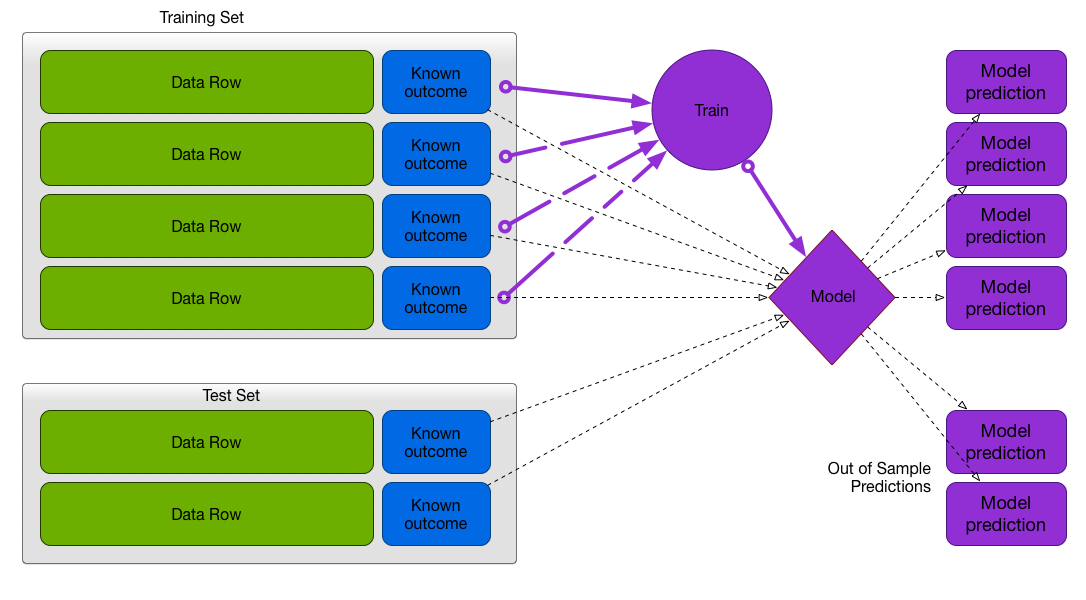
Recommended method when data is plentiful
Example: Model Female Unemployment
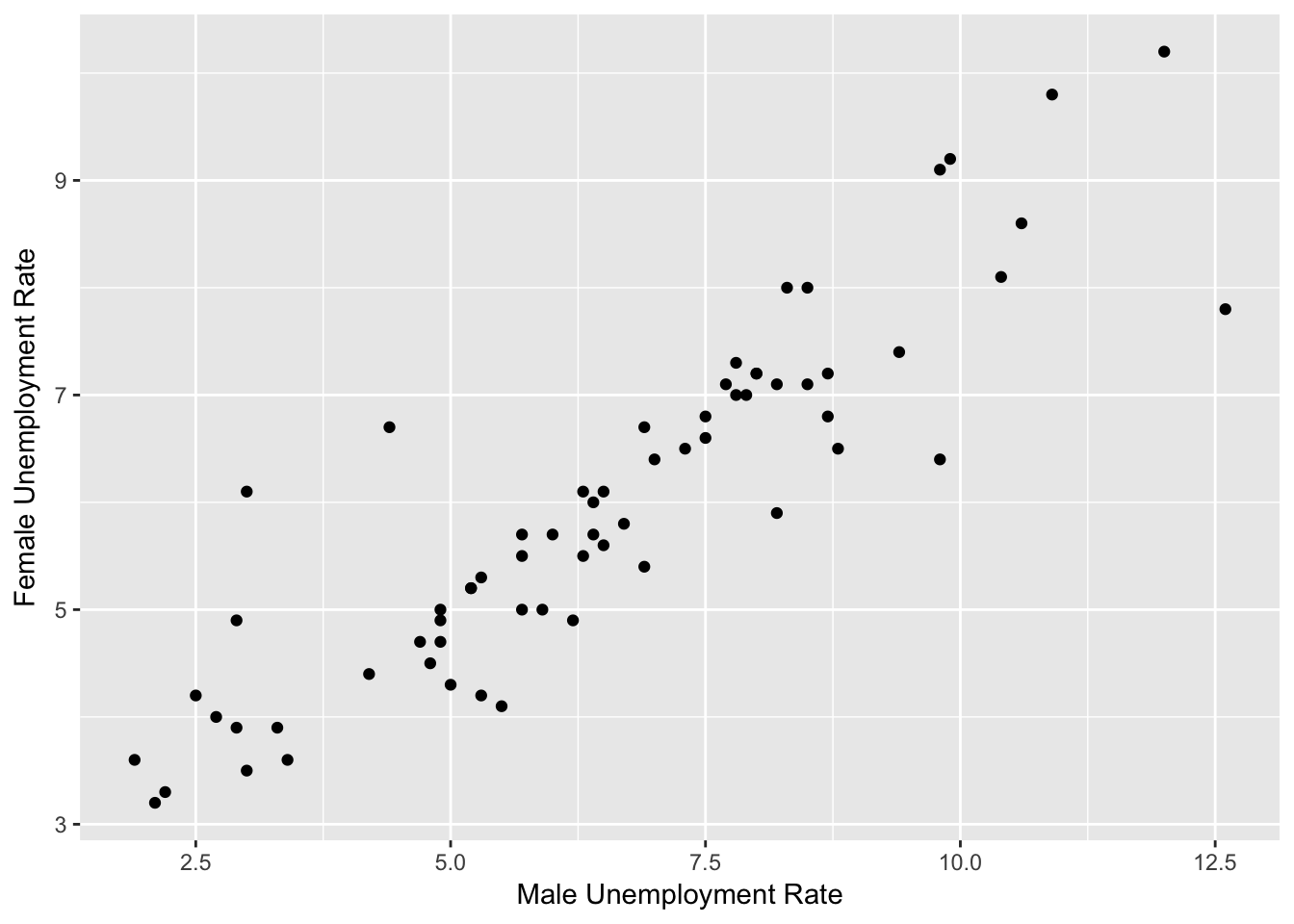
