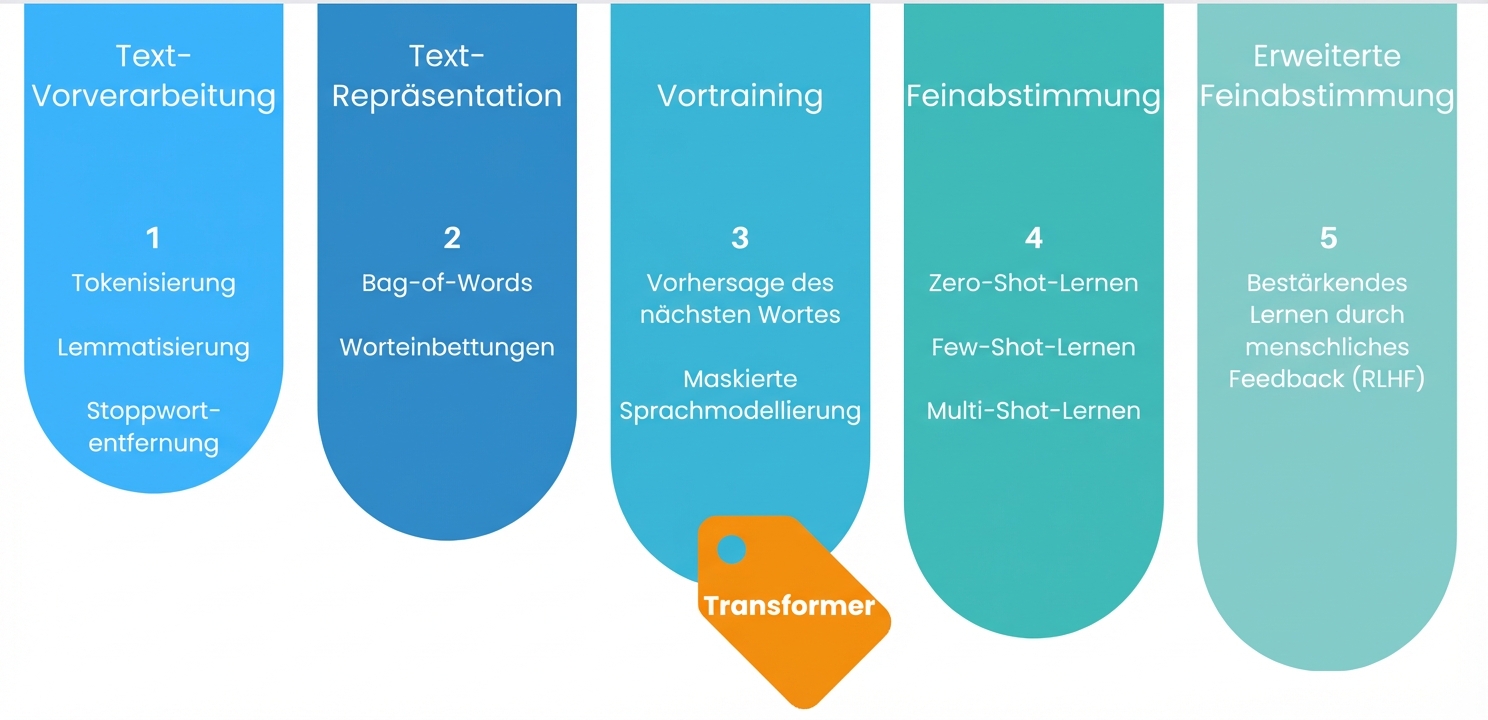
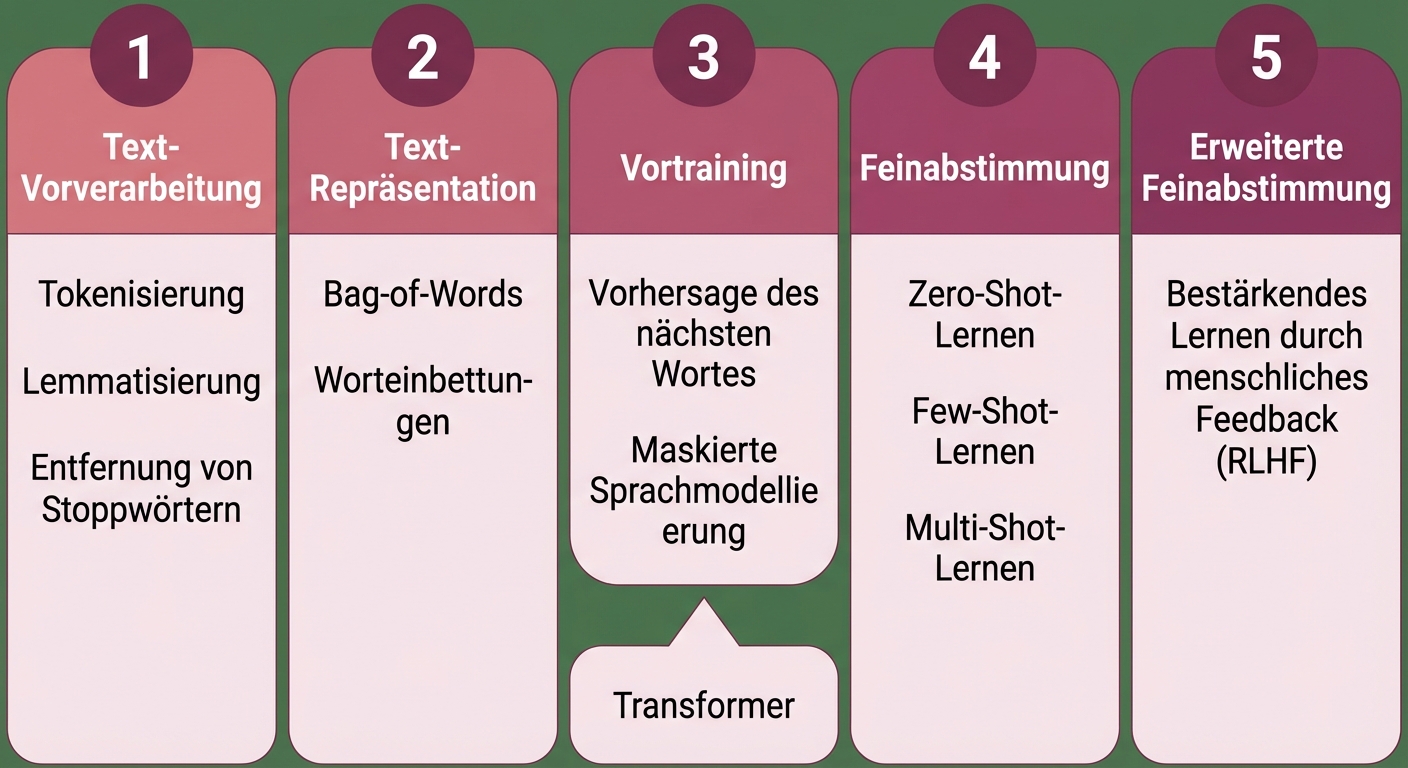
Erweitertes Finetuning
Konzepte großer Sprachmodelle (LLMs)

