Summarize categorical variables
Importing and Managing Financial Data in Python

Stefan Jansen
Instructor
Convert IPO Year to int
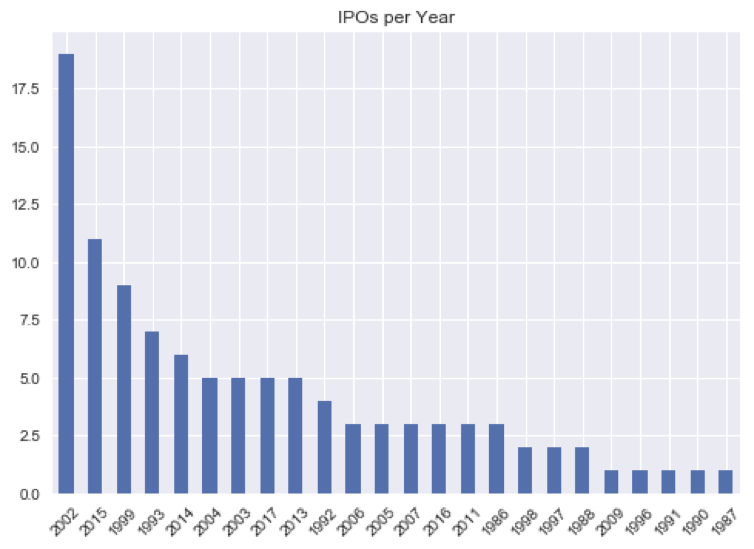
ipo_by_yr.plot(kind='bar', title='IPOs per Year')
plt.xticks(rotation=45)
Importing and Managing Financial Data in Python
Stefan Jansen
Instructor
ipo_by_yr.plot(kind='bar', title='IPOs per Year')
plt.xticks(rotation=45)