- Train on 66 rows, test on 30 rows
Model Performance: Train vs. Test
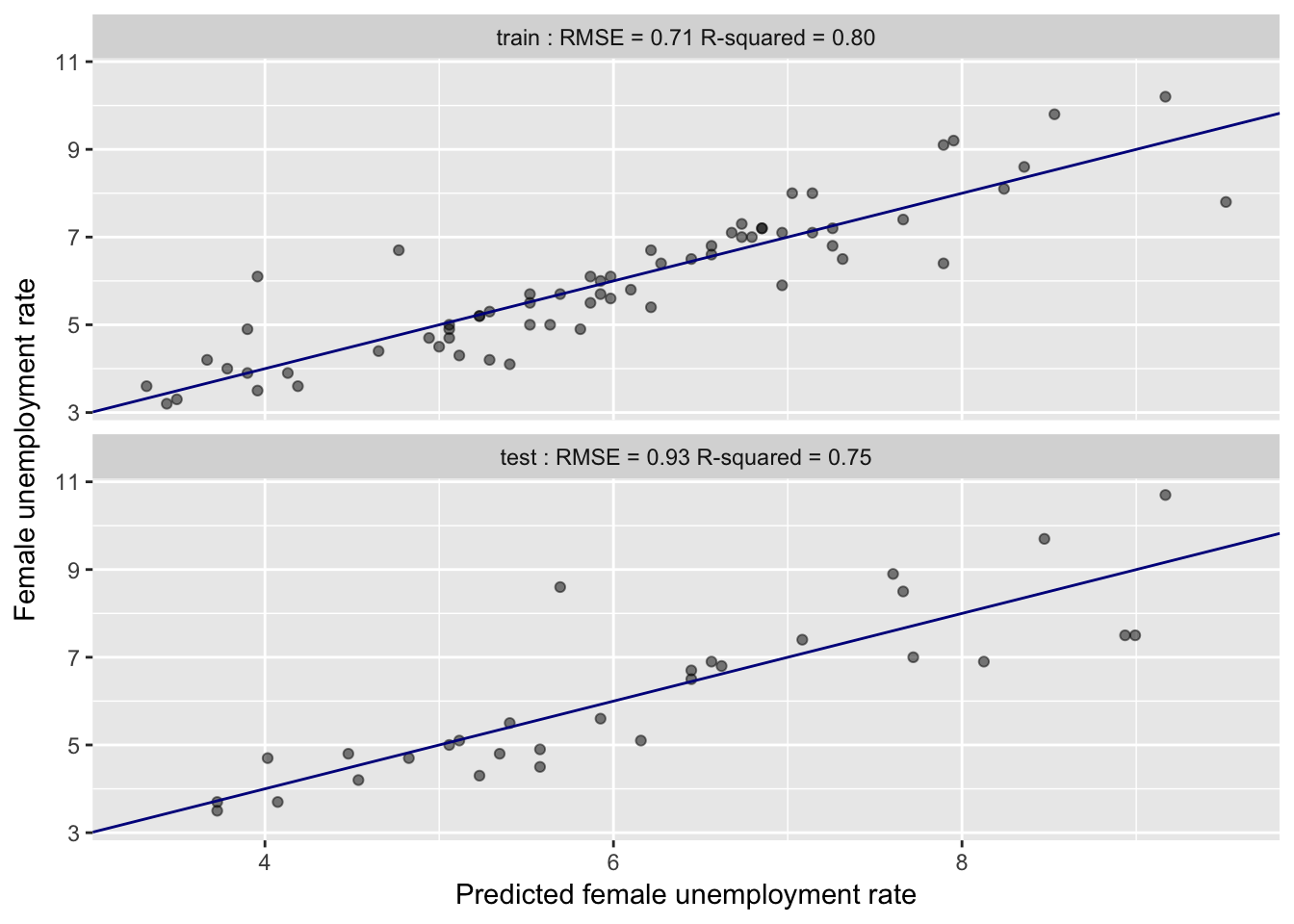
- Training: RMSE 0.71, $R^2$ 0.8