Vidhi Chugh
AI strategist and ethicist
In welchem Abschnitt befinden wir uns?
Verstärkendes Lernen durch menschliches Feedback

Pre-Training

1 Freepik
Fine-tuning

Weshalb RLHF nutzen?

Vereinfacht: Bestärkendes Lernen durch menschliches Feedback (RLHF)

Der menschlicher Experte betritt den Raum

Zeit für Feedback
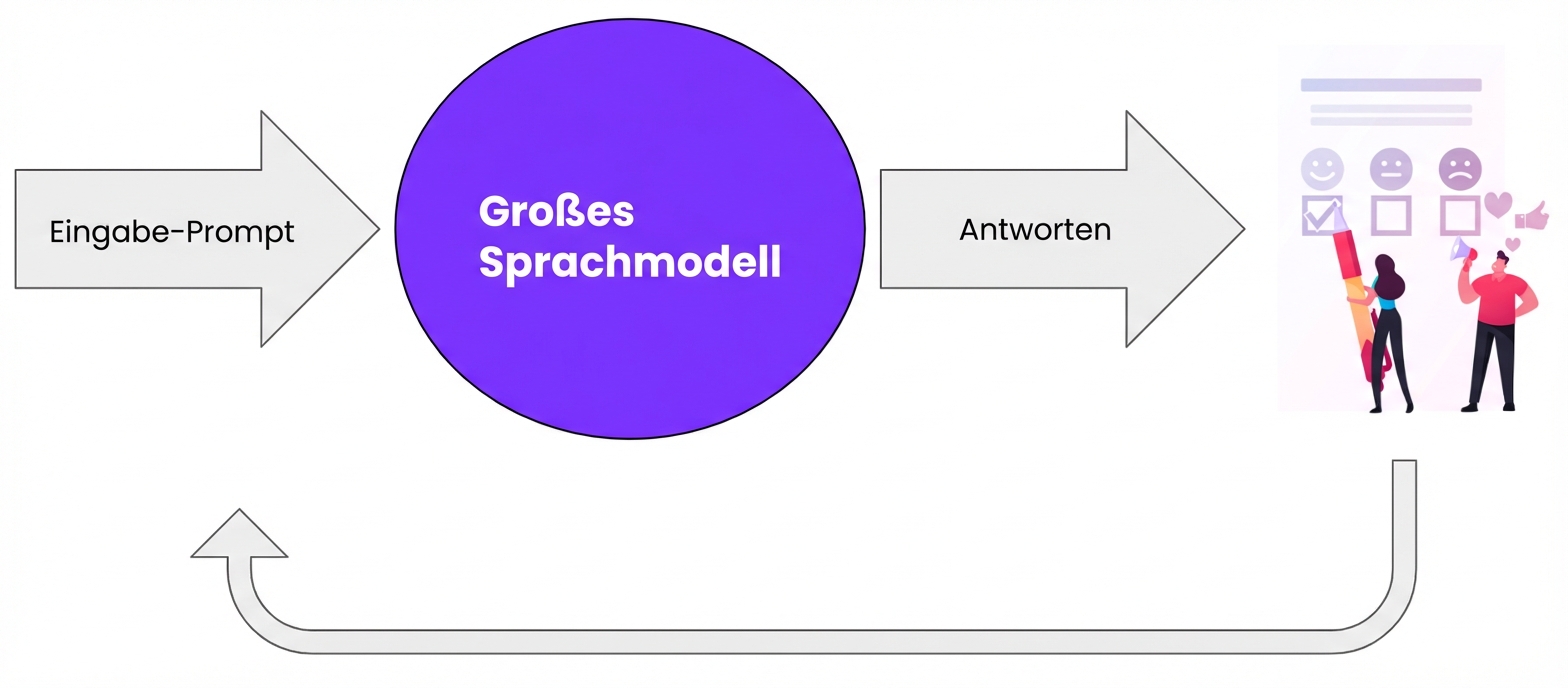
Abschluss des LLM Trainingsprozesses