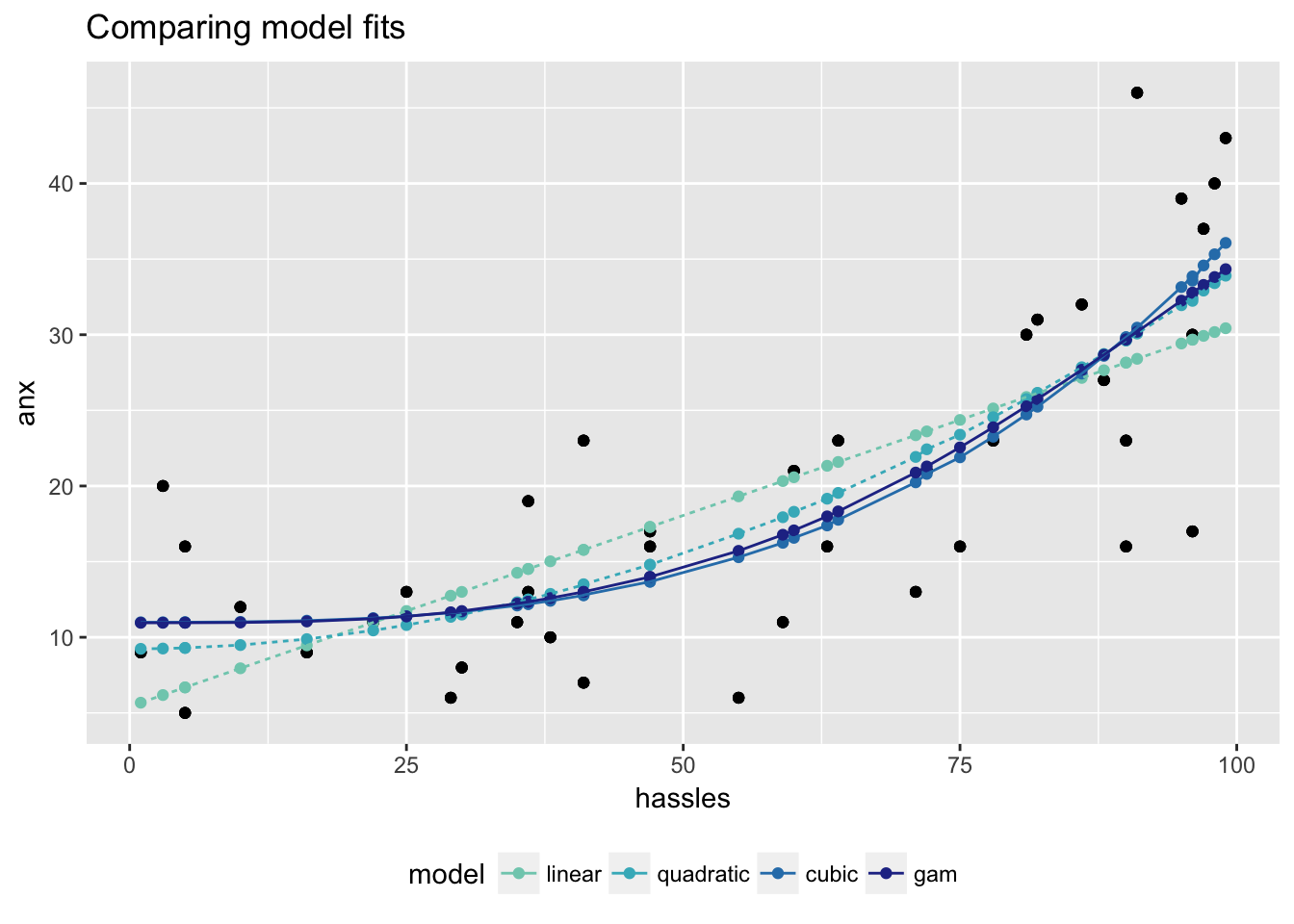
GAM to learn non-linear transformations
Supervised Learning in R: Regression