- Test: RMSE 0.93, $R^2$ 0.75
Cross-Validation
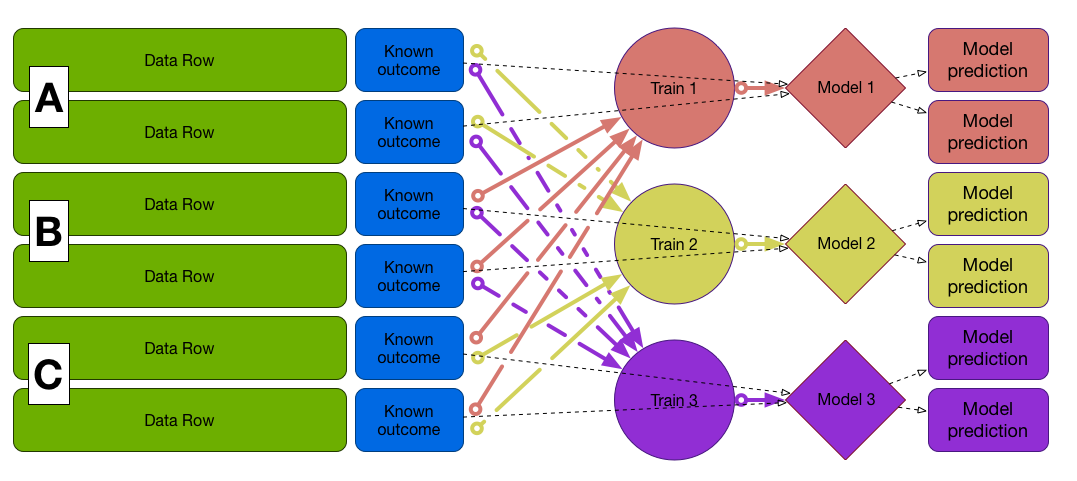
Preferred when data is not large enough to split off a test set
