The "There is only one test" framework
Hypothesis Testing in R

Richie Cotton
Data Evangelist at DataCamp
Imbalanced data
stack_overflow_imbalanced %>%
count(hobbyist, age_cat, .drop = FALSE)
hobbyist age_cat n
1 No At least 30 0
2 No Under 30 191
3 Yes At least 30 15
4 Yes Under 30 1025
A sample is imbalanced if some groups are much bigger than others.
Hypotheses
$H_{0}$: The proportion of hobbyists under 30 is the same as the proportion of hobbyists at least 30.
$H_{A}$: The proportion of hobbyists under 30 is different from the proportion of hobbyists at least 30.
alpha <- 0.1
Proceeding with a proportion test regardless
stack_overflow_imbalanced %>%
prop_test(
hobbyist ~ age_cat,
order = c("At least 30", "Under 30"),
success = "Yes",
alternative = "two.sided",
correct = FALSE
)
# A tibble: 1 x 6
statistic chisq_df p_value alternative lower_ci upper_ci
<dbl> <dbl> <dbl> <chr> <dbl> <dbl>
1 2.79 1 0.0949 two.sided 0.00718 0.0217
A grammar of graphics
| Plot type | base-R | ggplot2 |
|---|---|---|
| Scatter plot | plot(, type = "p") |
ggplot() + geom_point() |
| Line plot | plot(, type = "l") |
ggplot() + geom_line() |
| Histogram | hist() |
ggplot() + geom_histogram() |
| Box plot | boxplot() |
ggplot() + geom_boxplot() |
| Bar plot | barplot() |
ggplot() + geom_bar() |
| Pie plot | pie() |
ggplot() + geom_bar() + coord_polar() |
A grammar of hypothesis tests
- Allen Downey's There is only one test framework.
- Implemented in R in the
inferpackage. generate()makes simulated data.- Computationally expensive.
- Robust against small samples or imbalanced data.
null_distn <- dataset %>%
specify() %>%
hypothesize() %>%
generate() %>%
calculate()
obs_stat <- dataset %>%
specify() %>%
calculate()
get_p_value(null_distn, obs_stat)
1 Allen Downey teaches "Exploratory Data Analysis in Python".
Specifying the variables of interest
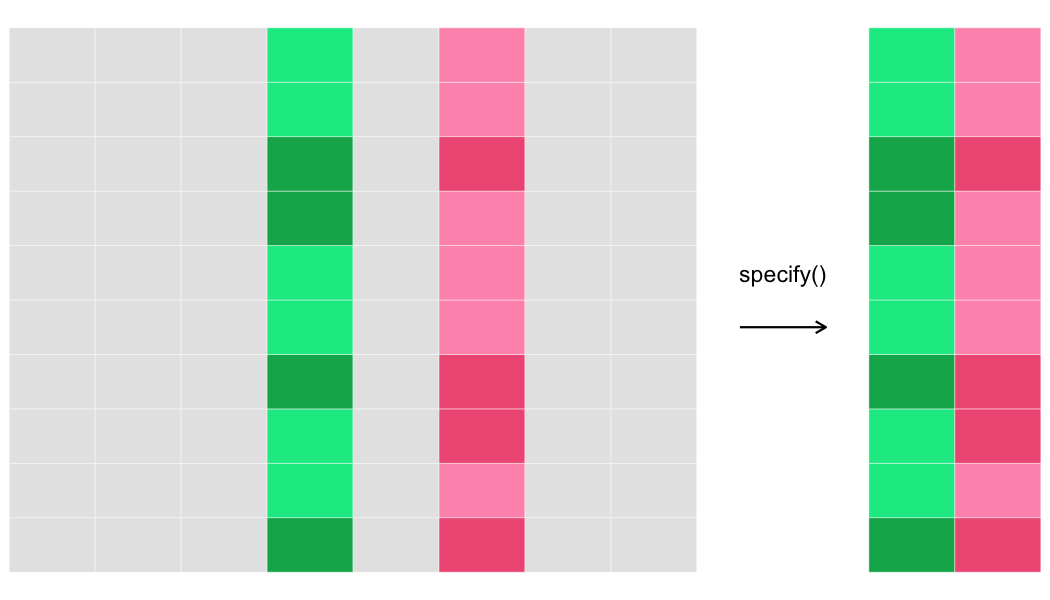
specify()
specify()selects the variable(s) you want to test.
- For 2 sample tests, use
response ~ explanatory. - For 1 sample tests use
response ~ NULL.
stack_overflow_imbalanced %>%
specify(hobbyist ~ age_cat, success = "Yes")
Response: hobbyist (factor)
Explanatory: age_cat (factor)
# A tibble: 1,231 x 2
hobbyist age_cat
<fct> <fct>
1 Yes At least 30
2 Yes At least 30
3 Yes At least 30
4 Yes Under 30
5 Yes At least 30
6 Yes At least 30
7 No Under 30
# ... with 1,224 more rows
hypothesize()
hypothesize()declares the type of null hypothesis.
- For 2 sample tests, use
"independence"or"point". - For 1 sample tests, use
"point".
stack_overflow_imbalanced %>%
specify(hobbyist ~ age_cat, success = "Yes") %>%
hypothesize(null = "independence")
Response: hobbyist (factor)
Explanatory: age_cat (factor)
Null Hypothesis: independence
# A tibble: 1,231 x 2
hobbyist age_cat
<fct> <fct>
1 Yes At least 30
2 Yes At least 30
3 Yes At least 30
4 Yes Under 30
5 Yes At least 30
6 Yes At least 30
7 No Under 30
# ... with 1,224 more rows
Let's practice!
Hypothesis Testing in R