Nina Zumel and John Mount
Win-Vector, LLC
Learning Non-linear Relationships
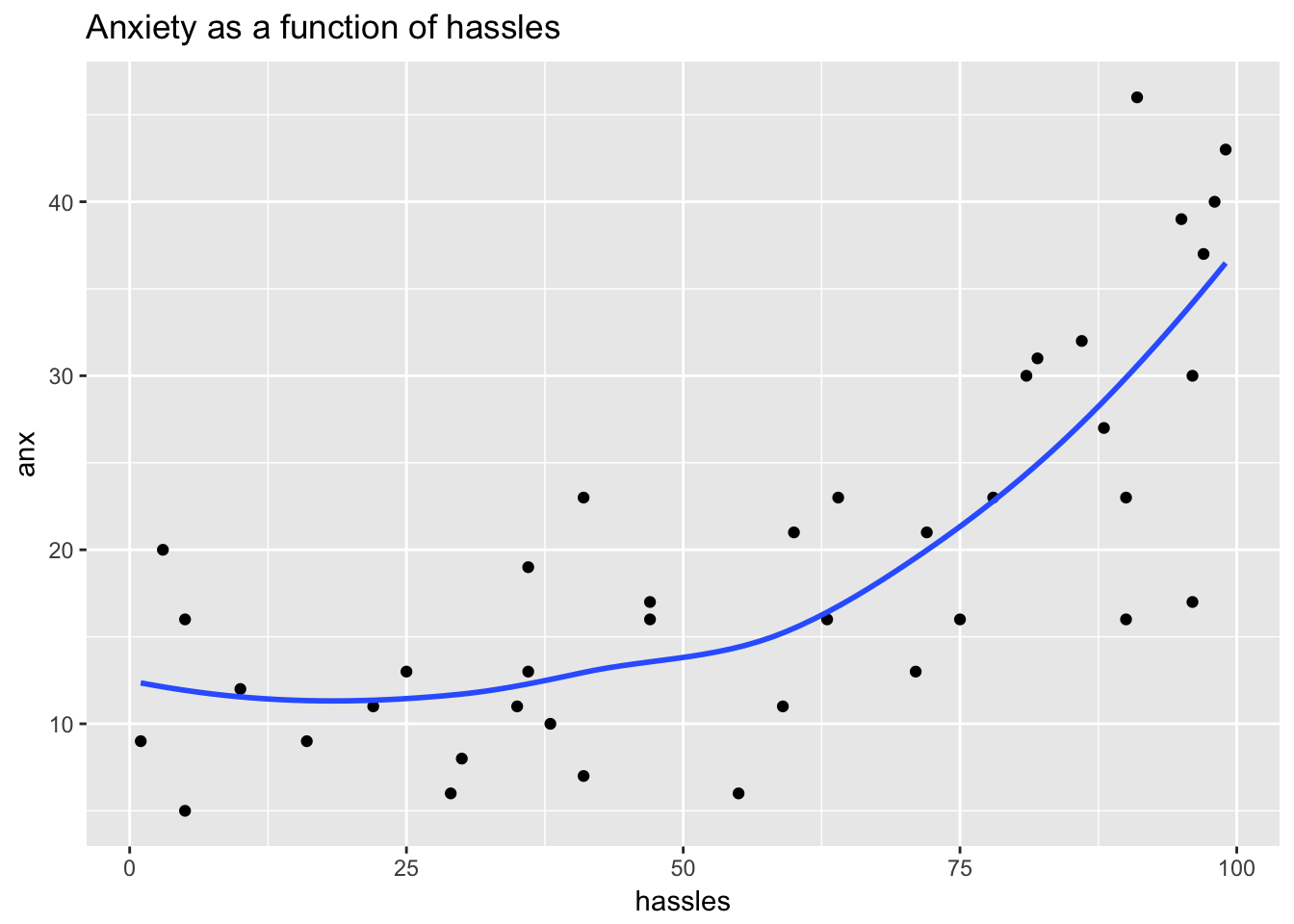
Revisit the hassles data