Cross-Validation
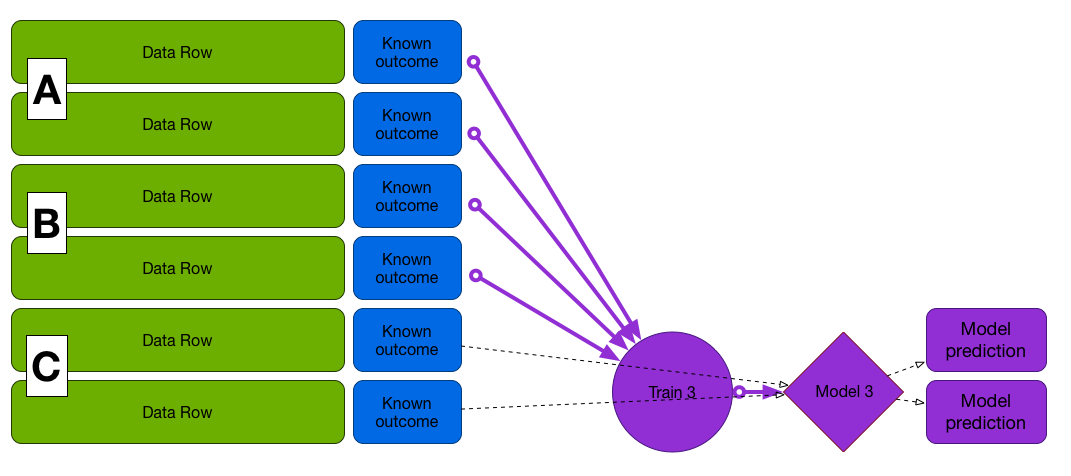
Cross-Validation
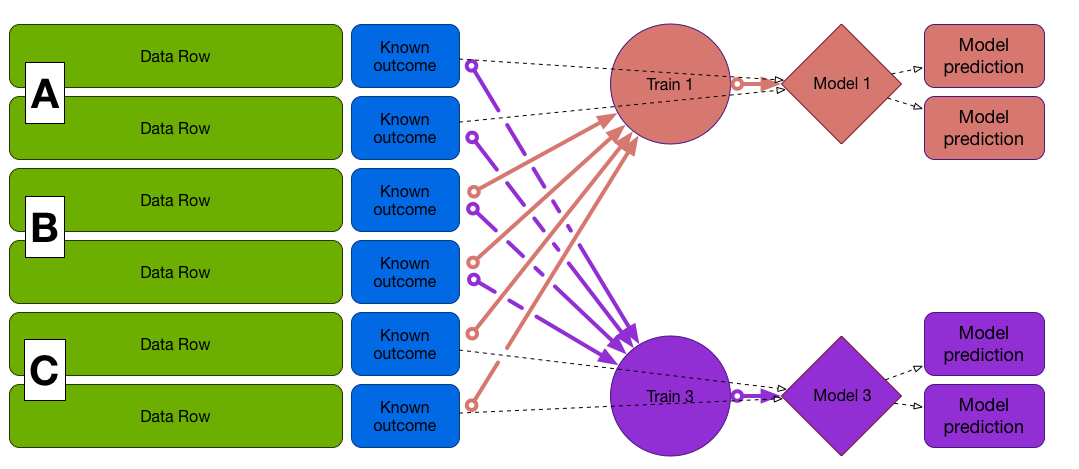
Cross-Validation
Final Model