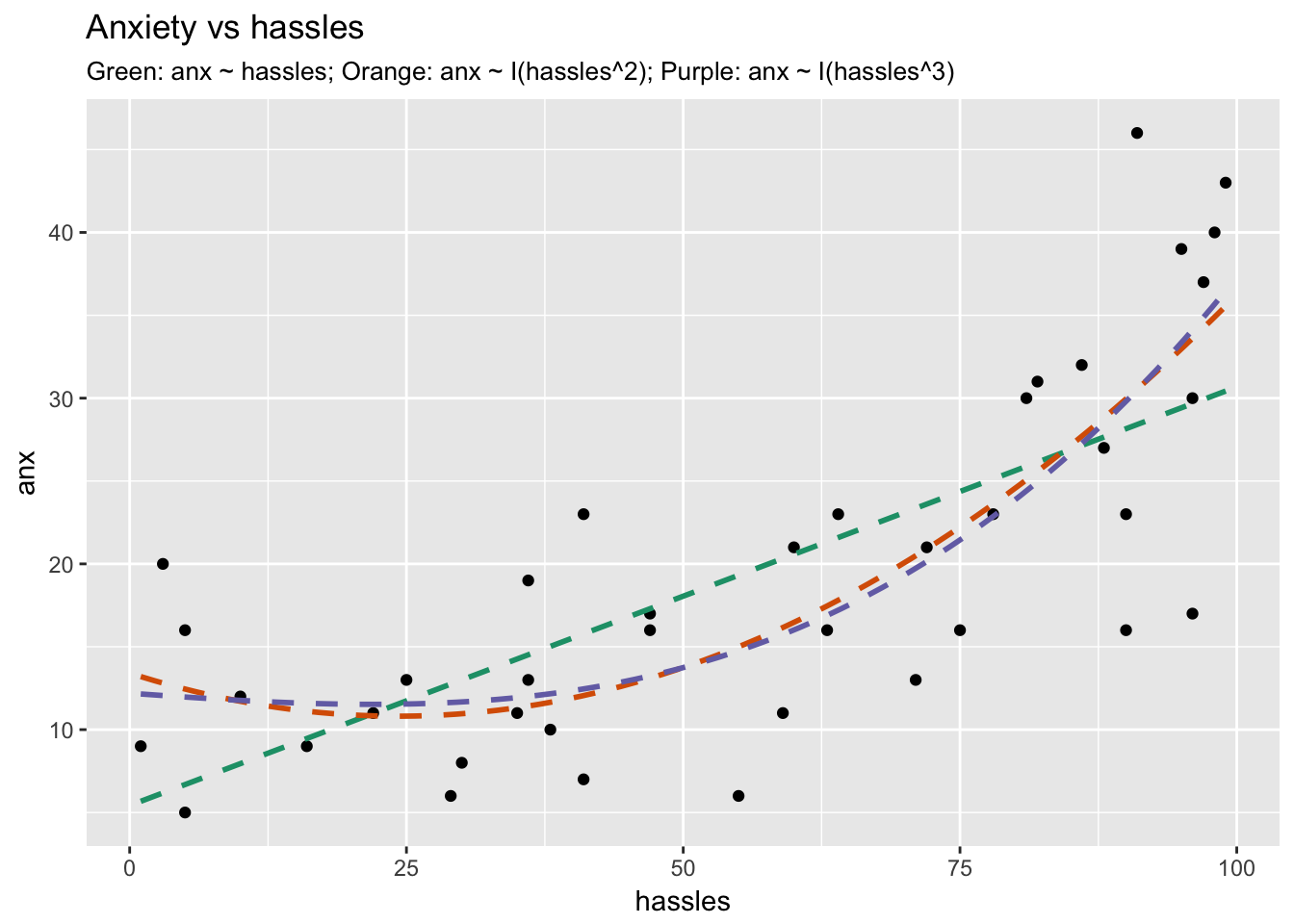
Examining the Transformations
plot(model)
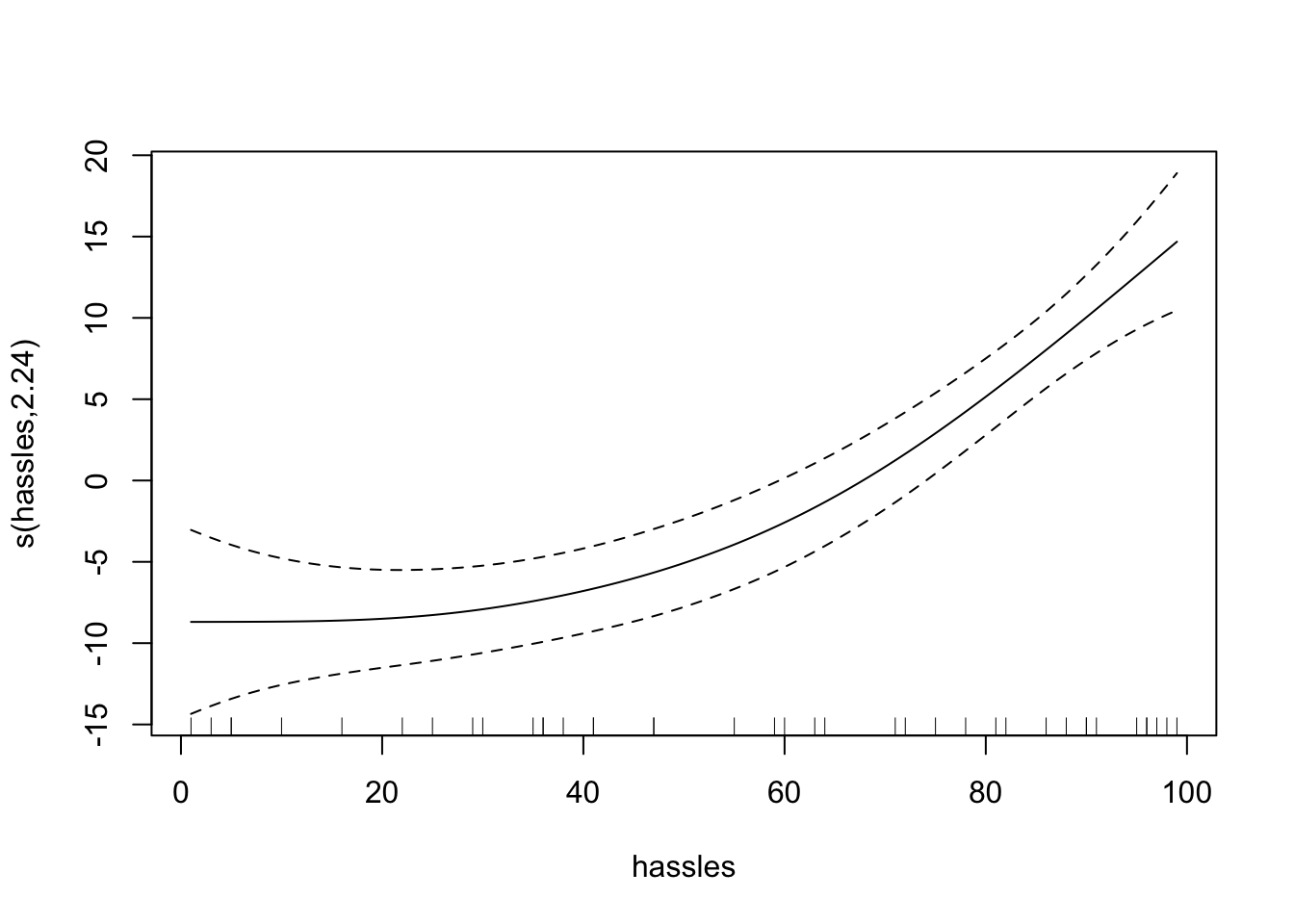
$y$ values: predict(model, type = "terms")
Predicting with the Model
predict(model, newdata = hassleframe, type = "response")